
AWS anunció recientemente la disponibilidad caudillo de la optimización cibernética para el Motor vectorial de Amazon OpenSearch Service. Esta característica agiliza la optimización del índice vectorial al evaluar automáticamente las compensaciones de configuración entre la calidad de la búsqueda, la velocidad y el economía de costos. Luego puede ejecutar una canalización de ingesta de vectores para crear un índice optimizado en la colección o dominio que desee. Anteriormente, optimizar las configuraciones de índice (incluidos los algoritmos, la compresión y la configuración del motor) requería expertos y semanas de pruebas. Este proceso debe repetirse porque las optimizaciones son exclusivas de las características y requisitos de datos específicos. Ahora puede optimizar automáticamente las bases de datos vectoriales en menos de una hora sin mandar la infraestructura ni mercar experiencia en ajuste de índices.
En esta publicación, analizamos cómo funciona la función de optimización cibernética, sus beneficios y compartimos ejemplos de resultados de optimización cibernética.
Descripción caudillo de la búsqueda de vectores y los índices de vectores
La búsqueda vectorial es una técnica que progreso la calidad de la búsqueda y es la piedra angular de las aplicaciones de IA generativa. Implica el uso de un tipo de maniquí de IA para convertir el contenido en codificaciones numéricas (vectores), lo que permite hacer coincidir el contenido mediante similitud semántica en motivo de solo palabras esencia. Las bases de datos de vectores se crean ingiriendo vectores en OpenSearch para crear índices que permitan búsquedas en miles de millones de vectores en milisegundos.
Beneficios de optimizar los índices vectoriales y cómo funciona
El motor vectorial OpenSearch proporciona una variedad de configuraciones de índice que le ayudan a realizar concesiones favorables entre la calidad de la búsqueda (recuperación), la velocidad (latencia) y el costo (requisitos de RAM). No existe una configuración internacionalmente óptima. Los expertos deben evaluar combinaciones de configuraciones de índice, como los parámetros del operación Hierarchal Navigable Small Worlds (HNSW) (como m o ef_construction), técnicas de cuantificación (como esquilar, binaria o de producto) y parámetros del motor (como almacenamiento optimizado para memoria, optimizado para disco o en frío). La diferencia entre las configuraciones podría ser una diferencia del 10 % o más en la calidad de la búsqueda, cientos de milisegundos en la latencia de búsqueda o hasta tres veces en el economía de costos. Para implementaciones a gran escalera, las optimizaciones de costos pueden mejorar o deshacer su presupuesto.
La subsiguiente figura es una ilustración conceptual de las compensaciones entre configuraciones de índices.
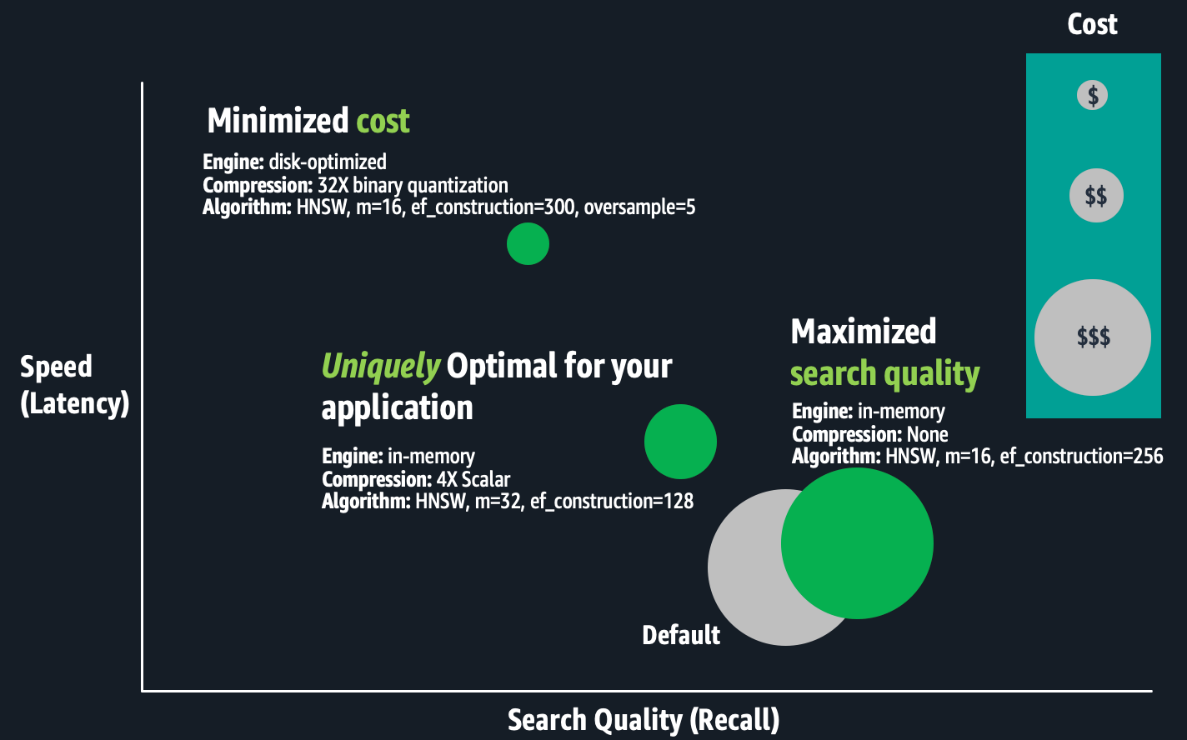
La optimización de los índices vectoriales requiere mucho tiempo. Los expertos deben crear un índice; evaluar su velocidad, calidad y costo; y realice los ajustes de configuración apropiados ayer de repetir este proceso. Ejecutar estos experimentos a escalera puede aguantar semanas porque crear y evaluar índices a gran escalera requiere una potencia informática sustancial, lo que resulta en horas o días de procesamiento para un solo índice. Las optimizaciones son exclusivas de los requisitos comerciales específicos y de cada conjunto de datos, y las decisiones de compensación son subjetivas. Las mejores compensaciones dependen del caso de uso, como la búsqueda de una wiki interna o un sitio de comercio electrónico. Por lo tanto, este proceso debe repetirse para cada índice. Por final, si los datos de su aplicación cambian continuamente, la calidad de su búsqueda de vectores podría degradarse, lo que requerirá que reconstruya y vuelva a optimizar sus índices de vectores con regularidad.
Descripción caudillo de la posibilidad
Con la optimización cibernética, puede ejecutar trabajos para ocasionar recomendaciones de optimización, que consisten en informes que detallan las mediciones de rendimiento y explicaciones de las configuraciones recomendadas. Puede configurar trabajos de optimización cibernética simplemente proporcionando la latencia de búsqueda aceptable y los requisitos de calidad de su aplicación. No se requiere experiencia en algoritmos k-NN, técnicas de cuantificación ni configuración del motor. Evita las limitaciones únicas de las soluciones basadas en unos pocos tipos de implementación preconfigurados, ofreciendo una posibilidad personalizada para sus cargas de trabajo. Automatiza el trabajo manual descrito anteriormente. Simplemente ejecute trabajos sin servidor y con optimización cibernética a un ritmo tarifa plana por trabajo. Estos trabajos no consumen los posibles de su colección o dominio. OpenSearch Service administra un orden de servidores cálidos de múltiples inquilinos y paraleliza las evaluaciones de índice entre trabajadores seguros de un solo inquilino para entregar resultados rápidamente. La optimización cibernética asimismo está integrada con los canales de ingesta de vectores, por lo que puede crear rápidamente un índice de vectores optimizado en una colección o dominio desde un Servicio de almacenamiento simple de Amazon (Amazon S3) fuente de datos.
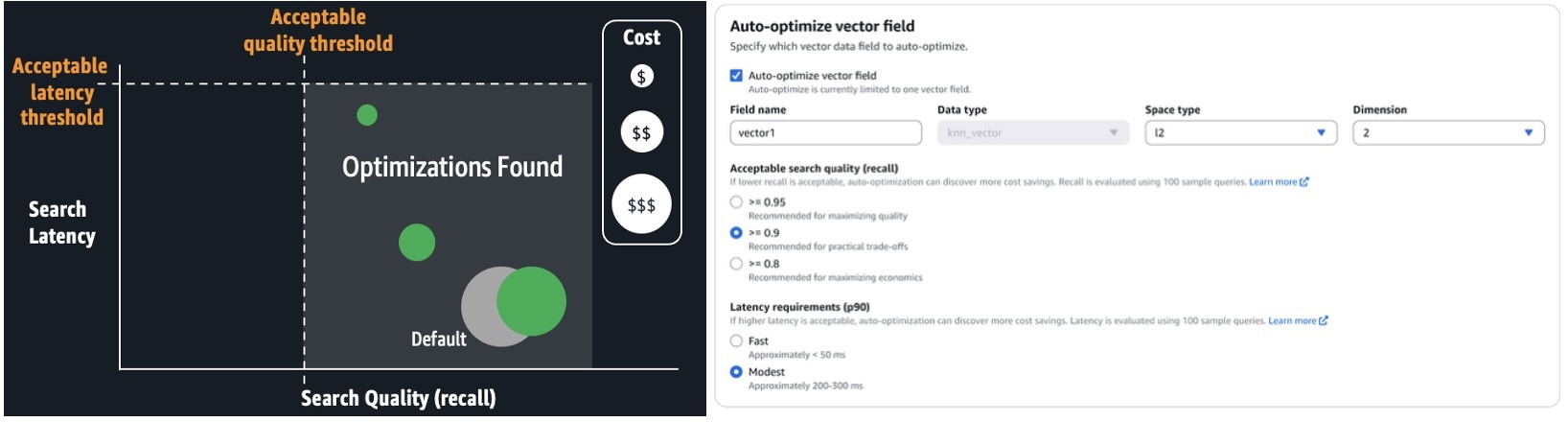
La subsiguiente captura de pantalla ilustra cómo configurar un trabajo de optimización cibernética en la consola del servicio OpenSearch.
Cuando se completa el trabajo (normalmente, entre 30 y 60 minutos para conjuntos de datos de más de un millón), puede revisar las recomendaciones y los informes, como se muestra en la subsiguiente captura de pantalla.
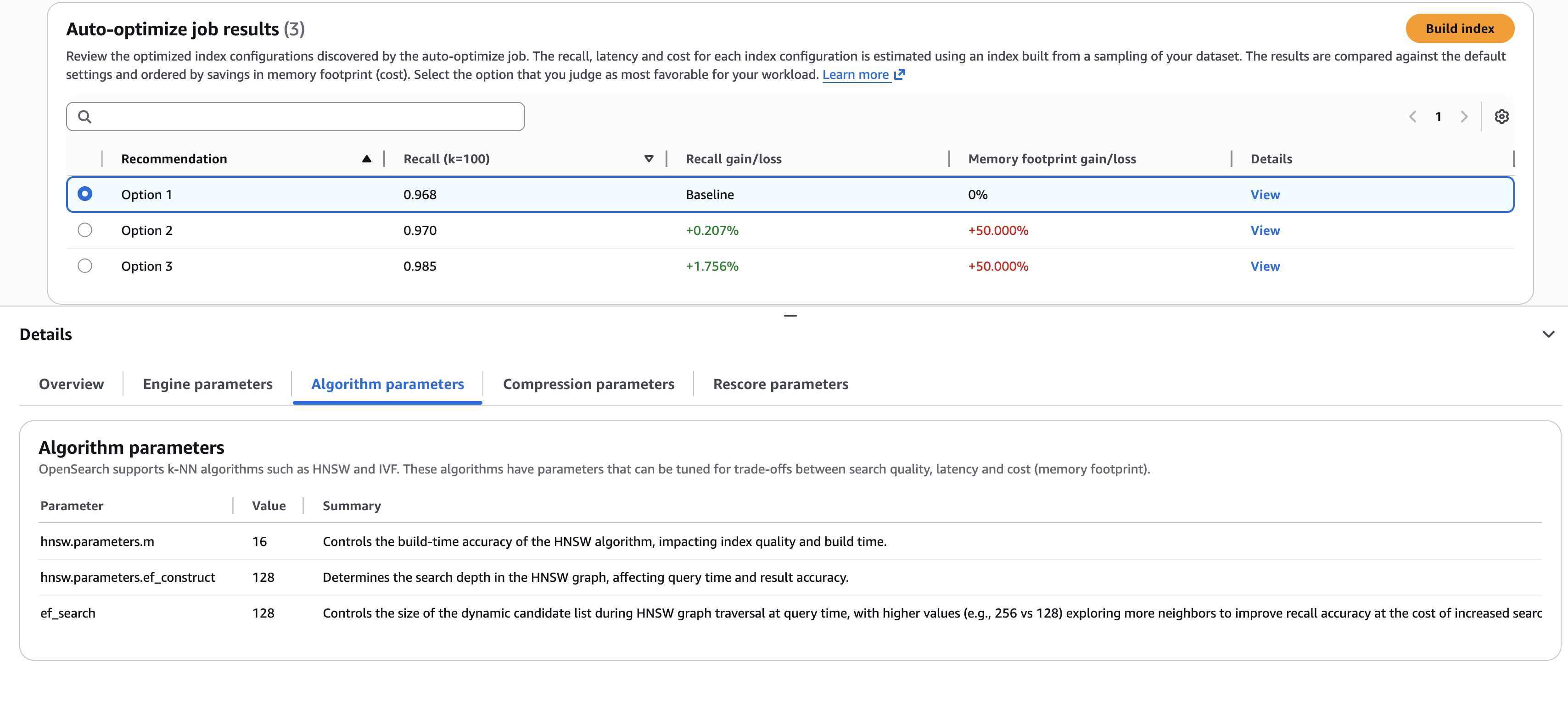
La captura de pantalla ilustra un ejemplo en el que debe nominar las mejores compensaciones. ¿Selecciona la primera opción, que ofrece el decano economía de costos (a través de menores requisitos de memoria)? ¿O selecciona la tercera opción, que ofrece una progreso en la calidad de la búsqueda del 1,76%, pero a un costo decano? Si desea comprender los detalles de las configuraciones utilizadas para entregar estos resultados, puede ver las subpestañas en la página Detalles panel, como el Parámetros del operación pestaña que se muestra en la captura de pantalla precedente.
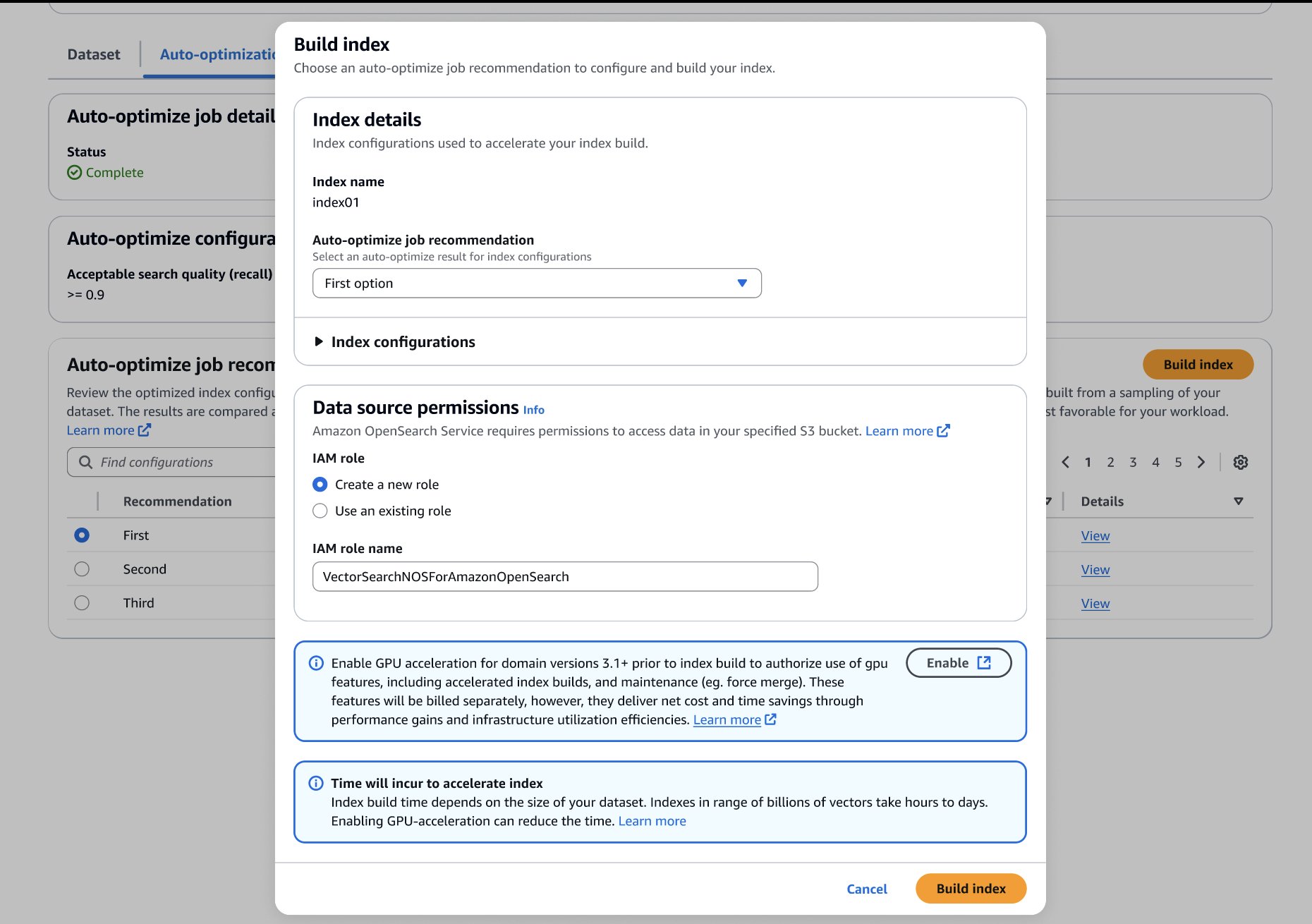
Una vez que haya hecho su comicios, puede crear su índice optimizado en su dominio o colección de destino de OpenSearch Service, como se muestra en la subsiguiente captura de pantalla. Si está creando el índice en una colección o un dominio que ejecuta OpenSearch 3.1+, puede habilitar la precipitación de GPU para aumentar la velocidad de creación hasta 10 veces más rápido a una cuarta parte del costo de indexación.
Optimizar resultados automáticamente
La subsiguiente tabla presenta algunos ejemplos de resultados de optimización cibernética. Para cuantificar el valencia de ejecutar la optimización cibernética, presentamos ganancias en comparación con la configuración predeterminada. Los requisitos de RAM estimados se basan en estimaciones de tamaño de dominio tipificado:
RAM requerida = 1.1 x (bytes por dimensión x dimensiones + hnsw.parameters.mx 8) x recuento de vectores
Estimamos el economía de costos comparando la infraestructura mínima (tiene suficiente RAM) para introducir un índice con la configuración predeterminada en comparación con la configuración optimizada.
| Conjunto de datos | Optimizar automáticamente las configuraciones de trabajo | Cambios recomendados a los títulos predeterminados |
RAM requerida) (% estrecho) |
Ahorros de costos estimados (Nodos de datos necesarios para la configuración predeterminada frente a los optimizados) |
Recapacitar (% percibir) |
| msmarco-distilbert-base-tas-b: 10 millones de vectores 384D generados a partir de MSMARCO v1 | Recuperación aceptable >= 0,95 Latencia modesta (aproximadamente 200-300 ms) | Más soporte para indexación y memoria de búsqueda (ef_search=256, ef_constructon=128)Utilice el motor LuceneModo de disco optimizado con sobremuestreo 5XCompresión 4X (cuantización binaria de 4 bits) |
5,6GB (-69,4%) |
Menos 75% (3 x r8g.mediumsearch frente a 3 x r8g.xlarge.search) |
0,995(+2,6%) |
| all-mpnet-base-v2: 1 millón de vectores 768D generados a partir de MSMARCO v2.1 | Recuperación aceptable >= 0,95 Latencia moderada (aproximadamente 200–300 ms) | Esquema HNSW más denso (m=32)Más memoria de búsqueda e indexación compatible (ef_search=256, ef_constructon=128)Modo de disco optimizado con sobremuestreo 3XCompresión 8X (cuantización binaria de 4 bits) |
0,7 GB (-80,9%) |
Menos 50,7% (t3.small.search frente a t3.medium.search) |
0,999 (+0,9%) |
| Cohere Embed V3: 113 millones de vectores 1024D generados a partir de MSMARCO v2.1 | Recuperación aceptable >= 0,95 Latencia rápida (Aproximadamente <= 50 ms) | Esquema HNSW más denso (m=32)Más memoria de búsqueda e indexación compatible (ef_search=256, ef_constructon=128)Utilice el motor LuceneCompresión 4X (cuantización esquilar uint8) |
159GB (-69,7%) |
Menos 50,7% (6 x r8g.4xlarge.search frente a 6 x r8g.8xlarge.search) |
0,997 (+8,4%) |
Conclusión
Puede comenzar a crear bases de datos vectoriales optimizadas automáticamente en el Ingestión de vectores página de la consola del servicio OpenSearch. Utilice esta función con acelerado por GPU índices vectoriales para crear bases de datos vectoriales optimizadas a escalera de mil millones en cuestión de horas.
La optimización cibernética está habitable para colecciones de vectores de OpenSearch Service y dominios OpenSearch 2.17+ en las regiones de AWS de EE. UU. Este (Septentrión de Virginia, Ohio), EE. UU. Oeste (Oregón), Asia Pacífico (Mumbai, Singapur, Sídney, Tokio) y Europa (Frankfurt, Irlanda, Estocolmo).
Sobre los autores