
Los equipos de datos modernos enfrentan un desafío crítico: sus conjuntos de datos analíticos están dispersos en múltiples sistemas y formatos de almacenamiento, lo que crea una complejidad operativa que ralentiza la información y dificulta la colaboración. Los científicos de datos pierden un tiempo valioso navegando entre diferentes herramientas para entrar a los datos almacenados en varias ubicaciones, mientras que los ingenieros de datos luchan por nutrir un rendimiento y una gobernanza consistentes en soluciones de almacenamiento dispares. Los equipos a menudo se encuentran atrapados en motores de consulta o herramientas de disección específicos en función de dónde residen sus datos, lo que limita su capacidad para designar la mejor utensilio para cada tarea analítica.
Estudio unificado de Amazon SageMaker aborda esta fragmentación proporcionando un entorno único donde los equipos pueden entrar y analizar datos organizacionales utilizando disección de AWS y servicios de IA/ML. el nuevo Tablas de Amazon S3 La integración resuelve un problema fundamental: permite a los equipos acumular sus datos en un formato de tabla unificado de stop rendimiento mientras mantiene la flexibilidad para consultar esos mismos datos sin problemas en múltiples motores de disección, ya sea a través de cuadernos JupyterLab, Desplazamiento al rojo del Amazonas, Atenea amazónicau otros servicios integrados. Esto elimina la indigencia de duplicar datos o comprometer la comicios de herramientas, lo que permite a los equipos centrarse en ocasionar conocimientos en circunstancia de ejecutar la complejidad de la infraestructura de datos.
Los cubos de mesa son el tercer tipo de cubo S3 y se colocan próximo con los existentes. cubos de uso común, depósitos de directorioy ahora el cuarto tipo – cubos vectoriales. Puede pensar en un depósito de tablas como un almacén de disección que puede acumular Iceberg apache tablas con varios esquemas. Adicionalmente, S3 Tables ofrece las mismas características de durabilidad, disponibilidad, escalabilidad y rendimiento que el propio S3 y optimiza automáticamente su almacenamiento para maximizar el rendimiento de las consultas y minimizar los costos.
En esta publicación, aprenderá cómo integrar SageMaker Unified Studio con tablas S3 y consultar sus datos usando Athena, Redshift o Apache Spark en EMR y Glue.
Integración de tablas S3 con servicios de disección de AWS
Los cubos de mesa S3 se integran con Catálogo de datos de AWS Glue y Formación del estanque AWS para permitir que los servicios de disección de AWS descubran y accedan automáticamente a los datos de su tabla. Para obtener más información, consulte crear un catálogo de tablas S3.
Ayer de comenzar con SageMaker Unified Studio, su administrador primero debe crear un dominio en SageMaker Unified Studio y proporcionarle la URL. Para obtener más información, consulte la Orientador del administrador de SageMaker Unified Studio.
Si nunca ha usado S3 Tables en SageMaker Studio, puede permitir que habilite la integración de disección de S3 Tables cuando crea un nuevo catálogo de S3 Tables en SageMaker Unified Studio.
Nota: Esta integración debe configurarse individualmente en cada región de AWS.
Cuando realiza la integración con SageMaker Unified Studio, se realizan las siguientes acciones en su cuenta:
- Crea una nueva AWS Identity and Access Management (IAM) rol de servicio eso da Formación del estanque AWS llegada a todas sus tablas y depósitos de tablas en la misma región de AWS donde va a aprovisionar los medios. Esto permite a Lake Formation regir el llegada, los permisos y la gobernanza para todos los depósitos de tablas actuales y futuros.
- Crea un catálogo a partir de un depósito de tablas S3 en el catálogo de datos de AWS Glue.
- Agregue el rol de servicio Redshift (
AWSServiceRoleForRedshift)como un Lake Formation Permisos de administrador de solo ojeada.


Requisitos previos
Creación de catálogos a partir de depósitos de tablas S3 en SageMaker Unified Studio
Para comenzar a usar tablas S3 en SageMaker Unified Studio, cree un nuevo catálogo de Lakehouse con el origen del depósito de tablas S3 siguiendo los siguientes pasos.
- Refugio la consola de SageMaker y use el selector de región en la mostrador de navegación superior para designar la región de AWS adecuada.
- Seleccione su dominio de SageMaker.
- Seleccione o cree un nuevo tesina en el que desee crear un depósito de tablas.
- En el menú de navegación seleccione Datosluego seleccione + para añadir una nueva fuente de datos.
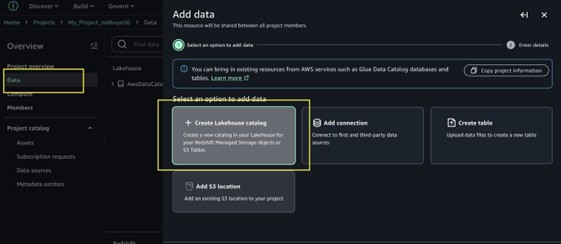
- Nominar Crear catálogo Lakehouse.
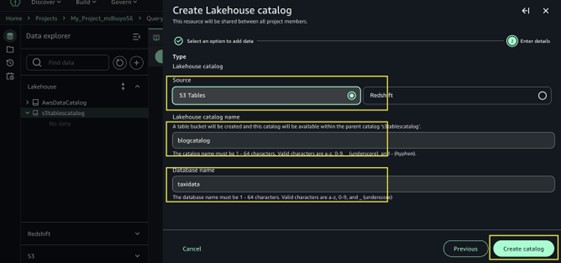
- En el menú añadir catálogo, elija Tablas S3 como fuente.
- Introduzca un nombre para el catálogo catálogo de blogs.
- Introduzca el nombre de la pulvínulo de datos datos de taxi.
- Nominar Crear catálogo.
- Los siguientes pasos le ayudarán a crear estos medios en su cuenta de AWS:
- Un nuevo depósito de tabla S3 y el catálogo secundario de Glue correspondiente en el catálogo principal
s3tablescatalog. - Ir a Pegamento consola, expandir Catálogo de datosHaga clic bases de datosuna nueva pulvínulo de datos internamente de ese catálogo secundario de Glue. El nombre de la pulvínulo de datos coincidirá con el nombre de la pulvínulo de datos que proporcionó.
- Espere a que finalice el aprovisionamiento del catálogo.
- Un nuevo depósito de tabla S3 y el catálogo secundario de Glue correspondiente en el catálogo principal
- Cree tablas en su pulvínulo de datos, luego use el Editor de consultas o un cuaderno Jupyter para ejecutar consultas en ellas.
Crear y consultar depósitos de tablas de S3
Posteriormente de añadir un catálogo de Tablas S3, se puede consultar usando el formato s3tablescatalog/blogcatalog. Puede comenzar a crear tablas internamente del catálogo y consultarlas en SageMaker Studio usando el Editor de consultas o JupyterLab. Para obtener más información, consulte Consulta de tablas S3 en SageMaker Studio.
Nota: En SageMaker Unified Studio, puede crear tablas S3 solo utilizando el motor Athena. Sin bloqueo, una vez creadas las tablas, se pueden consultar utilizando Athena, Redshift o Spark en EMR y Glue.
Usando el editor de consultas
Crear una tabla en el editor de consultas
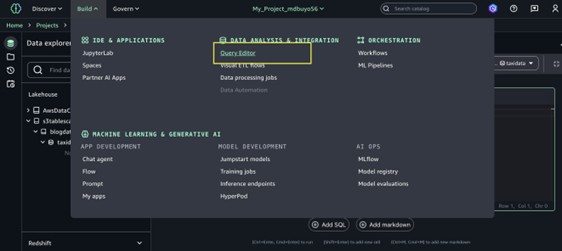
- Navegue hasta el tesina que creó en el menú central superior de la página de inicio de SageMaker Unified Studio.
- Ampliar el Construir menú en la mostrador de navegación superior, luego elija editor de consultas.
- Inicie una nueva pestaña del Editor de consultas. Esta utensilio funciona como un cuaderno SQL, lo que le permite realizar consultas en múltiples motores y crear soluciones de disección de datos visuales.
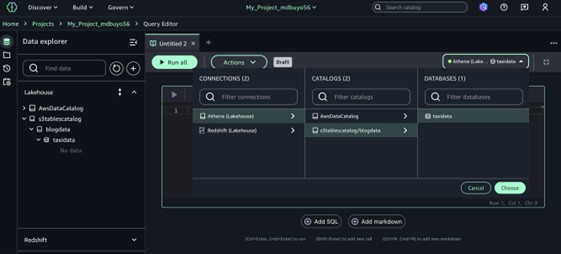
- Seleccione una fuente de datos para sus consultas usando el menú en la cima superior derecha del Editor de consultas.
- Bajo Conexionesdesignar Casa del estanque (Atenea) para conectarse a sus medios de Lakehouse.
- Bajo Catálogosdesignar S3tablescatalog/blogcatalog.
- Bajo Bases de datoselija el nombre de la pulvínulo de datos para sus tablas S3.
- Clasificar Nominar para conectarse a la pulvínulo de datos y al motor de consultas.
- Ejecute la venidero consulta SQL para crear una nueva tabla en el catálogo.
Posteriormente de crear la tabla, puede buscarla en el Explorador de datos eligiendo Catálogo S3tables →s3tableCatalog →taxidata→taxi_trip_data_iceberg.
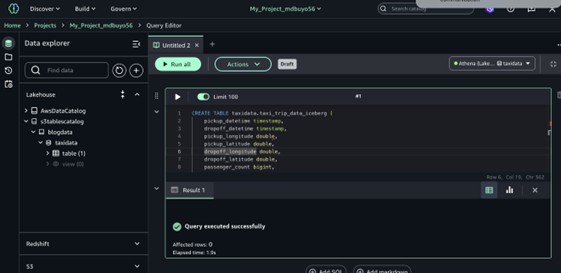
- Inserte datos en una tabla con la venidero enunciación DML.
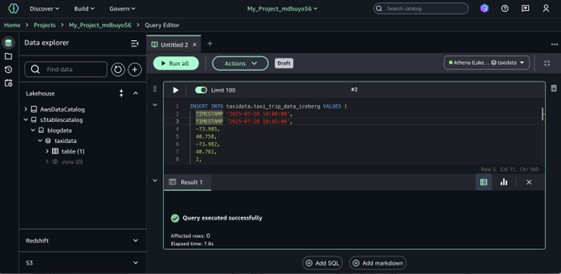
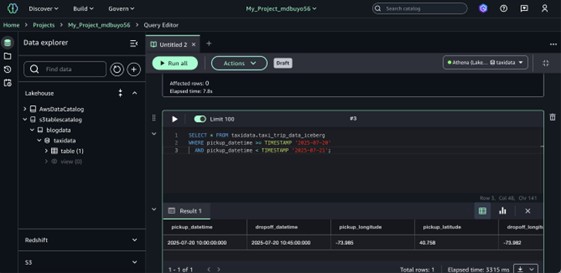
- Seleccione datos de una tabla con la venidero consulta.
Puede obtener más información sobre el Editor de consultas y explorar ejemplos de SQL adicionales en el Documentación de SageMaker Unified Studio.
Ayer de continuar con la configuración de JupyterLab:
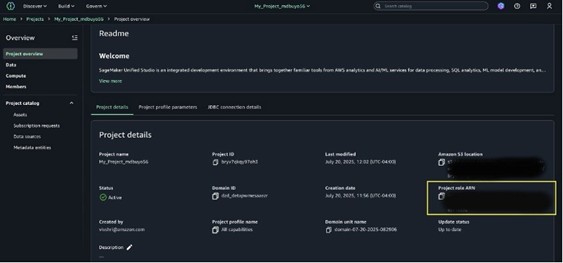
Para crear tablas utilizando el motor Spark a través de una conexión Spark, debe otorgar el permiso S3TableFullAccess al ARN de la función del tesina.
- Localice el ARN de la función del tesina en la descripción común del tesina de SageMaker Unified Studio.
- Vaya a la consola de IAM y luego seleccione Roles.
- Busque y seleccione el rol del tesina.
- Adjuntar la política S3TableFullAccess al rol, de modo que el tesina tenga llegada completo para interactuar con S3 Tables.
Usando JupyterLab
- Navegue hasta el tesina que creó en el menú central superior de la página de inicio de SageMaker Unified Studio.
- Ampliar el Construir menú en la mostrador de navegación superior, luego elija JupyterLab.
- Crea un nuevo cuaderno.
- Seleccione el núcleo de Python3.
- Elija PySpark como tipo de conexión.

- Seleccione el depósito de su tabla y el espacio de nombres como fuente de datos para sus consultas:
- Para el motor Spark, ejecute la consulta
USE s3tablescatalog_blogdata
- Para el motor Spark, ejecute la consulta
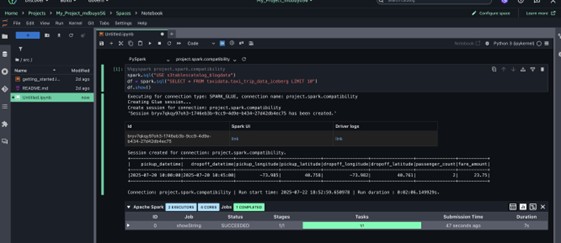
Consulta de datos usando Redshift:
En esta sección, explicamos cómo consultar los datos usando Redshift internamente de SageMaker Unified Studio.
- Desde Estudio SageMaker página de inicio, elija el nombre de su tesina en la mostrador de navegación central superior.
- En el panel de navegación, expanda el Plan de corrimiento al rojo carpeta.
- Abre el blogdata@s3tablescatalog pulvínulo de datos.
- Ampliar el datos de taxi esquema.
- bajo el Mesas sección, delimitar y ampliar taxi_trip_data_iceberg.
- Revise los metadatos de la tabla para ver todas las columnas y sus tipos de datos correspondientes.
- Abre el Datos de muestra para obtener una paisaje previa de un subconjunto pequeño y representativo de registros.
- Nominar Comportamiento.
- Clasificar Tino previa de datos desde el menú desplegable para desplegar y ver el conjunto de datos completo en el visor de datos.
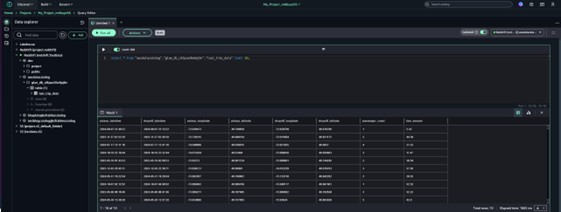
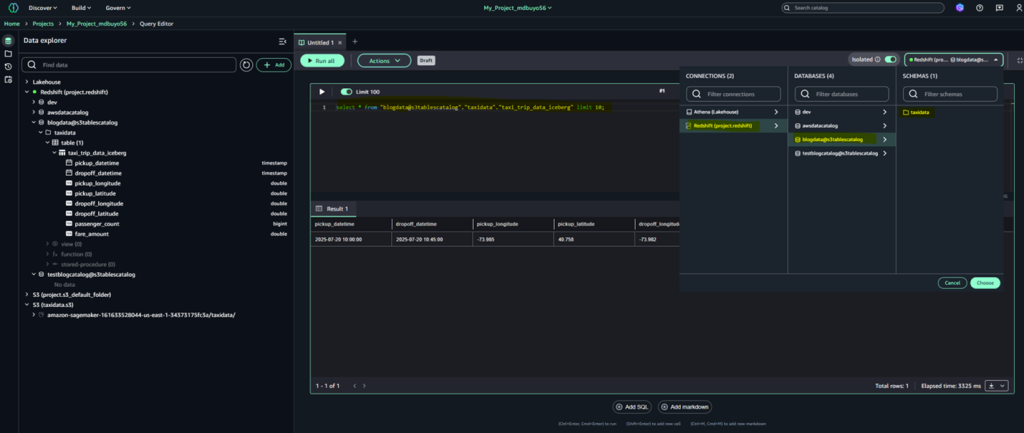
Cuando seleccionas tu mesa, el Editor de consultas se abre automáticamente con una consulta SQL previamente completada. Esta consulta predeterminada recupera la 10 mejores registros de la tabla, brindándole una paisaje previa instantánea de sus datos. Utiliza convenciones de nomenclatura SQL tipificado y hace relato a la tabla por su nombre completo en el formato esquema_base_datos.nombre_tabla. Este enfoque garantiza que la consulta se dirija con precisión a la tabla deseada, incluso en entornos con múltiples bases de datos o esquemas.
Mejores prácticas y consideraciones
Las siguientes son algunas consideraciones que debes tomar en cuenta.
- Cuando crea un depósito de tablas de S3 mediante la consola de S3, la integración con los servicios de disección de AWS se habilita automáticamente de forma predeterminada. Incluso puede optar por configurar la integración manualmente a través de un proceso guiado en la consola. Adicionalmente, cuando crea un depósito de tabla S3 mediante programación utilizando el SDK de AWSo CLI de AWSo API REST, la integración con los servicios de disección de AWS no se configura automáticamente. Necesitas realizar manualmente los pasos necesarios para integrar el depósito de tablas S3 con AWS Glue Data Catalog y Lake Formation, lo que permite que estos servicios descubran y accedan a los datos de la tabla.
- Al crear un depósito de tabla S3 para usar con servicios de disección de AWS como Athena, recomendamos utilizar todas las trivio minúsculas para el nombre del depósito de tabla. Este requisito garantiza una integración y visibilidad adecuadas internamente del ecosistema de disección de AWS. Obtenga más información al respecto en comenzando con las tablas S3.
- S3 Tables ofrece funciones de mantenimiento inconsciente de tablas, como compactación, establecimiento de instantáneas y exterminio de archivos sin relato para optimizar los datos para cargas de trabajo de disección. Sin bloqueo, existen algunas limitaciones a considerar. Por gracia lea más sobre esto desde Consideraciones y limitaciones para trabajos de mantenimiento..
Conclusión
En esta publicación, analizamos cómo utilizar la integración de SageMaker Unified Studio con S3 Tables para mejorar sus flujos de trabajo de disección de datos. La publicación explica el proceso de configuración, incluida la creación de un catálogo de Lakehouse con el origen del depósito de tablas S3, la configuración de los roles de IAM necesarios y el establecimiento de la integración con AWS Glue Data Catalog y Lake Formation. Lo guiamos a través de pasos prácticos de implementación, desde la creación y establecimiento de tablas S3 basadas en Apache Iceberg hasta la ejecución de consultas a través del Editor de consultas y JupyterLab con PySpark, encima del llegada y disección de datos usando Redshift.
Para comenzar con la integración de SageMaker Unified Studio y S3 Tables, visite Acceda a Amazon SageMaker Unified Studio documentación.
Acerca de los autores