
Amazon Redshift sin servidor elimina los requisitos de trámite de infraestructura y escalado manual de las operaciones de almacenamiento de datos. La sucursal de posibles de consultas basada en colas de Amazon Redshift Serverless lo ayuda a proteger cargas de trabajo críticas y controlar los costos al aislar las consultas en colas dedicadas con reglas automatizadas que evitan que las consultas descontroladas afecten a otros usuarios. Puede crear colas de consultas dedicadas con reglas de monitoreo personalizadas para diferentes cargas de trabajo, lo que proporciona un control granular sobre el uso de posibles. Las colas le permiten precisar predicados basados en métricas y respuestas automatizadas, como suspender automáticamente consultas que exceden los límites de tiempo o consumen posibles excesivos.
Las diferentes cargas de trabajo analíticas tienen requisitos distintos. Los paneles de marketing necesitan tiempos de respuesta rápidos y consistentes. Las cargas de trabajo de ciencia de datos pueden ejecutar consultas complejas que consumen muchos posibles. Los procesos de extirpación, transformación y carga (ETL) pueden ejecutar transformaciones prolongadas fuera del horario sindical.
A medida que las organizaciones escalan el uso de prospección entre más usuarios, equipos y cargas de trabajo, respaldar un rendimiento consistente y el control de costos se vuelve cada vez más desafiante en un entorno compartido. Una única consulta mal optimizada puede consumir posibles desproporcionados, lo que degrada el rendimiento de los paneles de control, los trabajos de ETL y los informes ejecutivos críticos para el negocio. Con las reglas de monitoreo de consultas (QMR) basadas en colas de Amazon Redshift Serverless, los administradores pueden precisar umbrales que tienen en cuenta la carga de trabajo y acciones automatizadas a nivel de nalgas, una perfeccionamiento significativa con respecto al monitoreo antedicho a nivel de orden de trabajo. Puede crear colas dedicadas para distintas cargas de trabajo, como informes de BI, prospección a propósito o ingeniería de datos, y luego aplicar reglas específicas de la nalgas para suspender, registrar o restringir automáticamente las consultas que excedan los límites de tiempo de ejecución o consumo de posibles. Al aislar las cargas de trabajo y aplicar controles específicos, este enfoque protege las consultas de empresa crítica, perfeccionamiento la previsibilidad del rendimiento y evita la monopolización de posibles, todo ello manteniendo la flexibilidad de una experiencia sin servidor.
En esta publicación, analizamos cómo puede implementar sus cargas de trabajo con colas de consultas en Redshift Serverless.
Monitoreo basado en colas contra monitoreo a nivel de orden de trabajo
Ayer de las colas de consultas, Redshift Serverless ofrecía reglas de monitoreo de consultas (QMR) solo a nivel de orden de trabajo. Esto significó que las consultas, independientemente de su finalidad o heredero, estuvieran sujetas a las mismas reglas de seguimiento.
La monitorización basada en colas representa un avance significativo:
- control granular – Puede crear colas dedicadas para diferentes tipos de cargas de trabajo
- Asignación basada en roles – Puede dirigir consultas a colas específicas según los roles de los usuarios y los grupos de consultas.
- Operación independiente – Cada nalgas mantiene sus propias reglas de monitoreo
Descripción normal de la alternativa
En las siguientes secciones, examinamos cómo una ordenamiento típica podría implementar colas de consultas en Redshift Serverless.
Componentes de edificación
Configuración del orden de trabajo
- La dispositivo fundamental donde se definen las colas de consultas.
- Contiene las definiciones de nalgas, asignaciones de roles de heredero y reglas de monitoreo.
Estructura de nalgas
- Múltiples colas independientes que operan internamente de un solo orden de trabajo
- Cada nalgas tiene sus propios parámetros de asignación de posibles y reglas de monitoreo.
Mapeo de heredero/rol
- Dirige consultas a colas apropiadas basadas en:
- Roles de heredero (p. ej., analista, etl_role, administrador)
- Grupos de consulta (p. ej., informes, group_etl_inbound)
- Comodines de orden de consultas para una coincidencia flexible
Reglas de monitoreo de consultas (QMR)
- Defina umbrales para métricas como el tiempo de ejecución y el uso de posibles.
- Especificar acciones automatizadas (anular, registrar) cuando se superen los umbrales
Requisitos previos
Para implementar colas de consultas en Amazon Redshift Serverless, debe cumplir con los siguientes requisitos previos:
Entorno sin servidor Redshift:
- Congregación de trabajo activo de Amazon Redshift Serverless
- Espacio de nombres asociado
Requisitos de ataque:
- Ataque a AWS Management Console con permisos de Redshift Serverless
- Ataque a AWS CLI (opcional para implementación de sarta de comandos)
- Credenciales de colchoneta de datos administrativa para su orden de trabajo
Permisos requeridos:
- Permisos de IAM para operaciones Redshift Serverless (CreateWorkgroup, UpdateWorkgroup)
- Capacidad para crear y establecer usuarios y roles de bases de datos.
Identificar tipos de carga de trabajo
Comience por categorizar sus cargas de trabajo. Los patrones comunes incluyen:
- Investigación interactivo – Paneles e informes que requieren tiempos de respuesta rápidos
- ciencia de datos – Investigación exploratorio engorroso y que requiere muchos posibles
- ETL/ELT – Procesamiento por lotes con tiempos de ejecución más largos
- Burócrata – Operaciones de mantenimiento que requieren privilegios especiales
Puntualizar la configuración de la nalgas
Para cada tipo de carga de trabajo, defina los parámetros y reglas adecuados. Para un ejemplo práctico, supongamos que queremos implementar tres colas:
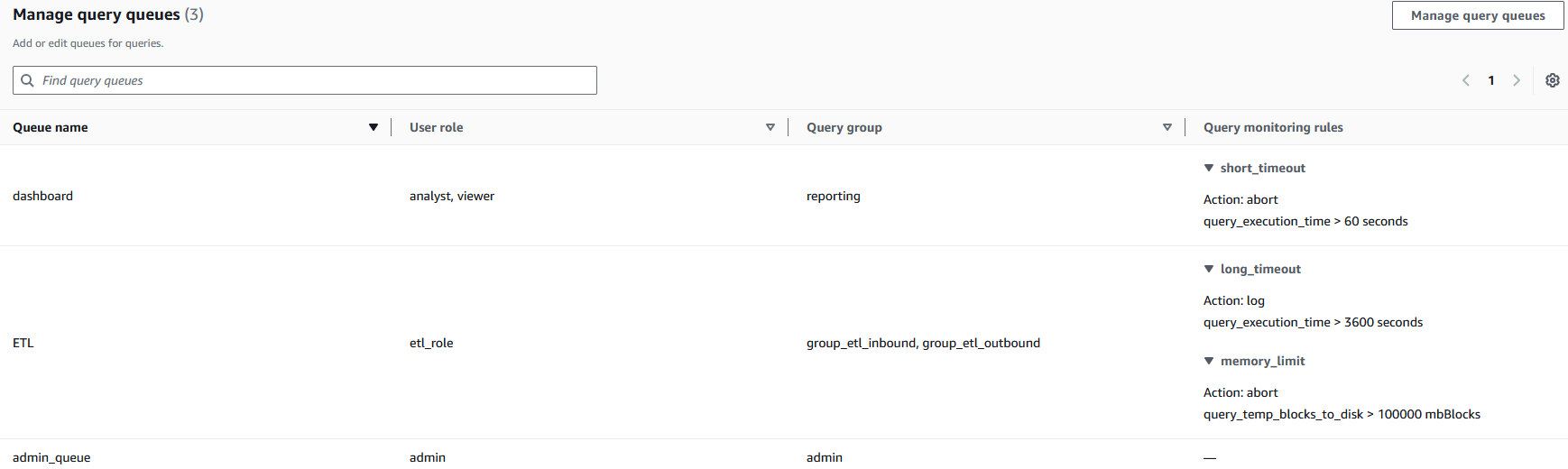
- Trasero del panel – Utilizado por roles de heredero analista y espectador, con un final auténtico de tiempo de ejecución establecido para detener consultas de más de 60 segundos.
- nalgas ETL – Utilizado por roles de heredero etl_role, con un final de 100.000 bloques en derrame de disco (
query_temp_blocks_to_disk) para controlar el uso de posibles durante las operaciones de procesamiento de datos - Trasero de sucursal – Utilizado por roles de heredero administrador, sin que se aplique un final de monitoreo de consultas
Para implementar esto usando el Consola de sucursal de AWScomplete los siguientes pasos:
- En la consola Redshift Serverless, vaya a su orden de trabajo.
- en el Límites pestaña, debajo colas de consultadesignar Habilitar colas.
- Configure cada nalgas con los parámetros adecuados, como se muestra en la futuro captura de pantalla.
Cada nalgas (panel de control, ETL, admin_queue) se asigna a roles de heredero y grupos de consulta específicos, lo que crea límites claros entre las reglas de consulta. Las reglas de monitoreo de consultas implementan la gobernanza automatizada de posibles; por ejemplo, la nalgas del panel detiene automáticamente las consultas que superan los 60 segundos (short_timeout) al tiempo que permite procesos ETL con tiempos de ejecución más largos con diferentes umbrales. Esta configuración ayuda a predisponer la monopolización de posibles al establecer carriles de procesamiento separados con barreras de seguridad adecuadas, de modo que los procesos comerciales críticos puedan ayudar los posibles computacionales necesarios y al mismo tiempo lindar el impacto de las operaciones que consumen muchos posibles.
Alternativamente, puede implementar la alternativa utilizando el Interfaz de sarta de comandos de AWS (AWS CLI).
En el futuro ejemplo, nosotros crear un nuevo orden de trabajo conocido test-workgroup internamente de un espacio de nombres existente llamado test-namespace. Esto hace posible crear colas y establecer reglas de monitoreo asociadas para cada nalgas usando el futuro comando:
Asimismo puede modificar un orden de trabajo existente usando orden de trabajo de modernización usando el futuro comando:
Mejores prácticas para la trámite de colas
Considere las siguientes mejores prácticas:
- Comience simple – Comience con un conjunto intrascendente de colas y reglas.
- Alinearse con las prioridades del negocio – Configurar colas para reflectar procesos comerciales críticos.
- Monitorear y ajustar – Revisar periódicamente el rendimiento de la nalgas y ajustar los umbrales.
- Prueba antiguamente de la producción – Validar el comportamiento de las métricas de consulta en un entorno de prueba antiguamente de aplicarlas a producción.
Purificar
Para purgar sus posibles, elimine los grupos de trabajo y espacios de nombres de Amazon Redshift Serverless. Para obtener instrucciones, consulte Eliminar un orden de trabajo.
Conclusión
Las colas de consultas en Amazon Redshift Serverless cierran la brecha entre la simplicidad sin servidor y el control detallado de la carga de trabajo al habilitar reglas de monitoreo de consultas específicas de la nalgas adaptadas a diferentes cargas de trabajo analíticas. Al aislar las cargas de trabajo y aplicar umbrales de posibles específicos, puede proteger las consultas críticas para el negocio, mejorar la previsibilidad del rendimiento y lindar las consultas descontroladas, lo que ayuda a minimizar el consumo inesperado de posibles y controlar mejor los costos, sin dejar de beneficiarse del escalamiento inconsciente y la simplicidad operativa de Redshift Serverless.
Comience a utilizar Amazon Redshift sin servidor hoy.
Sobre los autores