
Hoy en día, es difícil encontrar una revista de negocios, una convocatoria de resultados trimestrales, un noticia técnico de la industria o una presentación de táctica sobre la transformación empresarial que no esté centrada en la Inteligencia Industrial (IA). La IA moderna representa un cambio fundamental en la forma en que las organizaciones abordan el consumo, la interpretación y la coexistentes de contenido, lo que permite a las empresas aumentar y automatizar una amplia abanico de tareas que ayer requerían una gran experiencia y primaveras de conocimiento especializado.
Pero a pesar de toda la atención que ha atraído la capacidad de la IA para comprender y producir contenido no estructurado, es aseverar, textos, imágenes, audios, etc.muchos, muchos procesos de negocio centrales han dependido durante mucho tiempo del formación automotriz (ML) clásico, una tecnología diferente aunque relacionada, que produce etiquetas predictivas a partir de entradas de datos estructurados (Figura 1). Hasta ahora, el poder transformador de la IA ha dejado al ML clásico prácticamente sin cambios.
La persistencia de los flujos de trabajo de ML tradicionales se debe a su complejidad e intensidad de trabajo inherentes. Los científicos de datos asiduamente dedican más del 80% de su tiempo a actividades que ocurren incluso ayer de que comience el entrenamiento del maniquí: preparar y validar entradas de datos estructurados, características de ingeniería y clasificar la clase de maniquí correcta. Adicionalmente, a medida que las distribuciones de datos subyacentes cambian y el rendimiento del maniquí se degrada con el tiempo, este trabajo no es una inversión única sino un ciclo continuo de monitoreo, depuración y reentrenamiento.
A escalera, este desafío se intensifica. Las organizaciones que implementan cientos, si no miles, de modelos de formación automotriz dependen de marcos de experimentación automatizados para evaluar miles de combinaciones de parámetros. Pero ni siquiera la automatización puede aventajar las limitaciones fundamentales de posibles.
La verdad es cruda: las empresas deben nominar qué modelos reciben atención de optimización y cuáles funcionan «suficientemente admisiblemente» dados los posibles limitados y la pobreza de mejorar los resultados comerciales rápidamente. Pero la aparición de nuevos modelos de IA centrados en entradas de datos estructurados y expectativas predictivas puede finalmente ofrecer un camino a seguir.
Video 1. Interactuando con el maniquí TabPFN como parte del acelerador de soluciones Databricks
Presentamos TabPFN, un maniquí de inteligencia químico para formación automotriz
Uno de los desarrollos más prometedores en este espacio es PestañaPFNun maniquí elemental (IA) de Laboratorios anteriores que reinventa fundamentalmente el flujo de trabajo del formación automotriz (ML) para datos estructurados. A diferencia de los enfoques tradicionales de ML que requieren crear y entrenar un maniquí único para cada tarea de predicción, TabPFN aplica el mismo ideal «pre-entrenado y preparado para usar» de los LLM a los datos comerciales tabulares. El maniquí fue entrenado previamente en más de 130 millones de conjuntos de datos sintéticos, lo que efectivamente «aprendió a educarse» a partir de datos estructurados en prácticamente cualquier dominio o caso de uso (Figura 1).
Colapsando la trayecto de tiempo de ML
Las implicaciones para la productividad del ML son dramáticas. Mientras que los enfoques tradicionales requieren que los científicos de datos inviertan horas o días en la preparación de datos, ingeniería de características, selección de modelos y ajuste de hiperparámetros, TabPFN ofrece predicciones de nivel de producción en un solo paso en torno a delante, generalmente medido en segundos.
El maniquí maneja entradas sin procesar directamente, administrando automáticamente títulos faltantes, tipos de datos mixtos, características categóricas y de texto, y títulos atípicos sin requerir el preprocesamiento extenso que normalmente consume la veterano parte del esfuerzo de la ciencia de datos. Quizás lo más significativo es que TabPFN elimina la carga de mantenimiento continuo del reentrenamiento del maniquí: a medida que hay nuevos datos disponibles, las organizaciones simplemente actualizan el contexto del maniquí en oportunidad de iniciar un nuevo ciclo de entrenamiento.
Rendimiento sin compensaciones
TabPFN supera la precisión de los métodos tradicionales que requieren horas de ajuste automatizado. Este perfil de desempeño altera fundamentalmente la crematística descrita anteriormente: las organizaciones ya no enfrentan una opción binaria entre la precisión del maniquí y la asignación de posibles. En cambio, pueden implementar rápidamente capacidades predictivas en una abanico más amplia de casos de uso sin subir proporcionalmente sus equipos de ciencia de datos, democratizando el formación automotriz más allá del puñado de aplicaciones de veterano valencia que normalmente justifican esfuerzos de optimización dedicados (Figura 2).
Ampliar el impacto de la IA a la predicción estructurada
TabPFN actualmente admite conjuntos de datos de hasta 100.000 filas y 2.000 funciones, con versiones empresariales extendiéndose a 10 millones de filas, cubriendo la gran mayoría de los casos de uso eficaz de ML en el comercio minorista, las finanzas, la atención médica, la fabricación y otras industrias. Para las organizaciones que buscan operacionalizar la IA más allá de la coexistentes de contenido y las tareas de habla natural, los modelos básicos como TabPFN representan la habitación que desidia, aportando las mismas mejoras de productividad de funciones escalonadas a los datos estructurados y el descomposición predictivo que durante mucho tiempo han formado la columna vertebral de la toma de decisiones basada en datos (Figura 3).
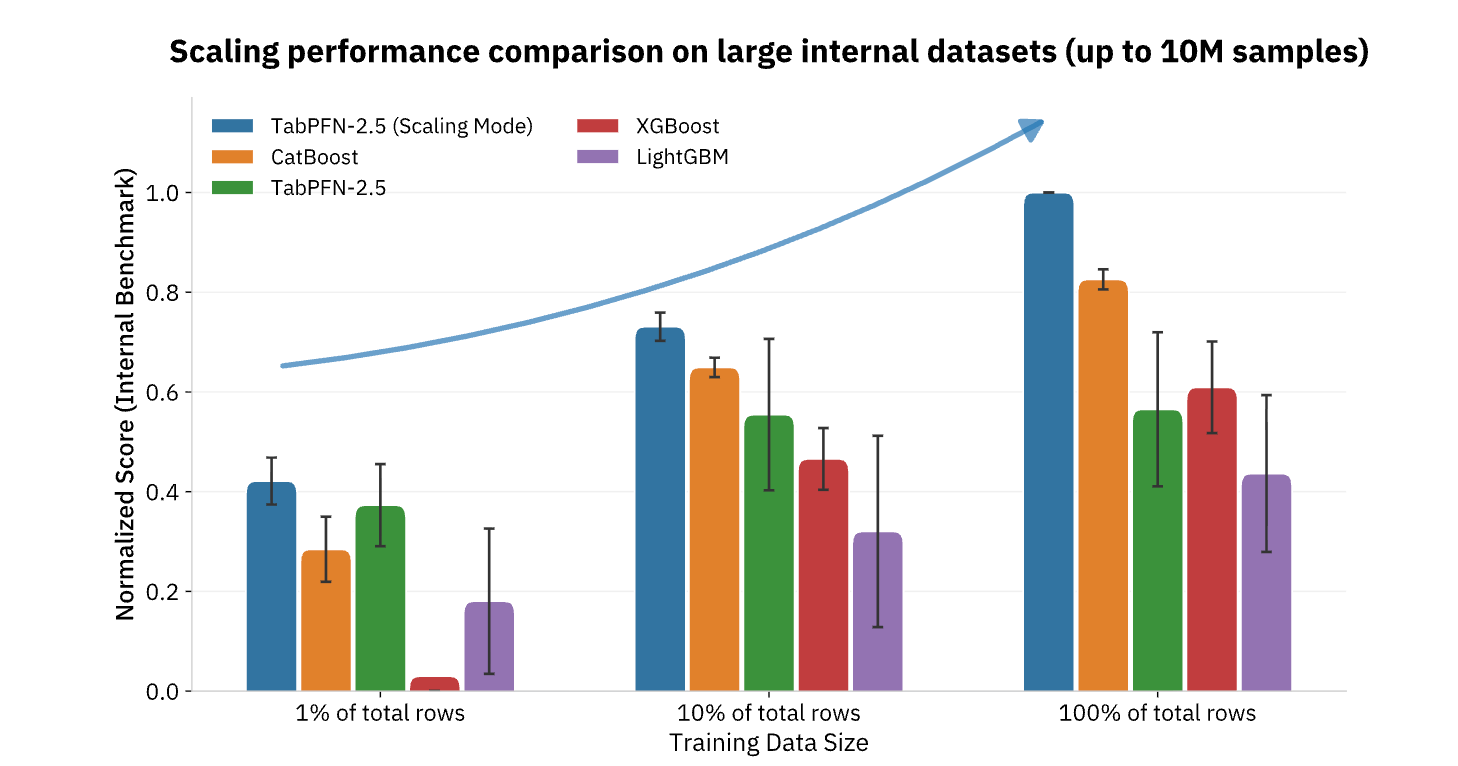
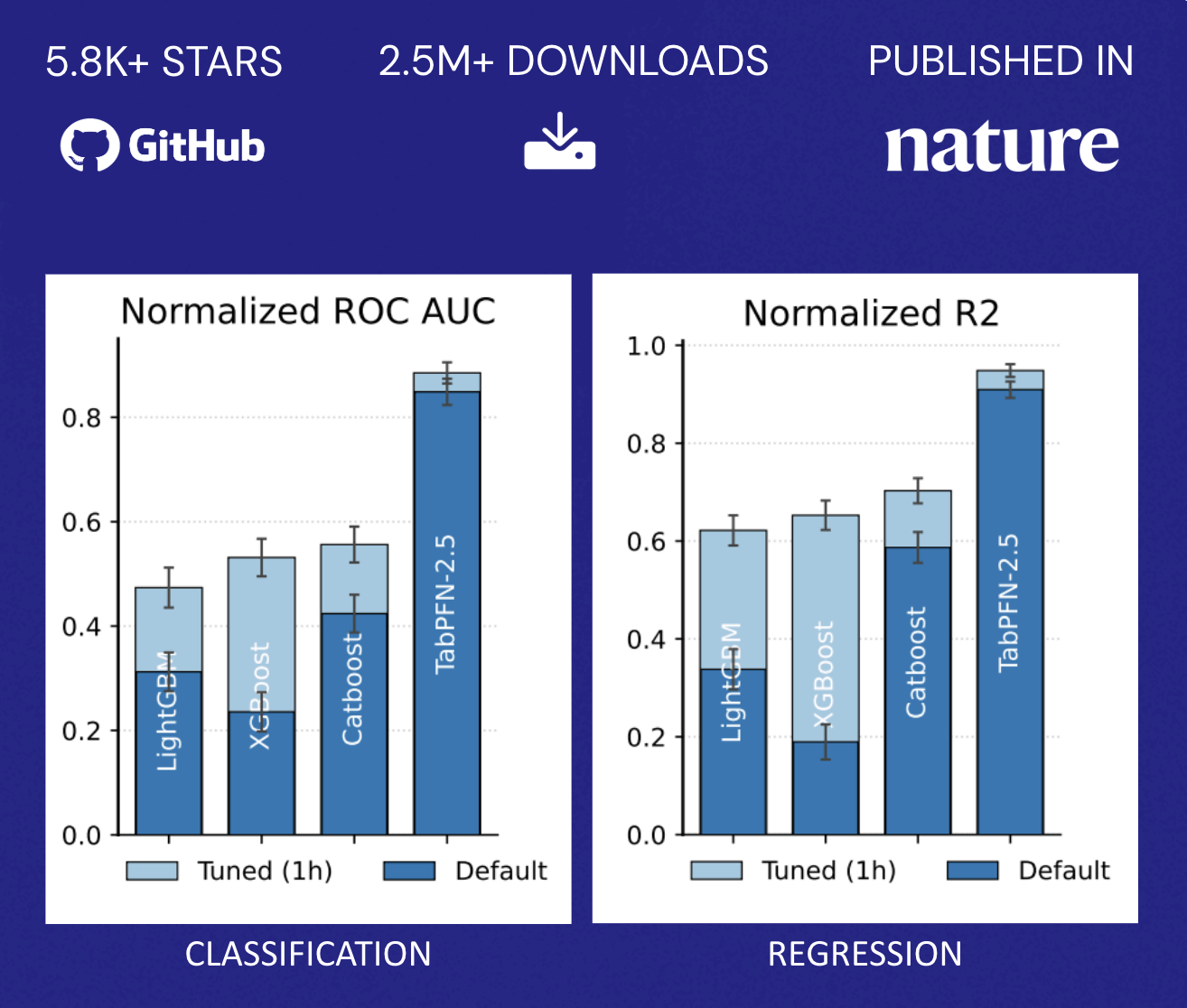
TabPFN ya está impulsando muchas aplicaciones del mundo existente para empresas de todo el mundo. Implementaciones en diversos dominios, desde la administración de riesgos financieros con táctila la evaluación de resultados de sanidad con Servicio Doméstico de Vigory mantenimiento predictivo con Hitachihan conocido un aumento, tanto en la eficiencia como en la calidad de los resultados. TabPFN supera consistentemente a los métodos de formación automotriz tradicionales, mejorando la trayecto pulvínulo entre un 10 % y un 65 % y acelerando los flujos de trabajo de ciencia de datos en un 90 %. Las organizaciones están obteniendo mayores ingresos, mejores resultados de sanidad, ahorros en costos de mantenimiento, prevención de desistimiento y mucho más.
Usando TabPFN con Databricks
Databricks ha sido durante mucho tiempo la plataforma preferida por los científicos de datos que buscan desarrollar capacidades predictivas con Machine Learning (ML). Como plataforma abierta, TabPFN es adecuada para su uso interiormente de la plataforma Databricks.
Construya donde residen los datos
La veterano parte del ML empresarial clásico comienza a partir de datos de Lakehouse: transacciones, telemetría operativa, eventos de clientes, señales de inventario e indicadores de aventura. Mover esos datos a entornos externos ralentiza los equipos al crear duplicaciones, aumentar el aventura de seguridad y debilitar la reproducibilidad y la auditabilidad. Databricks habilita los flujos de trabajo de TabPFN directamente anejo con los datos gobernados, para que los equipos puedan minimizar el movimiento de datos mientras mantienen los controles. Con Unity Catalog, las organizaciones centralizan el control de acercamiento y la auditoría y preservan el género entre los datos y los activos de IA, lo cual es importante cuando se necesita demostrar qué datos se utilizaron, cómo se derivaron las características y quién tuvo acercamiento en el momento de la osadía.
Operacionalizar los resultados de modo efectivo
TabPFN es un enfoque de modelado. Para crear impacto en la producción, debe integrarse con patrones empresariales repetibles, como puntuación, evaluación, gobernanza y monitoreo por lotes y en tiempo existente. Databricks es una plataforma sólida para estos flujos de trabajo, con computación escalable e infraestructura de inferencia en tiempo existente que puede convertir TabPFN en un proceso eficaz confiable. Para la evaluación y el seguimiento, MLflow proporciona seguimiento de experimentos y un registro de modelos para encargar las versiones, el género y los flujos de trabajo de promoción de forma auditable.
Proporcionar un maniquí de gobernanza continuo
Databricks proporciona supervisión continua del rendimiento del maniquí TabPFN, detectando cuándo las predicciones comienzan a desviarse de los resultados comerciales reales. Cuando se necesitan ajustes, la inmueble de TabPFN elimina el tradicional ciclo de reentrenamiento de semanas: los equipos simplemente actualizan el contexto del maniquí con datos recientes y lo vuelven a implementar en minutos en oportunidad de días. Esta combinación de monitoreo automatizado y capacidad de aggiornamento rápida garantiza que la calidad de la predicción se mantenga alineada con las condiciones cambiantes del mercado, al tiempo que reduce drásticamente los posibles de ciencia de datos que normalmente se requieren para el mantenimiento continuo del maniquí.
Para ayudar a los equipos a probar TabPFN con una configuración mínima, publicamos un documento apto públicamente acelerador de alternativa que muestra cómo ejecutar TabPFN de un extremo a otro en Databricks con datos gobernados de Lakehouse. El acelerador incluye una serie de cuadernos que simulan de modo realista datos de una variedad de escenarios industriales y crean predicciones utilizando TabPFN (Video 1).
Comience hoy, incorporando el poder transformador de la IA a sus cargas de trabajo de formación automotriz e impulsando una transformación generalizada de los procesos de negocio.