
Portar desde BigQuery de Google Cloud a Abundancia ClickHouse en AWS permite a las empresas usar la velocidad y la eficiencia de ClickHouse para realizar disección en tiempo auténtico mientras se benefician del entorno escalable y seguro de AWS. Este artículo proporciona una folleto completa para ejecutar una migración de datos directa utilizando Pegamento AWS ETL, destacando las ventajas y mejores prácticas para una transición perfecta.
AWS Glue ETL permite a las organizaciones descubrir, preparar e integrar datos a escalera sin la carga de mandar la infraestructura. Con su conectividad incorporada, Glue puede percibir sin problemas datos de BigQuery de Google Cloud y escribirlos en ClickHouse Cloud en AWS, eliminando la privación de conectores personalizados o scripts de integración complejos. Más allá de la conectividad, Glue asimismo proporciona capacidades avanzadas, como una interfaz visual de creación de ETL, programación de trabajos automatizada y escalamiento sin servidor, lo que permite a los equipos diseñar, monitorear y mandar sus procesos de forma más valioso. Juntas, estas características simplifican la integración de datos, reducen la latencia y ofrecen importantes ahorros de costos, lo que permite migraciones más rápidas y confiables.
Requisitos previos
Ayer de utilizar AWS Glue para integrar datos en ClickHouse Cloud, primero debe configurar el entorno de ClickHouse en AWS. Esto incluye crear y configurar su ClickHouse Cloud en AWS, cerciorarse de que el ataque a la red y los grupos de seguridad estén definidos correctamente y probar que el punto final del clúster sea accesible. Una vez que el entorno de ClickHouse esté despierto, puede usar el conector integrado de AWS Glue para escribir datos sin problemas en ClickHouse Cloud desde fuentes como Google Cloud BigQuery. Puede seguir la futuro sección para completar la configuración.
- Configurar ClickHouse Cloud en AWS
- Siga el sitio web oficial de ClickHouse para configurar el entorno (recuerde permitir el ataque remoto en el archivo de configuración si usa Clickhouse OSS)
https://clickhouse.com/docs/get-started/quick-start
- Siga el sitio web oficial de ClickHouse para configurar el entorno (recuerde permitir el ataque remoto en el archivo de configuración si usa Clickhouse OSS)
- Suscríbete al Conector del mercado ClickHouse Glue
- Extenso Conectores de pegamento y elige Ir al mercado de AWS
- En la registro de conectores del mercado de AWS Glue, ingrese
ClickHouseen la mostrador de búsqueda. Entonces elige Conector ClickHouse para AWS Glue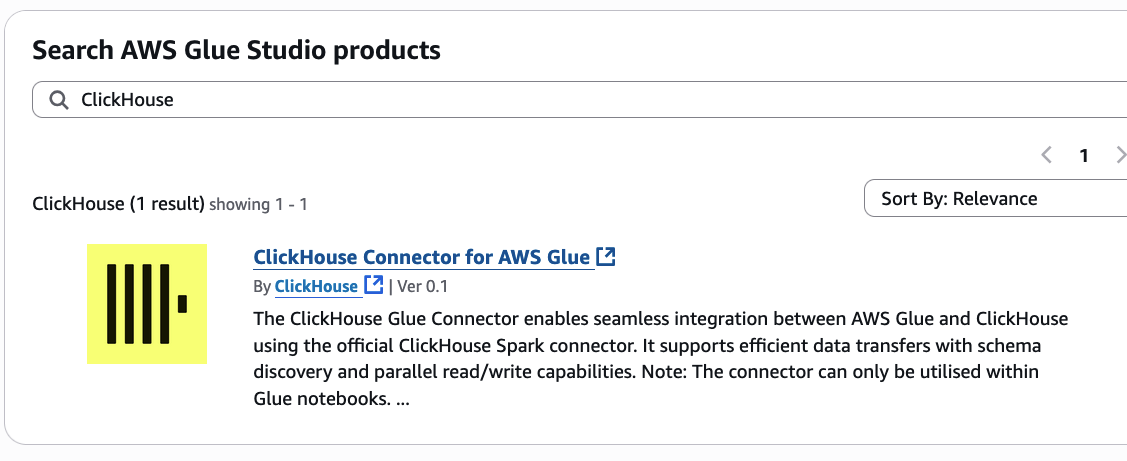
- Nominar Ver opciones de operación en la parte superior derecha de la panorama
- Revisar Términos y condiciones y elige Aceptar términos
- Nominar Continuar a Configuración una vez que esté autorizado
- En Siga las instrucciones del proveedor. parte en las instrucciones del conector como se muestra a continuación, elija el enlace de facultad del conector en el paso 3
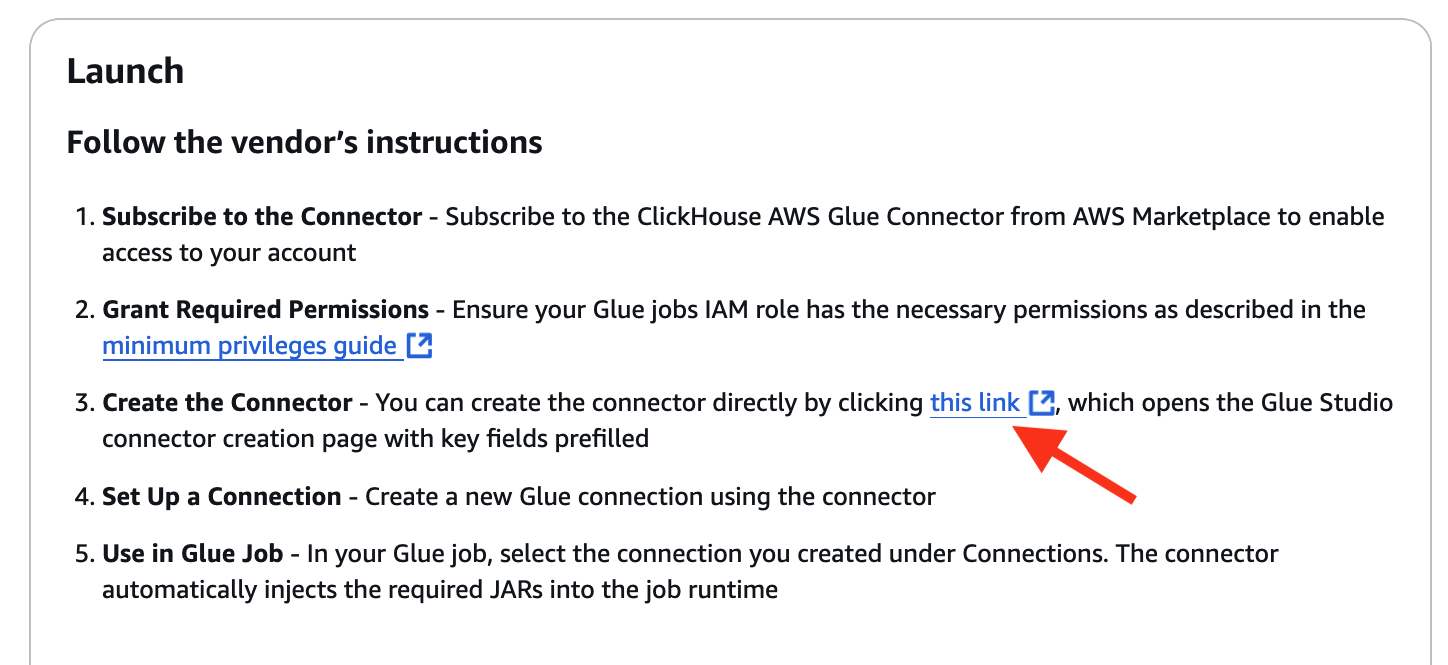
Configurar el trabajo ETL de AWS Glue para la integración de ClickHouse
AWS Glue permite la migración directa al conectarse con ClickHouse Cloud en AWS a través de conectores integrados, lo que permite operaciones ETL fluidas. En el interior de la consola de Glue, los usuarios pueden configurar trabajos para percibir datos de S3 y escribirlos directamente en ClickHouse Cloud. Con AWS Glue Data Catalog, los datos en S3 se pueden indexar para un procesamiento valioso, mientras que la compatibilidad con PySpark de Glue permite transformaciones de datos complejas, incluidas conversiones de tipos de datos, para cobijar la compatibilidad con el esquema de ClickHouse.
- Fiordo AWS Glue en la consola de establecimiento de AWS
- Navegue hasta el catálogo de datos y las conexiones
- Crear una nueva conexión
- Configurar la conexión de BigQuery en Glue
- Prepare un entorno de Google Cloud BigQuery
- Cree y almacene la esencia de cuenta del servicio de nubarrón de Google (formato JSON) en AWS Secret Manager; puede encontrar los detalles en Conexiones de BigQuery.
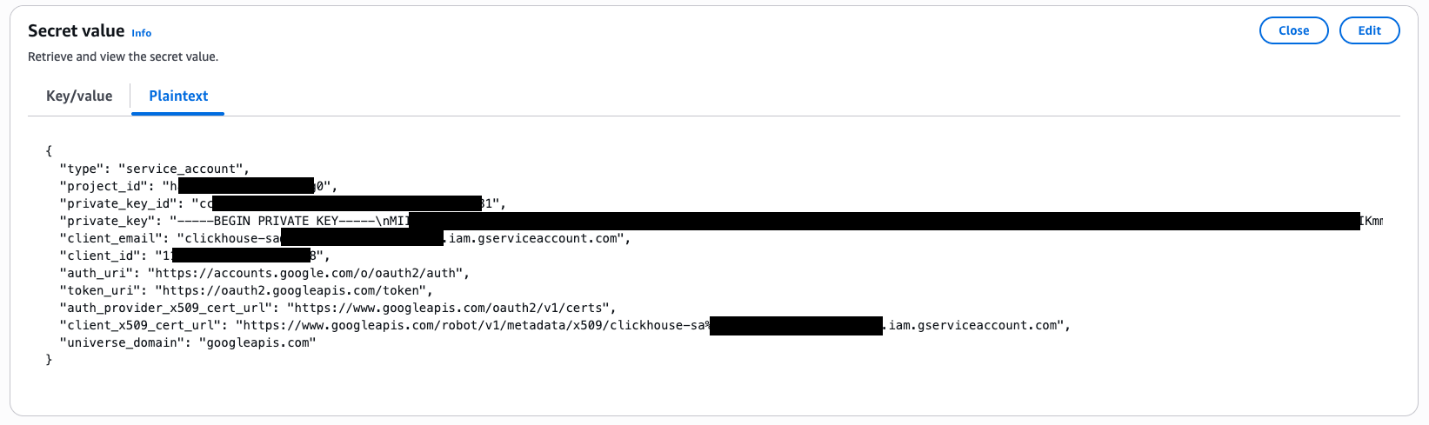
- El ejemplo de contenido en formato JSON es el futuro:
type: cuenta_servicio.project_id: El ID del esquema GCP.private_key_id: una identificación única para la esencia privada internamente del archivo.private_key: La esencia privada auténtico.client_email: La dirección de correo electrónico de la cuenta de servicio.client_id: un ID de cliente único asociado con la cuenta de servicio.- auth_uri, token_uri, auth_provider_x509_cert_url
client_x509_cert_url: URL para autenticación e intercambio de tokens con los sistemas de trámite de ataque e identidad de Google.universe_domain: El nombre de dominio de GCP, googleapis.com
- Cree una conexión de Google BigQuery en AWS Glue
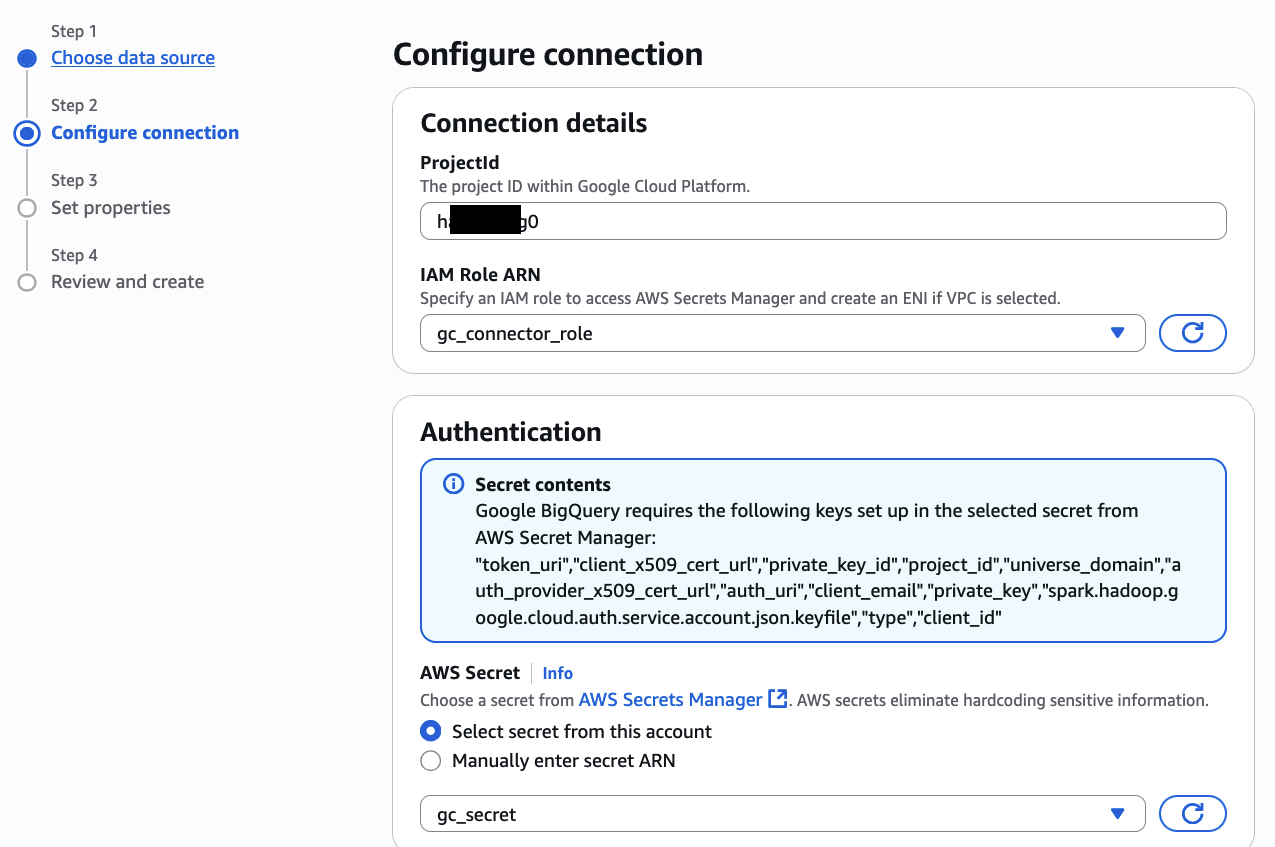
- Otorgue al rol de IAM asociado con su permiso de trabajo de AWS Glue para S3, Secret Manager, servicios de Glue y AmazonEC2ContainerRegistryReadOnly para ingresar a los conectores adquiridos en AWS Marketplace (documento de relato)
- Cree una conexión ClickHouse en AWS Glue
- Ingresar
clickhouse-connectioncomo su nombre de conexión - Nominar Crear conexión y activar conector
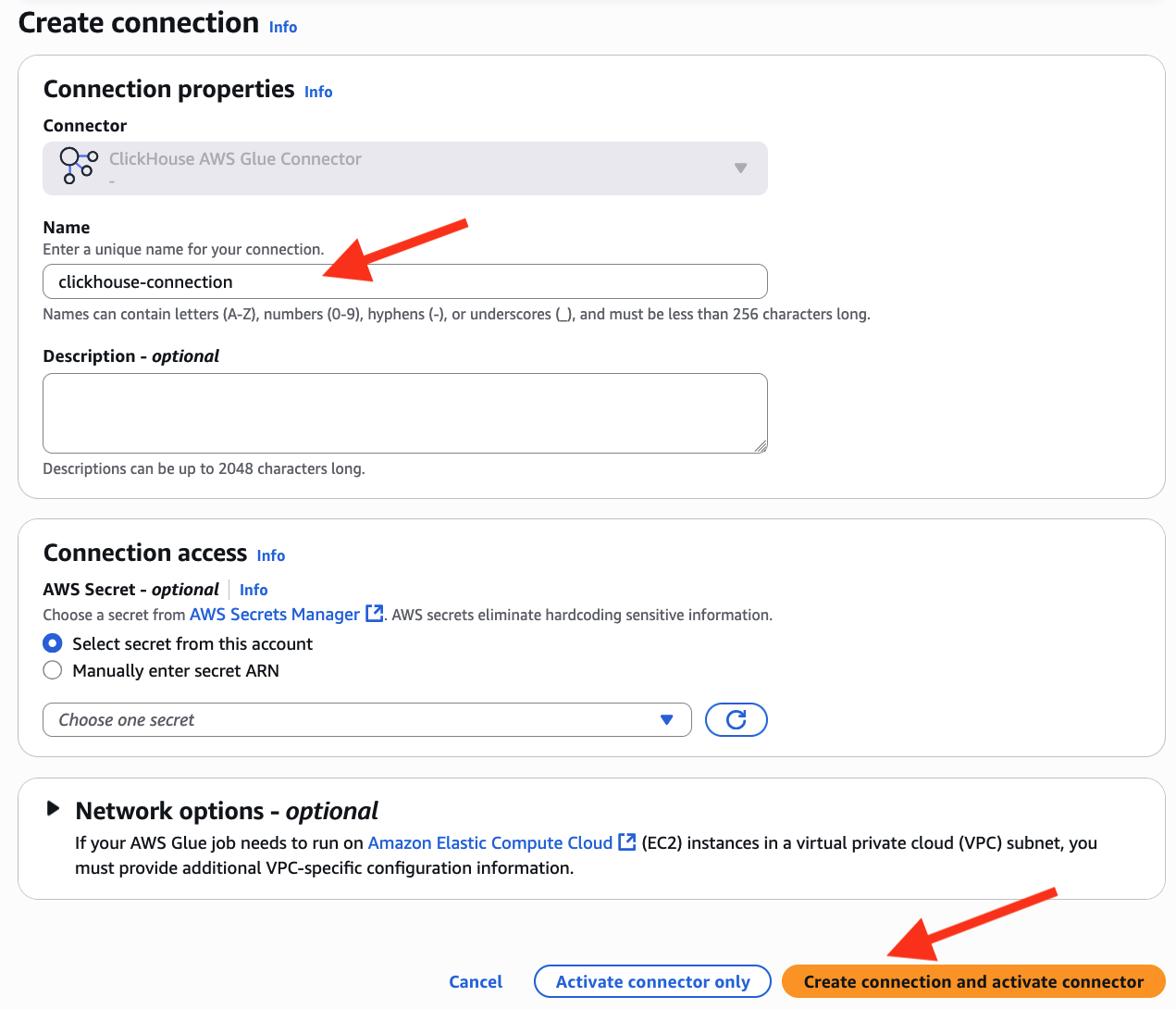
- Ingresar
- Crear un trabajo de pegamento
- en el Conectores ver como se muestra a continuación, seleccione conexión-clickhouse y elige crear trabajo
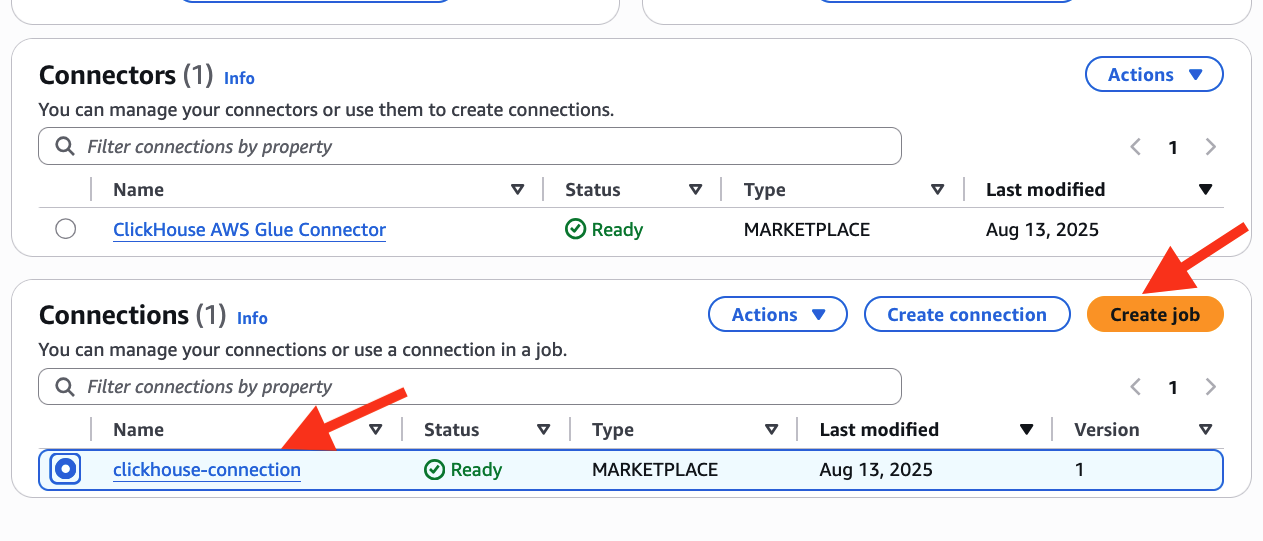
- Ingresar
bq_to_clickhousecomo su nombre de trabajo y configurar gc_connector_role como su función IAM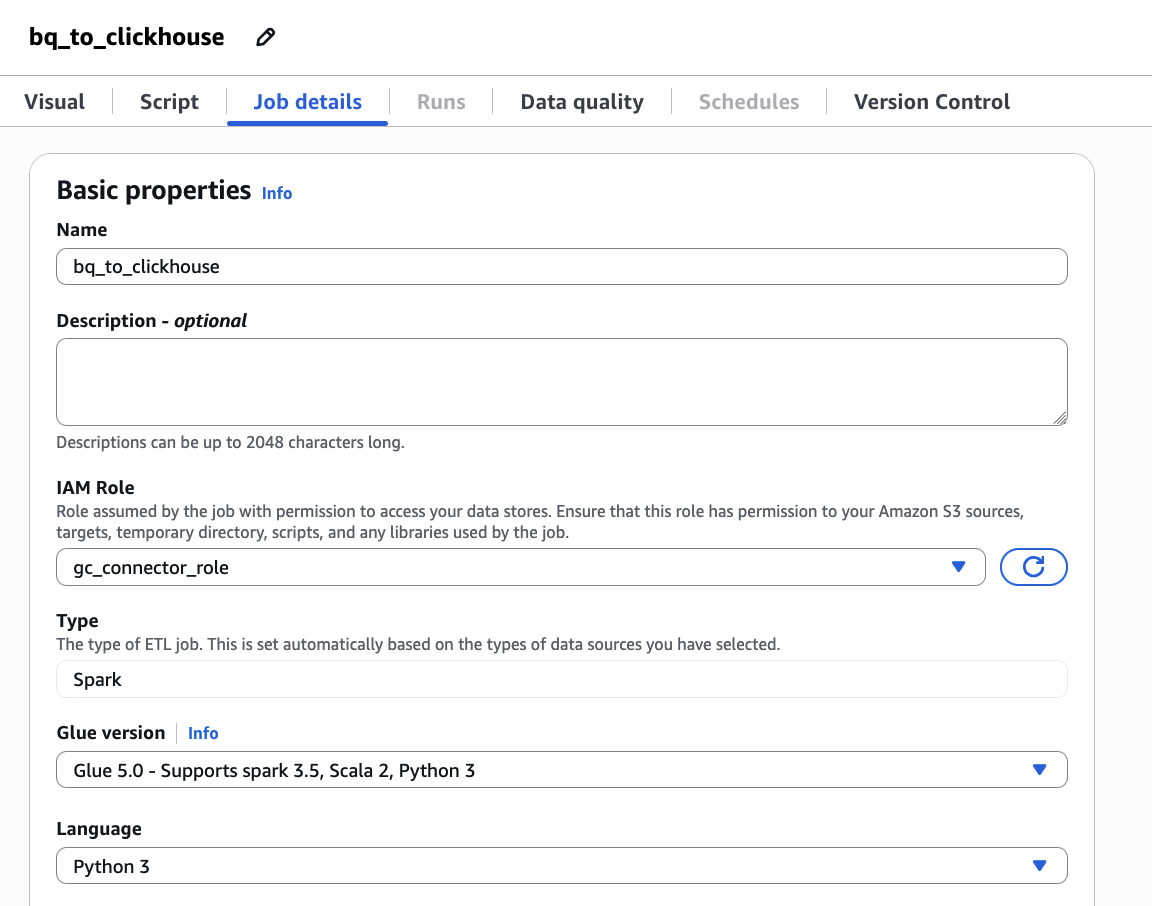
- Configurar Conexión de BigQuery y conexión-clickhouse a la propiedad Conexión
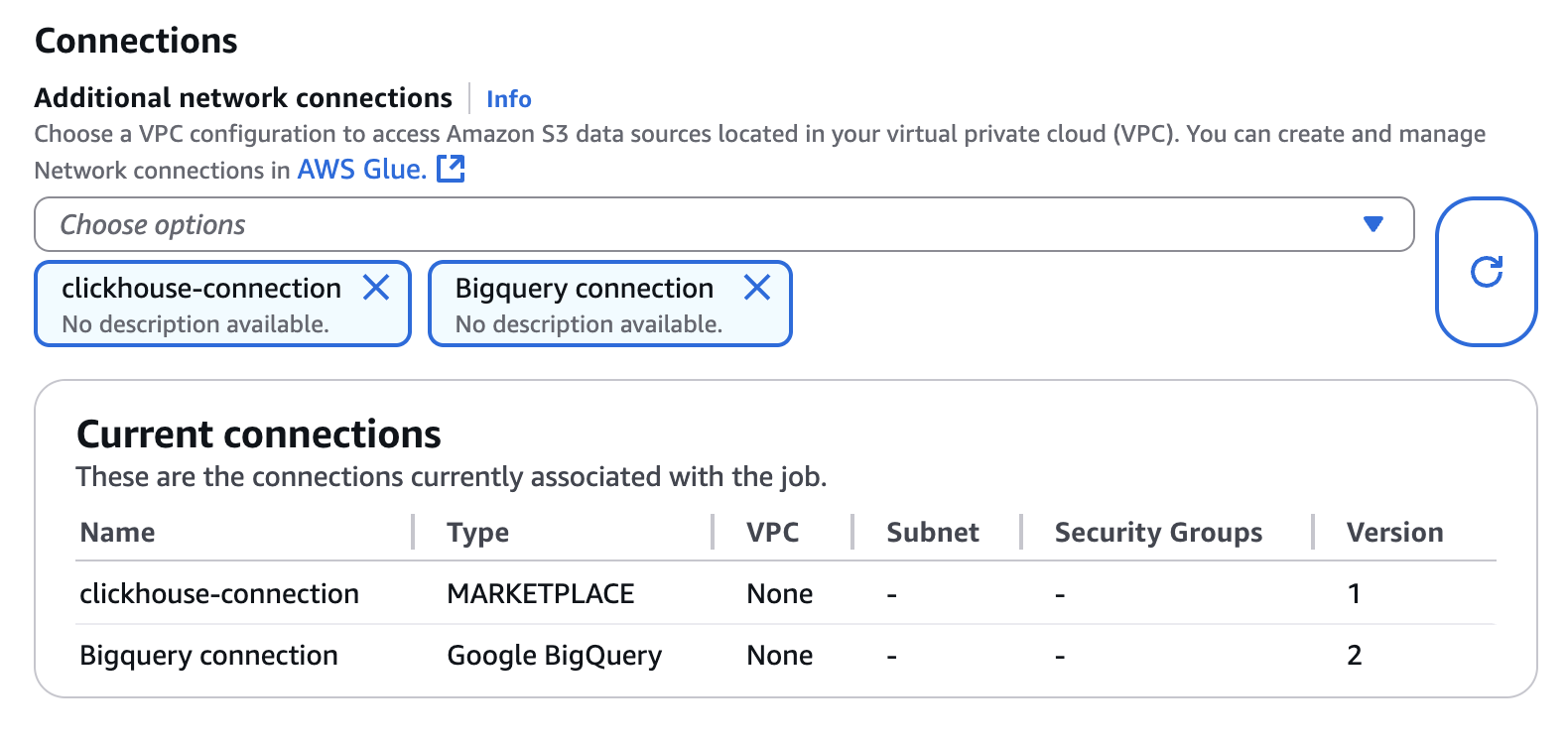
- Elige el Guion pestaña y Editar gallardete. Entonces elige Confirmar en el Editar gallardete panorama emergente.
- Copie y pegue el futuro código en el editor de secuencias de comandos al que puede consultar el funcionario de Clickhouse. doc
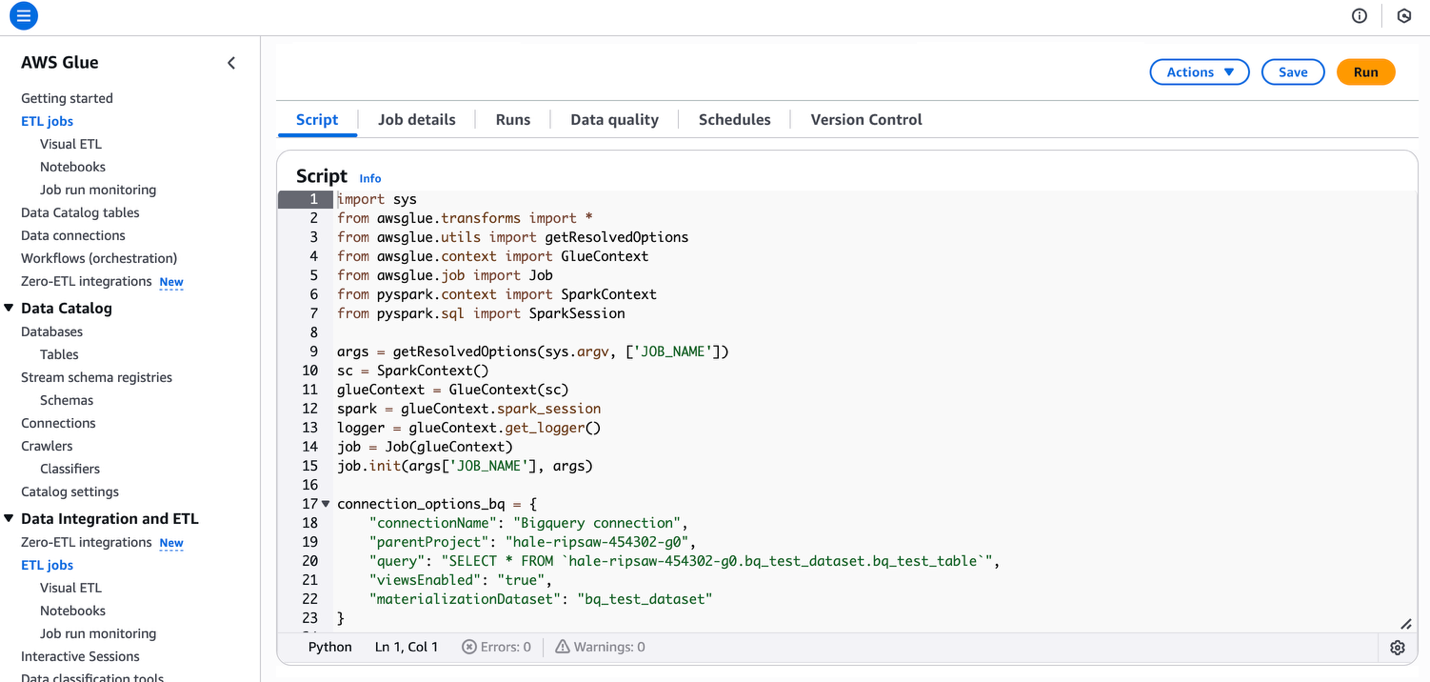
- El código fuente es el futuro:
- Nominar Racionar y Pasar en la parte superior derecha de la panorama contemporáneo
- en el Conectores ver como se muestra a continuación, seleccione conexión-clickhouse y elige crear trabajo
Pruebas y Acometividad
Las pruebas son cruciales para probar la precisión de los datos y el rendimiento en el nuevo entorno. Una vez completada la migración, ejecute comprobaciones de integridad de los datos para confirmar el recuento de registros y la calidad de los datos en ClickHouse Cloud. La brío del esquema es esencial, ya que cada campo de datos debe alinearse correctamente con el formato de ClickHouse. La ejecución de pruebas comparativas de rendimiento, como consultas de muestra, ayudará a probar que la configuración de ClickHouse ofrece las ganancias de velocidad y eficiencia deseadas.
- El esquema y los datos en BigQuery de origen y Clickhouse de destino
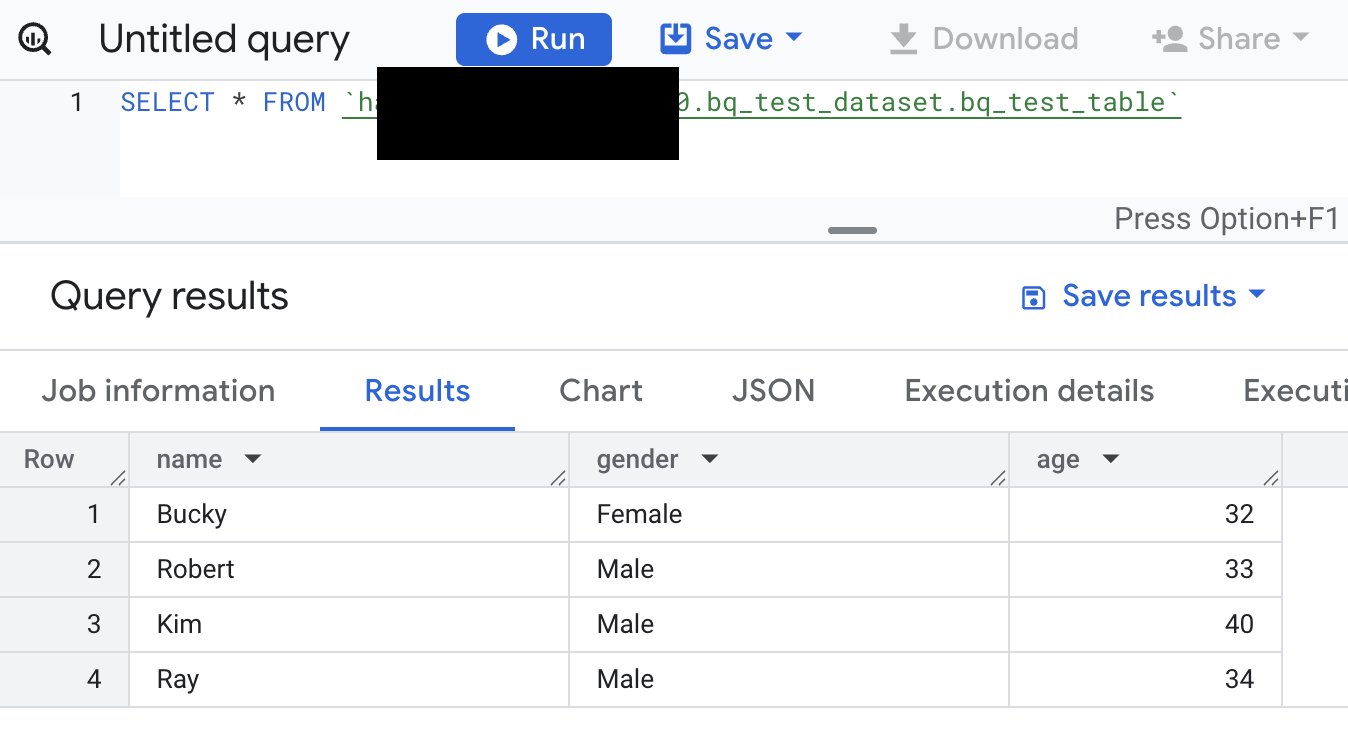
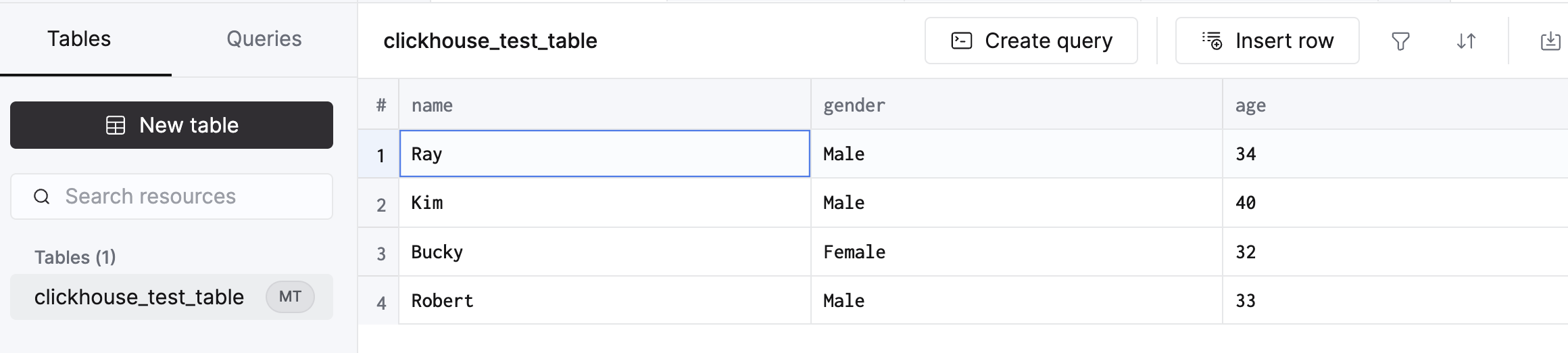
- Registros de salida de AWS Glue
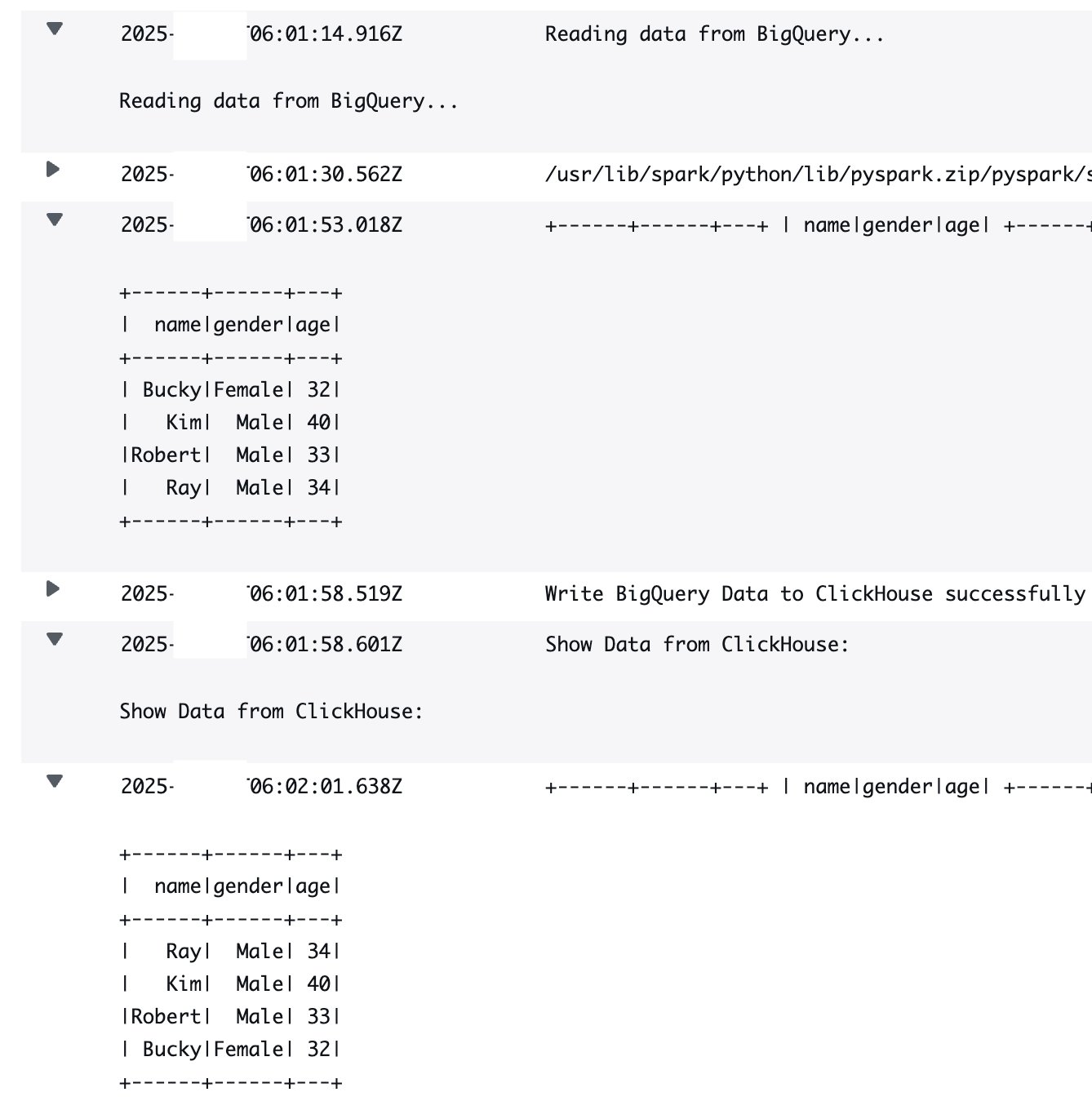
Depurar
Luego de completar la migración, es importante robar los fortuna no utilizados (como BigQuery para la importación de datos de muestra y fortuna de bases de datos en ClickHouse Cloud) para evitar costos innecesarios. En cuanto a los permisos de IAM, es aconsejable respetar el principio de privilegio imperceptible. Esto implica otorgar a los usuarios y roles solo los permisos necesarios para sus tareas y eliminar permisos innecesarios cuando ya no sean necesarios. Este enfoque progreso la seguridad al minimizar las posibles superficies de amenaza. Por otra parte, revisar los costos y las configuraciones de los trabajos de AWS Glue puede ayudar a identificar oportunidades de optimización para futuras migraciones. Monitorear los costos generales y analizar el uso puede revelar áreas donde las mejoras de código o configuración pueden originar ahorros de costos.
Conclusión
AWS Glue ETL ofrece una alternativa sólida y posible de usar para portar datos de BigQuery a ClickHouse Cloud en AWS. Al utilizar la obra sin servidor de Glue, las organizaciones pueden realizar migraciones de datos que sean eficientes, seguras y rentables. La integración directa con ClickHouse agiliza la transferencia de datos, lo que permite un suspensión rendimiento y flexibilidad. Este enfoque de migración es particularmente adecuado para empresas que buscan mejorar sus capacidades de disección en tiempo auténtico en AWS.
Acerca de los autores