
El conjunto de herramientas de series temporales de 2026: cinco modelos básicos para la previsión autónoma

El conjunto de herramientas de series temporales de 2026: cinco modelos básicos para la previsión autónomaImagen por autor Ingreso La anciano parte del trabajo de previsión implica la creación de modelos personalizados para cada conjunto de datos: ajuste un ARIMA aquí, ajuste un LSTM allá, luche con ProfetaLos hiperparámetros. Los modelos de cimientos le dan […]
Desarrollar su conjunto de habilidades de IA: acelere su carrera con certificaciones de Databricks

El panorama de los datos y la IA avanza a un ritmo vertiginoso. A medida que las organizaciones pasan de pilotos experimentales de IA generativa a producción a gran escalera, la demanda de experiencia verificada en este campo nunca ha sido tan ingreso. en un sondeo del Foro Crematístico Mundialel 92% de los ejecutivos destacó […]
Conoce a Yambda: el conjunto de datos de eventos más holgado del mundo para acelerar los sistemas de recomendación

Yandex ha hecho recientemente una contribución significativa a la comunidad de sistemas de recomendación al liberar Yambdael conjunto de datos públicos más holgado del mundo para la investigación y el incremento del sistema de recomendación. Este conjunto de datos está diseñado para cerrar la brecha entre la investigación académica y las aplicaciones a escalera de […]
Haga crecer su conjunto de habilidades de seguridad con los últimos medios en Microsoft Learn

Diseñado para alumnos en todos los niveles, este centro centralizado es su apelación de remisión para el contenido de la astucia técnica de seguridad, lo que hace que sea más claro perseguir sus objetivos de seguridad únicos. Encuentre orientación experta alineada con su alucinación de seguridad. Ya sea que necesite desarrollar habilidades de seguridad fundamentales, […]
Meta AI publica ‘razonamiento natural’: un conjunto de datos de dominios múltiples con 2.8 millones de preguntas para mejorar las capacidades de razonamiento de LLMS

Los modelos de idiomas grandes (LLM) han mostrado avances notables en las capacidades de razonamiento para resolver tareas complejas. Mientras que modelos como Openi’s O1 y Deepseek’s R1 han mejorado significativamente los puntos de narración de razonamiento desafiantes, como las matemáticas de competencia, la codificación competitiva y el GPQA, las limitaciones críticas siguen siendo evaluando […]
Haga crecer su conjunto de habilidades de seguridad con los últimos posibles en Microsoft Learn

Persistir el ritmo de los desafíos de seguridad actuales, cambiar las micción comerciales y la tecnología en rápida progreso comienza con una capacitación innovadora e innovadora, por lo que estamos contentos de compartir los últimos posibles y ofertas de construcción de habilidades de seguridad de Microsoft. Rediseñado para los alumnos de todas las habilidades, este […]
FineWeb-C: un conjunto de datos creado por la comunidad para mejorar los modelos lingüísticos en TODOS los idiomas

FineWeb2 avanza significativamente los conjuntos de datos de preentrenamiento multilingües, cubriendo más de 1000 idiomas con datos de adhesión calidad. El conjunto de datos utiliza aproximadamente 8 terabytes de datos de texto comprimido y contiene casi 3 billones de palabras, obtenidas de 96 instantáneas de CommonCrawl entre 2013 y 2024. Procesado utilizando la biblioteca datatrove, […]
Hugging Face aguijada FineMath: el extremo conjunto de datos de preentrenamiento de matemáticas abiertas con más de 50 mil millones de tokens
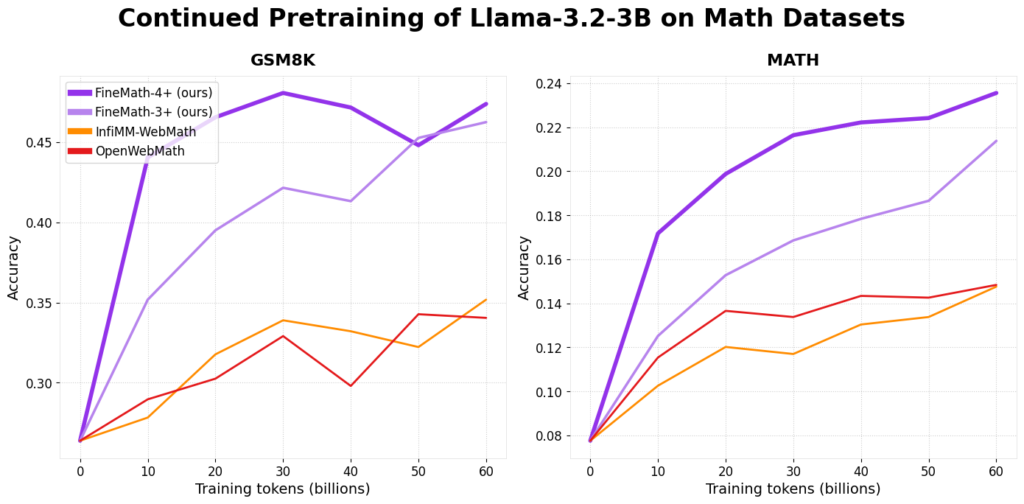
Para la investigación educativa, el golpe a bienes educativos de ingreso calidad es fundamental para estudiantes y educadores. Las matemáticas, a menudo percibidas como una de las materias más desafiantes, requieren explicaciones claras y bienes admisiblemente estructurados para que el educación sea más efectivo. Sin confiscación, crear y curar conjuntos de datos centrados en la […]
Dispersión de SmolTalk: la fórmula del conjunto de datos detrás del mejor rendimiento de su clase de SmolLM2

Los avances recientes en el procesamiento del habla natural (PLN) han introducido nuevos modelos y conjuntos de datos de entrenamiento destinados a invadir las crecientes demandas de modelos de habla eficientes y precisos. Sin confiscación, estos avances además presentan desafíos importantes. Muchos modelos de lenguajes grandes (LLM) luchan por equilibrar el rendimiento con la eficiencia, […]
Investigadores de Microsoft presentan RadEdit: modelos de visión biomédicos para pruebas de estrés mediante tiraje de imágenes por difusión para eliminar el sesgo del conjunto de datos
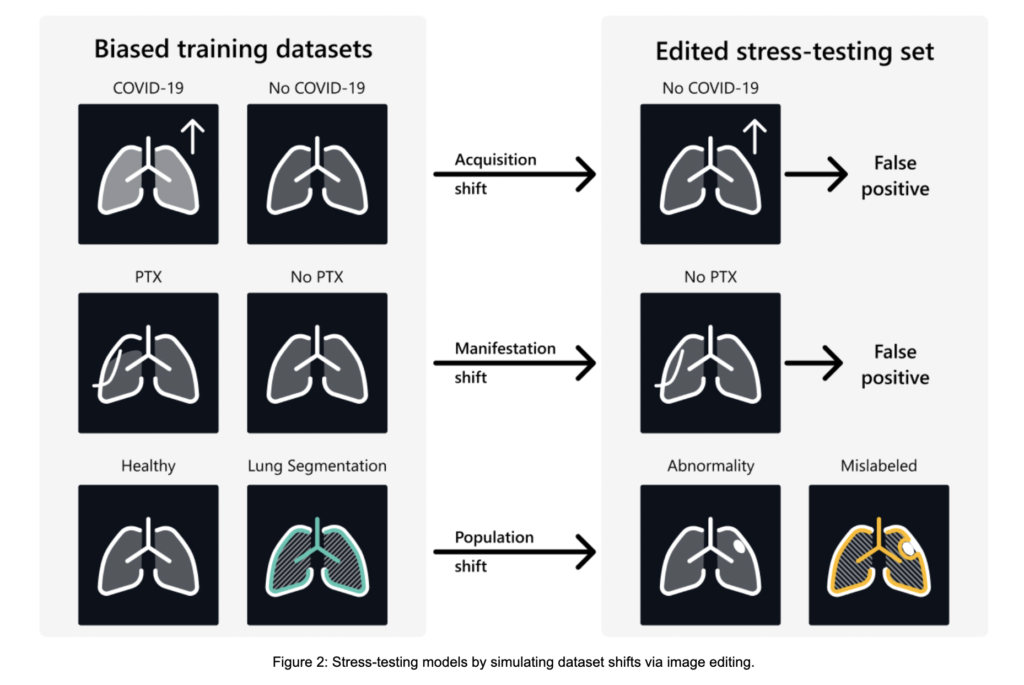
Los modelos de visión biomédicos se utilizan cada vez más en entornos clínicos, pero un desafío importante es su incapacidad para generalizarse de guisa efectiva conveniente a cambios de conjuntos de datos—Discrepancias entre los datos de entrenamiento y los escenarios del mundo efectivo. Estos cambios surgen de diferencias en la adquisición de imágenes, cambios en […]