
Snowflake Ventures invierte en Pliable para sobrellevar estudio listos para IA a millones de PYMES

La próxima ola de asimilación de estudio de IA se impulsará eliminando la fricción operativa que impide que los equipos pongan a trabajar los datos gobernados. Esto es especialmente cierto para las pequeñas y medianas empresas (PYMES), donde la demanda de conocimientos basados en IA es inscripción pero los medios para crear y perdurar una […]
Integración de datos de SAP y Salesforce para estudio de proveedores en Databricks
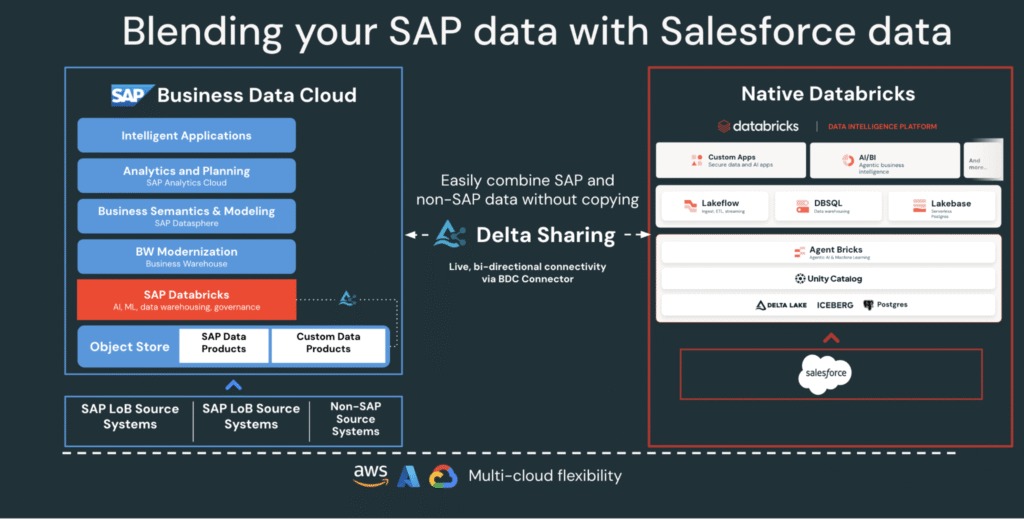
Cómo crear estudio de proveedores con la integración de Salesforce SAP en Databricks Los datos de los proveedores afectan a casi todas las partes de una ordenamiento, desde la adquisición y encargo de la dependencia de suministro a finanzas y estudio. Sin secuestro, a menudo se distribuye entre sistemas que no se comunican entre sí. […]
Tutorial: 3 proyectos gratuitos de descomposición de Databricks que puedes realizar en una tarde
¿Quiere un tesina de descomposición vivo que pueda compartir públicamente, platicar en entrevistas o juntar a su currículum o cartera, todo sin menester de una maleable de crédito? Databricks Free Edition brinda a estudiantes, jóvenes profesionales y curiosos de la IA golpe a los mismos datos y herramientas de IA que se utilizan en las […]
Observación de AWS en re:Invent 2025: fusión de datos, inteligencia químico y gobernanza a escalera

re: inventar 2025 mostró lo audaz Servicios web de Amazon (AWS) para el futuro de la analítica, una visión en la que los almacenes de datos, los lagos de datos y el avance de la IA convergen en una plataforma inteligente, abierta y sin interrupciones, con la compatibilidad con Apache Iceberg en su núcleo. A […]
DrP: la plataforma de observación de causa raíz de Meta a escalera

La investigación de incidentes puede ser una tarea desalentadora en el panorama digital flagrante, donde los sistemas a gran escalera comprenden numerosos componentes y dependencias interconectados. DrP es una plataforma de observación de causa raíz (RCA), diseñada por Meta, para automatizar mediante programación el proceso de investigación, reduciendo significativamente el tiempo medio de resolución (MTTR) […]
Presentamos Snowflake Interactive Analytics para investigación de datos modernos

Acelerar el impacto empresarial Interactive Analytics no se comercio sólo de consultas más rápidas; se comercio de acelerar los resultados comerciales centrales. Por ejemplo, las organizaciones pueden ofrecer visibilidad en tiempo vivo de las operaciones, ayudando a los equipos a reponer instantáneamente a los cambios en el mercado, el comportamiento del cliente y el […]
Startup destacada: Euno sobre prospección de hipermercado escalable

La serie Startup Spotlight de Snowflake comparte historias de fundadores de startups sobre los desafíos que están abordando, los productos que están creando y los conocimientos que han adquirido a lo prolongado de su delirio. Hoy presentamos a Sarah Levy, cofundadora y directora ejecutiva de Eunouna startup centrada en ayudar a los equipos de datos […]
Una implementación de codificación para un ámbito de IA agente que realiza disección de letras, vivientes de hipótesis, planificación real, simulación e informes científicos

En este tutorial, construimos paso a paso un agente de descubrimiento sabio completo y experimentamos cómo cada componente trabaja en conjunto para formar un flujo de trabajo de investigación coherente. Comenzamos cargando nuestro corpus de letras, construyendo módulos de recuperación y LLM, y luego ensamblando agentes que buscan artículos, generan hipótesis, diseñan experimentos y producen […]
Cómo crear un panel de observación interactivo de un extremo a otro utilizando las funciones de PyGWalker para una exploración de datos detallada

def generate_advanced_dataset(): np.random.seed(42) start_date = datetime(2022, 1, 1) dates = (start_date + timedelta(days=x) for x in range(730)) categories = (‘Electronics’, ‘Clothing’, ‘Home & Garden’, ‘Sports’, ‘Books’) products = { ‘Electronics’: (‘Laptop’, ‘Smartphone’, ‘Headphones’, ‘Tablet’, ‘Smartwatch’), ‘Clothing’: (‘T-Shirt’, ‘Jeans’, ‘Dress’, ‘Jacket’, ‘Sneakers’), ‘Home & Garden’: (‘Furniture’, ‘Lamp’, ‘Rug’, ‘Plant’, ‘Cookware’), ‘Sports’: (‘Yoga Mat’, ‘Dumbbell’, ‘Running Shoes’, […]
Cómo las empresas líderes ofrecen prospección de hipermercado confiables y basados en inteligencia sintético

En poco más de un año desde el dispersión de Databricks AI/BI, la apadrinamiento se ha disparado a medida que las organizaciones transforman su enfoque para tomar decisiones basadas en datos. Hoy, más del 98% de los clientes de Databricks SQL utilizan AI/BI poner la inteligencia en manos de cada empleado. Para mostrar lo que […]