
Esta publicación fue coautora de Mike Araujo, ingeniero principal de Medidata Solutions.
La industria de las ciencias biológicas está pasando de herramientas fragmentadas e independientes a soluciones integradas basadas en plataformas. Medidatosuna empresa de Dassault Systèmes, está construyendo una plataforma de datos de próxima coexistentes que aborda los complejos desafíos de la investigación clínica moderna. En esta publicación, le mostramos cómo Medidata creó una plataforma de datos unificada, escalable y en tiempo positivo que brinda servicios a miles de ensayos clínicos en todo el mundo con servicios de AWS. Iceberg apachey una cimentación moderna de casa del albufera.
Desafíos de la cimentación heredada
A medida que se expandió el repositorio de datos clínicos de Medidata, el equipo reconoció las deficiencias de la decisión de datos heredada para proporcionar productos de datos de calidad a sus clientes en su creciente cartera de ofertas de datos. Varios inquilinos de datos comenzaron a erosionarse. El futuro diagrama muestra la cimentación heredada de procedencia, transformación y carga (ETL) de Medidata.
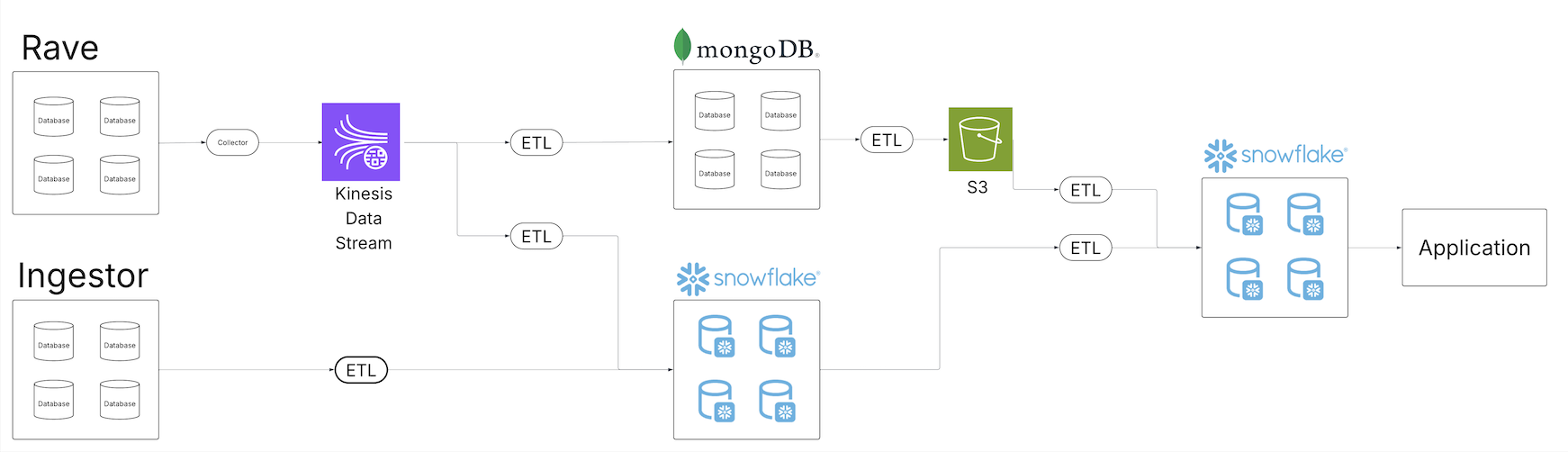
Construido sobre una serie de trabajos por lotes programados, el sistema heredado demostró no estar preparado para proporcionar una horizonte unificada de los datos en todo el ecosistema. Los trabajos por lotes se ejecutaron en diferentes intervalos y, a menudo, requirieron un categoría suficiente de búfer de programación para avalar que los trabajos ascendentes se completaran adentro de la ventana esperada. A medida que el tamaño de datos se expandió, los trabajos y sus cronogramas continuaron inflándose, introduciendo una ventana de latencia entre la ingesta y el procesamiento para los consumidores dependientes. Los diferentes consumidores que operaban desde diversos servicios de datos subyacentes magnificaron aún más el problema, ya que había que construir continuamente canalizaciones a través de una variedad de pilas de entrega de datos.
La creciente cartera de oleoductos comenzó a apurar las operaciones de mantenimiento existentes. Con más operaciones, la oportunidad de fracaso se expandió y los esfuerzos de recuperación se complicaron aún más. Los sistemas de observabilidad existentes se vieron inundados de datos operativos, y identificar la causa raíz de los problemas de calidad de los datos se convirtió en una tarea de varios días. Los aumentos en el tamaño de datos requirieron consideraciones de escalera en todo el conjunto de datos.
Encima, la proliferación de canales de datos y copias de los datos en diferentes tecnologías y sistemas de almacenamiento requirió ampliar los controles de llegada con características de seguridad mejoradas para avalar que solo los usuarios correctos tuvieran llegada al subconjunto de datos a los que se les permitía. Cerciorarse de que los cambios en el control de llegada se propagaran correctamente en todos los sistemas añadió una capa adicional de complejidad para los consumidores y productores.
Descripción caudillo de la decisión
Con la venida de Clinical Data Studio (la decisión unificada de observación y dirección de datos de Medidata para ensayos clínicos) y Data Connect (la decisión de datos de Medidata para apoderarse, variar e cambiar datos de registros médicos electrónicos (EHR) entre organizaciones de atención médica), Medidata introdujo un nuevo mundo de descubrimiento, observación e integración de datos en la industria de las ciencias biológicas impulsado por tecnologías de código franco y alojado en AWS. El futuro diagrama ilustra la cimentación de la decisión.
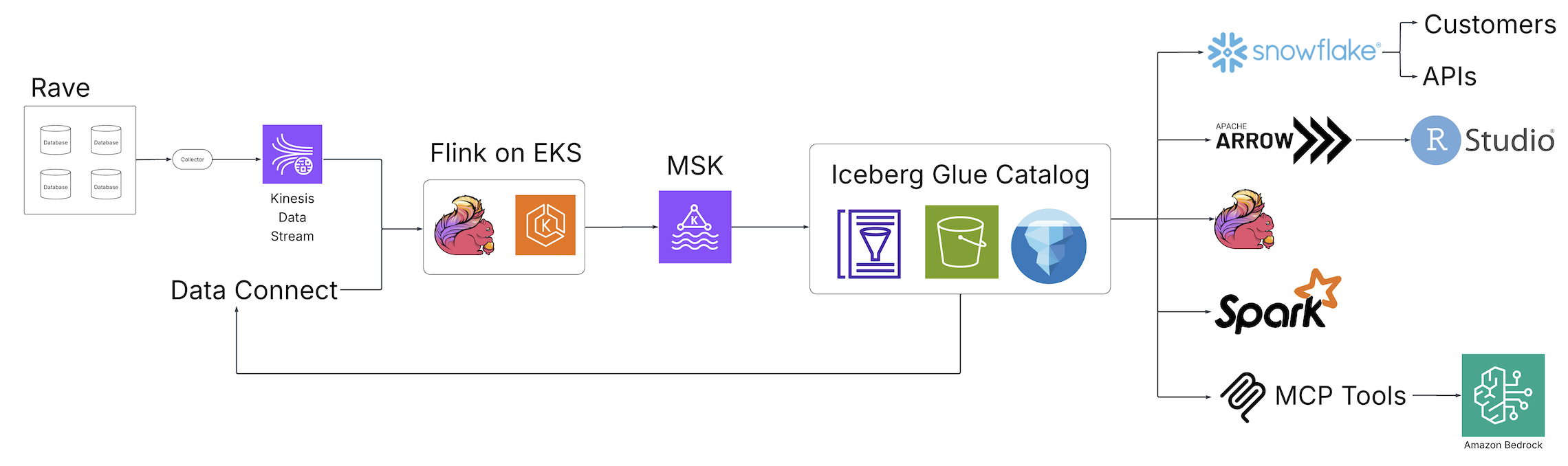
Los trabajos ETL por lotes fragmentados fueron reemplazados por trabajos en tiempo positivo Apache Flink canalizaciones de transmisión, un motor distribuido de código franco para procesamiento con estado y impulsado por Servicio Amazon Elastic Kubernetes (Amazon EKS), un servicio de Kubernetes totalmente ventilado. Los trabajos de Flink escriben en Apache Kafka ejecutándose Apache Kafka administrado por Amazon (Amazon MSK), un servicio de transmisión de datos que administra la infraestructura y las operaciones de Kafka, antaño de aterrizar en las tablas Iceberg respaldadas por Catálogo de datos de AWS Glueun repositorio de metadatos centralizado para activos de datos. A partir de esta colección de tablas Iceberg, una variedad de consumidores ahora puede entrar a una fuente única y central de datos sin procesamiento posterior adicional, lo que alivia la pobreza de canalizaciones personalizadas para satisfacer los requisitos de los consumidores posteriores. A través de estos cambios arquitectónicos fundamentales, el equipo de Medidata resolvió los problemas presentados por la decisión heredada.
Disponibilidad y coherencia de los datos.
Con la preámbulo de los trabajos de Flink y las tablas Iceberg, el equipo pudo ofrecer una horizonte coherente de sus datos en toda la experiencia de datos de Medidata. La latencia de la canalización se redujo de días a minutos, lo que ayudó a los clientes de Medidata a obtener una rendimiento de rendimiento del 99 % desde la ingesta de datos hasta las capas de observación de datos. Conveniente a la interoperabilidad de Iceberg, los usuarios de Medidata vieron la misma horizonte de los datos independientemente de dónde los vieran, minimizando la pobreza de canalizaciones personalizadas impulsadas por el consumidor porque Iceberg podía conectarse a los consumidores existentes.
Mantenimiento y durabilidad
La interoperabilidad de Iceberg proporcionó una única copia de los datos para satisfacer sus casos de uso, de modo que el equipo de Medidata pudo centrar sus esfuerzos de observación y mantenimiento en un subconjunto de operaciones cinco veces más pequeño de lo que se requería anteriormente. La observabilidad se mejoró aprovechando los diversos componentes de metadatos y métricas expuestos por Iceberg y el Catálogo de datos. La dirección de calidad se transformó de seguimientos y consultas entre sistemas a un observación único de canalizaciones unificadas, con el beneficio adicional de consultas de datos puntuales gracias a la Función de instantánea de iceberg. Los aumentos del tamaño de datos se manejan con un escalado perspicaz para usar respaldado por toda la infraestructura y las características de optimización de AWS Glue Iceberg que incluyen compactación, retención de instantáneasy asesinato de archivos huérfanosque brindan una experiencia de configurar y olvidar para resolver una serie de frustraciones comunes de Iceberg, como el problema de los archivos pequeños, la retención de archivos huérfanos y el rendimiento de las consultas.
Seguridad
Con Iceberg en el centro de su cimentación de decisión, el equipo de Medidata ya no tuvo que ofrendar tiempo a crear capas de control de llegada personalizadas con funciones de seguridad mejoradas en cada punto de integración de datos. Iceberg en AWS centraliza la capa de autorización utilizando sistemas familiares como Administración de llegada e identidad de AWS (IAM), proporcionando un control único y duradero para el llegada a los datos. Los datos igualmente permanecen completamente adentro de la abundancia privada potencial (VPC) de Medidata, lo que reduce aún más la oportunidad de divulgaciones no deseadas.
Conclusión
En esta publicación, demostramos cómo el universo heredado de canalizaciones ETL personalizadas impulsadas por el consumidor se puede reemplazar con lagos de transmisión escalables y de parada rendimiento. Al colocar Iceberg en AWS en el centro de las operaciones de datos, puede tener una única fuente de datos para sus consumidores.
Para obtener más información sobre Iceberg en AWS, consulte Optimización de tablas Iceberg y Usando Apache Iceberg en AWS.
Sobre los autores