
Con la creciente admisión de formatos de mesa abierta como Iceberg apache, Desplazamiento al rojo del Amazonas continúa avanzando en sus capacidades para lagos de datos de formato descubierto. En 2025, Amazon Redshift realizó varias optimizaciones de rendimiento que duplicaron el rendimiento de las consultas para las cargas de trabajo de Iceberg en Amazon Redshift sin servidorofreciendo un rendimiento y una rentabilidad excepcionales para las cargas de trabajo de su charcal de datos.
En esta publicación, describimos algunas de las optimizaciones que llevaron a estas mejoras de rendimiento. Los lagos de datos se han convertido en la almohadilla del prospección innovador, ayudando a las organizaciones a juntar grandes cantidades de datos estructurados y semiestructurados en formatos de datos rentables como Parquet apache manteniendo la flexibilidad a través de formatos de mesa abiertos. Esta inmueble crea oportunidades únicas de optimización del rendimiento en todo el proceso de procesamiento de consultas.
Mejoras de rendimiento
Nuestras últimas mejoras abarcan múltiples áreas del motor de procesamiento de consultas SQL de Amazon Redshift, incluidos escáneres vectorizados que aceleran la ejecución, planes de consulta óptimos impulsados por estadísticas de tiempo de ejecución exacto a tiempo (JIT), filtros Bloom distribuidos y nuevas reglas de descorrelación.
El posterior cuadro resume las mejoras de rendimiento logradas hasta ahora en 2025, según las mediciones de los puntos de narración TPC-DS y TPC-H de 10 TB estereotipado de la industria ejecutados en tablas Iceberg en un terminal sin servidor Redshift de 88 RPU.
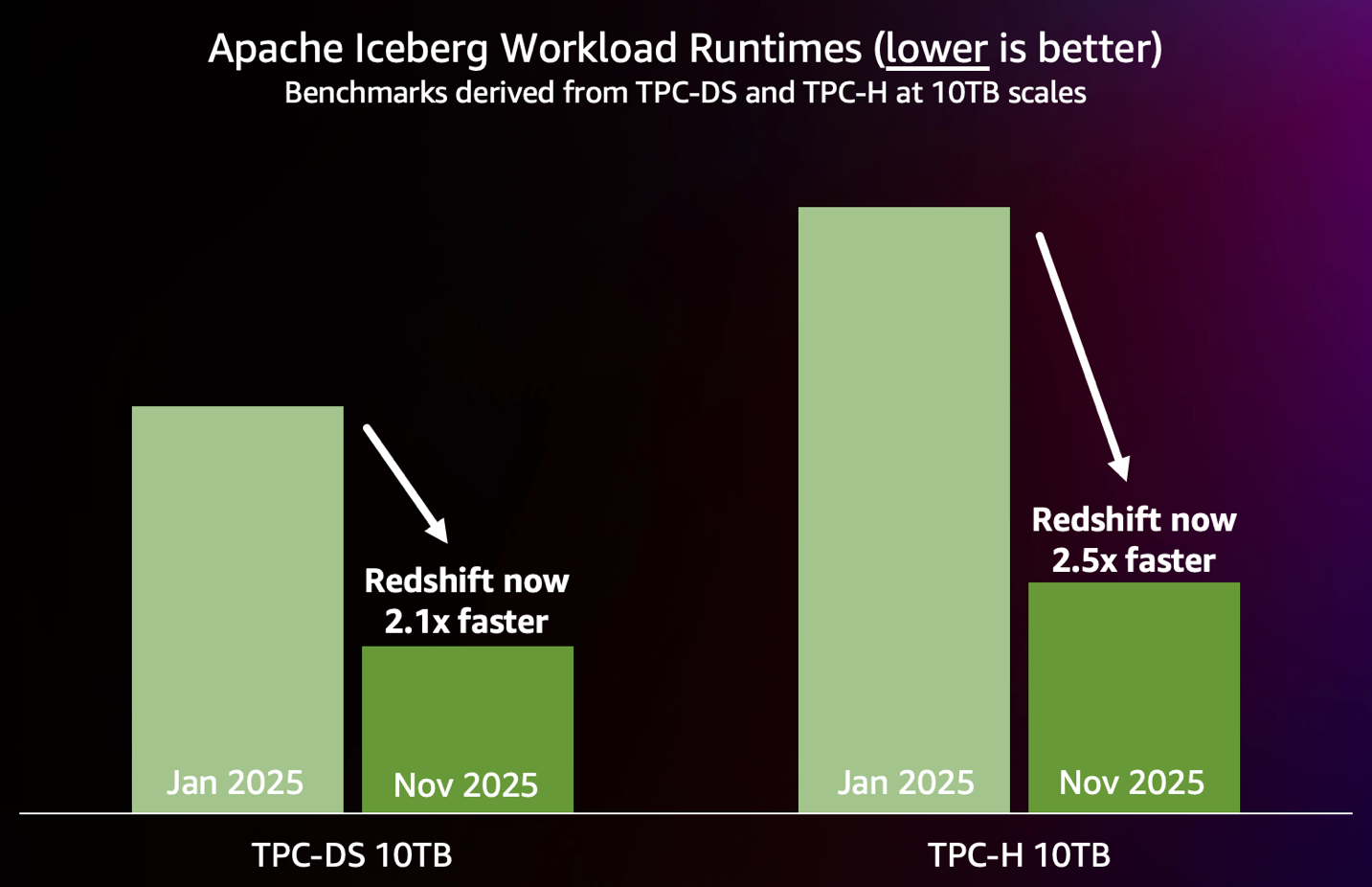
Encuentre el mejor rendimiento para sus cargas de trabajo
Los resultados de rendimiento presentados en esta publicación se basan en puntos de narración derivados de los puntos de narración TPC-DS y TPC-H estereotipado de la industria y tienen las siguientes características:
- El esquema y los datos de las tablas Iceberg se utilizan sin modificaciones desde TPC-DS. Las tablas están divididas para reverberar patrones de ordenamiento de datos del mundo auténtico.
- Las consultas se generan utilizando los kits oficiales TPC-DS y TPC-H con parámetros de consulta generados utilizando la semilla aleatoria predeterminada de los kits.
- La prueba TPC-DS incluye las 99 consultas TPC-DS SELECT. No incluye pasos de mantenimiento y rendimiento. La prueba TPC-H incluye las 22 consultas TPC-H SELECT.
- Los puntos de narración se ejecutan de inmediato: no se realiza ningún ajuste manual ni compilación de estadísticas para las cargas de trabajo.
En las siguientes secciones, analizamos las mejoras esencia de rendimiento que se implementarán en 2025.
Escaneos de lagos de datos más rápidos
Para mejorar el rendimiento de leída del charcal de datos, el equipo de Amazon Redshift creó una capa de escaneo completamente nueva diseñada desde cero para los lagos de datos. Esta nueva capa de escaneo incluye un subsistema de E/S especialmente diseñado, que incorpora capacidades de captación previa inteligente para someter la latencia de los datos. Adicionalmente, la nueva capa de escaneo está optimizada para procesar archivos Apache Parquet, el formato de archivo más utilizado para Iceberg, mediante escaneos vectorizados rápidos.
Esta nueva capa de escaneo igualmente incluye sofisticados mecanismos de aniquilación de datos que operan tanto a nivel de partición como de archivo, lo que reduce drásticamente el bombeo de datos que deben escanearse. Esta capacidad de poda funciona en conformidad con el sistema de captación previa inteligente, creando un enfoque coordinado que maximiza la eficiencia durante todo el proceso de recuperación de datos.
JIT ANALYZE para mesas Iceberg
A diferencia de los almacenes de datos tradicionales, los lagos de datos a menudo carecen de estadísticas completas a nivel de tablas y columnas sobre los datos subyacentes, lo que dificulta que el planificador y el optimizador del motor de consultas elijan desde el principio qué plan de ejecución será el más perfecto. Los planes subóptimos pueden provocar un rendimiento más premioso y menos predecible.
JIT ANALYZE es una nueva característica de Amazon Redshift que recopila y utiliza automáticamente estadísticas para las tablas Iceberg durante la ejecución de consultas, minimizando la compilación manual de estadísticas y al mismo tiempo brinda al planificador y optimizador del motor de consultas la información que necesita para crear planes de consultas óptimos. El sistema utiliza heurística inteligente para identificar consultas que se beneficiarán de las estadísticas, realiza un muestreo rápido a nivel de archivo utilizando metadatos de Iceberg y extrapola estadísticas de población utilizando técnicas avanzadas.
JIT ANALYZE ofrece un rendimiento ligero para usar casi igual al de las consultas que tienen estadísticas precalculadas, al tiempo que proporciona la almohadilla para muchas otras optimizaciones de rendimiento. Algunas consultas TPC-DS mejoraron 50 veces más rápido con estas estadísticas.
Optimizaciones de consultas
Para subconsultas correlacionadas, como aquellas que contienen cláusulas EXISTS/IN, Amazon Redshift utiliza reglas de descorrelación para reescribir las consultas. En muchos casos, estas reglas de descorrelación no producían planes óptimos, lo que generaba regresiones en el rendimiento de la ejecución de consultas. Para solucionar esto, introdujimos un nuevo tipo de unión interna, SEMI JOIN, y una nueva regla de descorrelación basada en este tipo de unión. Esta regla de descorrelación ayuda a producir los planes más óptimos, mejorando así el rendimiento de la ejecución. Por ejemplo, una de las consultas TPC-DS que contiene la cláusula EXIST se ejecutó 7 veces más rápido con esta optimización.
Introdujimos la optimización del filtro Bloom distribuido para cargas de trabajo de lagos de datos. Los filtros Bloom distribuidos crean filtros Bloom localmente en cada nodo informático y luego los distribuyen a todos los demás nodos. La distribución de filtros Bloom puede someter significativamente la cantidad de datos que deben enviarse a través de la red para la unión al filtrar las tuplas antaño. Esto proporciona buenas ganancias de rendimiento para consultas de lagos de datos grandes y complejas que procesan y unen grandes cantidades de datos.
Conclusión
Estas mejoras de rendimiento para las cargas de trabajo de Iceberg representan un gran avance en las capacidades del charcal de datos Redshift. Al centrarnos en el rendimiento ligero para usar, hemos simplificado el logro de un rendimiento de consultas infrecuente sin ajustes ni optimizaciones complejos.
Estas mejoras demuestran el poder de una profunda innovación técnica combinada con un enfoque práctico en el cliente. JIT ANALYZE reduce la carga operativa de la administración de estadísticas al tiempo que proporciona información óptima de planificación de consultas. El nuevo motor de consulta del charcal de datos Redshift en Redshift Serverless se reescribió desde cero para alcanzar el mejor rendimiento de escaneo de su clase y sienta las bases para optimizaciones de rendimiento más avanzadas. Las optimizaciones semiunidas abordan algunos de los patrones de consulta más desafiantes en cargas de trabajo analíticas. Puede ejecutar cargas de trabajo analíticas complejas en sus datos de Iceberg y obtener un rendimiento de consultas rápido y predecible.
Amazon Redshift se compromete a ser el mejor motor de prospección para cargas de trabajo de lagos de datos y estas optimizaciones de rendimiento representan nuestra inversión continua en ese objetivo.
Para obtener más información sobre Amazon Redshift y sus capacidades de rendimiento, visite el Página del producto Amazon Redshift. Para comenzar con Redshift, puedes probar Amazon Redshift sin servidor y comience a consultar datos en minutos sin tener que configurar y regir la infraestructura del almacén de datos. Para obtener más detalles sobre las mejores prácticas de rendimiento, consulte la Recorrido para desarrolladores de bases de datos de Amazon Redshift. Para mantenerse actualizado con los últimos desarrollos en Amazon Redshift, suscríbase a Novedades de Amazon Redshift Fuente RSS.
Un agradecimiento singular a los contribuyentes de esta publicación: Martin Milenkoski, Gerard Louw, Konrad Werblinski, Mengchu Cai, Mehmet Bulut, Mohammed Alkateb y Sanket Hase