
Los canales declarativos brindan a los equipos una forma basada en la intención de crear flujos de trabajo por lotes y de transmisión. Usted define lo que debe suceder y deja que el sistema administre la ejecución. Esto reduce el código personalizado y admite patrones de ingeniería repetibles.
A medida que crece el uso de datos de las organizaciones, las canalizaciones se multiplican. Los estándares evolucionan, se agregan nuevas fuentes y más equipos participan en el avance. Incluso las pequeñas actualizaciones de esquemas se extienden a docenas de portátiles y configuraciones. La metaprogramación basada en metadatos aborda estos problemas cambiando la deducción de canalización a plantillas estructuradas que se generan en tiempo de ejecución.
Este enfoque mantiene el avance consistente, reduce el mantenimiento y escalera con un esfuerzo de ingeniería establecido.
En este blog, aprenderá cómo crear canalizaciones basadas en metadatos para Spark Declarative Pipelines mediante DLT-META, un tesina de Databricks Labs, que aplica plantillas de metadatos para automatizar la creación de canalizaciones.
Por muy enseres que sean los canalizaciones declarativas, el trabajo necesario para respaldarlos aumenta rápidamente cuando los equipos agregan más fuentes y amplían su uso en toda la estructura.
Por qué las canalizaciones manuales son difíciles de perseverar a escalera
Las canalizaciones manuales funcionan a pequeña escalera, pero el esfuerzo de mantenimiento crece más rápido que los datos mismos. Cada nueva fuente añade complejidad, lo que lleva a desvíos y reelaboraciones de la deducción. Los equipos terminan parcheando los canales en espacio de mejorarlos. Los ingenieros de datos enfrentan constantemente estos desafíos de escalera:
- Demasiados artefactos por fuente: Cada conjunto de datos requiere nuevos cuadernos, configuraciones y scripts. Los gastos operativos aumentan rápidamente con cada feed incorporado.
- Las actualizaciones lógicas no se propagan: Los cambios en las reglas comerciales no se aplican a las canalizaciones, lo que genera cambios en la configuración y resultados inconsistentes entre las canalizaciones.
- Calidad y gobernanza inconsistentes: Los equipos crean controles y linajes personalizados, lo que dificulta la aplicación de estándares en toda la estructura y los resultados son muy variables.
- Contribución segura limitada de los equipos de dominio: Los analistas y equipos comerciales quieren asociar datos; sin confiscación, la ingeniería de datos aún revisa o reescribe la deducción, lo que ralentiza la entrega.
- El mantenimiento se multiplica con cada cambio: Los ajustes o actualizaciones simples del esquema crean una enorme acumulación de trabajo manual en todos los canales dependientes, lo que detiene la agilidad de la plataforma.
Estos problemas muestran por qué es importante un enfoque que dé prioridad a los metadatos. Reduce el esfuerzo manual y mantiene las canalizaciones consistentes a medida que escalan.
Cómo DLT-META aborda la escalera y la coherencia
DLT-META resuelve problemas de consistencia y escalera de canalización. Es un ámbito de metaprogramación basado en metadatos para Spark Declarative Pipelines. Los equipos de datos lo utilizan para automatizar la creación de canales, estandarizar la deducción y subir el avance con un código insignificante.
Con la metaprogramación, el comportamiento de la canalización se deriva de la configuración, en espacio de cuadernos repetidos. Esto brinda a los equipos beneficios claros.
- Menos código para escribir y perseverar
- Incorporación más rápida de nuevas fuentes de datos
- Tuberías listas para producción desde el principio
- Patrones consistentes en toda la plataforma
- Mejores prácticas escalables con equipos lean
Spark Declarative Pipelines y DLT-META trabajan juntos. Spark Declarative Pipelines define la intención y gestiona la ejecución. DLT-META agrega una capa de configuración que genera y escalera la deducción de canalización. Combinados, reemplazan la codificación manual con patrones repetibles que respaldan la gobernanza, la eficiencia y el crecimiento a escalera.
Cómo DLT-META aborda las deposición reales de ingeniería de datos
1. Configuración centralizada y basada en plantillas
DLT-META centraliza la deducción de canalización en plantillas compartidas para eliminar la duplicación y el mantenimiento manual. Los equipos definen reglas de ingesta, transformación, calidad y gobernanza en metadatos compartidos mediante JSON o YAML. Cuando se agrega una nueva fuente o cambia una regla, los equipos actualizan la configuración una vez. La deducción se propaga automáticamente a través de las tuberías.
2. Escalabilidad instantánea e incorporación más rápida
Las actualizaciones basadas en metadatos facilitan la ampliación de los canales y la incorporación de nuevas fuentes. Los equipos agregan fuentes o ajustan las reglas comerciales editando archivos de metadatos. Los cambios se aplican a todas las cargas de trabajo posteriores sin intervención manual. Las nuevas fuentes pasan a producción en minutos en espacio de semanas.
3. Contribución del equipo de dominio con estándares aplicados
DLT-META permite a los equipos de dominio contribuir de forma segura a través de la configuración. Los analistas y expertos en el dominio actualizan los metadatos para acelerar la entrega. Los equipos de plataforma e ingeniería mantienen el control sobre la acometividad, la calidad de los datos, las transformaciones y las reglas de cumplimiento.
4. Coherencia y gobernanza en toda la empresa
Los estándares de toda la estructura se aplican automáticamente en todos los canales y consumidores. La configuración central aplica una deducción coherente para cada nueva fuente. Las reglas integradas de auditoría, categoría y calidad de datos respaldan los requisitos regulatorios y operativos a escalera.
Cómo los equipos utilizan DLT-META en la experiencia
Los clientes utilizan DLT-META para fijar la ingesta y las transformaciones una vez y aplicarlas mediante la configuración. Esto reduce el código personalizado y acelera la incorporación.
Cineplex vio un impacto inmediato.
Usamos DLT-META para minimizar el código personalizado. Los ingenieros ya no escriben canalizaciones de modo diferente para tareas simples. La incorporación de archivos JSON aplica un ámbito coherente y se encarga del resto.— Aditya Singh, ingeniero de datos, Cineplex
PsiQuantum muestra cómo los equipos pequeños escalan de modo apto.
DLT-META nos ayuda a diligenciar cargas de trabajo bronce y plata con bajo mantenimiento. Admite grandes volúmenes de datos sin cuadernos ni código fuente duplicados.— Arthur Valadares, ingeniero principal de datos, PsiQuantum
En todas las industrias, los equipos aplican el mismo patrón.
- Minorista centraliza los datos de la tienda y la esclavitud de suministro de cientos de fuentes
- Abastecimiento estandariza la ingesta por lotes y streaming para IoT y datos de flotas
- Servicios financieros aplica la auditoría y el cumplimiento mientras la incorporación de feeds es más rápida
- Cuidado de la lozanía mantiene la calidad y la auditabilidad en conjuntos de datos complejos
- Manufactura y telecomunicaciones subir la ingesta utilizando metadatos reutilizables y gobernados centralmente
Este enfoque permite a los equipos aumentar el número de canales sin aumentar la complejidad.
Cómo comenzar con DLT-META en 5 sencillos pasos
No necesita rediseñar su plataforma para probar DLT-META. Comienzo poco a poco. Utilice algunas fuentes. Deje que los metadatos impulsen el resto.
1. Obtén el ámbito
Comience clonando el repositorio DLT-META. Esto le brinda las plantillas, ejemplos y herramientas necesarias para fijar canalizaciones utilizando metadatos.
2. Defina sus canalizaciones con metadatos
A continuación, defina qué deben hacer sus canalizaciones. Para ello, edite un pequeño conjunto de archivos de configuración.
- Usar conf/incorporación.json para describir tablas de entrada sin formato.
- Usar conf/silver_transformations.json para fijar transformaciones.
- Opcionalmente, agregue conf/dq_rules.json si desea hacer cumplir las reglas de calidad de los datos.
En este punto, estás describiendo la intención. No estás escribiendo código de canalización.
3. Incorporar metadatos en la plataforma.
Antiguamente de que se puedan ejecutar las canalizaciones, DLT-META debe registrar sus metadatos. Este paso de incorporación convierte sus configuraciones en tablas delta de especificaciones de flujo de datos que las canalizaciones leen en tiempo de ejecución.
Puede ejecutar la incorporación desde una computadora portátil, un trabajo de Lakeflow o la CLI DLT-META.
a. Incorporación manual a través de una computadora portátil, por ejemplo aquí
Utilice el cuaderno de incorporación proporcionado para procesar sus metadatos y aprovisionar los artefactos de su canalización:
b. Automatice la incorporación a través de Lakeflow Jobs con una rueda de Python.
El subsiguiente ejemplo muestra la interfaz de adjudicatario de Lakeflow Jobs para crear y automatizar una canalización DLT-META.
do. Incorporación mediante los comandos DLT-META CLI que se muestran en el repositorio: aquí.
La CLI DLT-META le permite ejecutarla integrada e implementarla en una terminal Python interactiva
4. Cree una canalización genérica
Con los metadatos implementados, se crea una única canalización genérica. Esta canalización lee las tablas de Dataflowspec y genera deducción dinámicamente.
Usar tuberías/dlt_meta_pipeline.py como punto de entrada y configúrelo para que haga remisión a sus especificaciones de bronce y plata.
Esta canalización permanece sin cambios a medida que agrega fuentes. Los metadatos controlan el comportamiento.
5. Disparar y ejecutar
Ahora está despierto para ejecutar la canalización. Actívelo como cualquier otro canal declarativo de Spark.
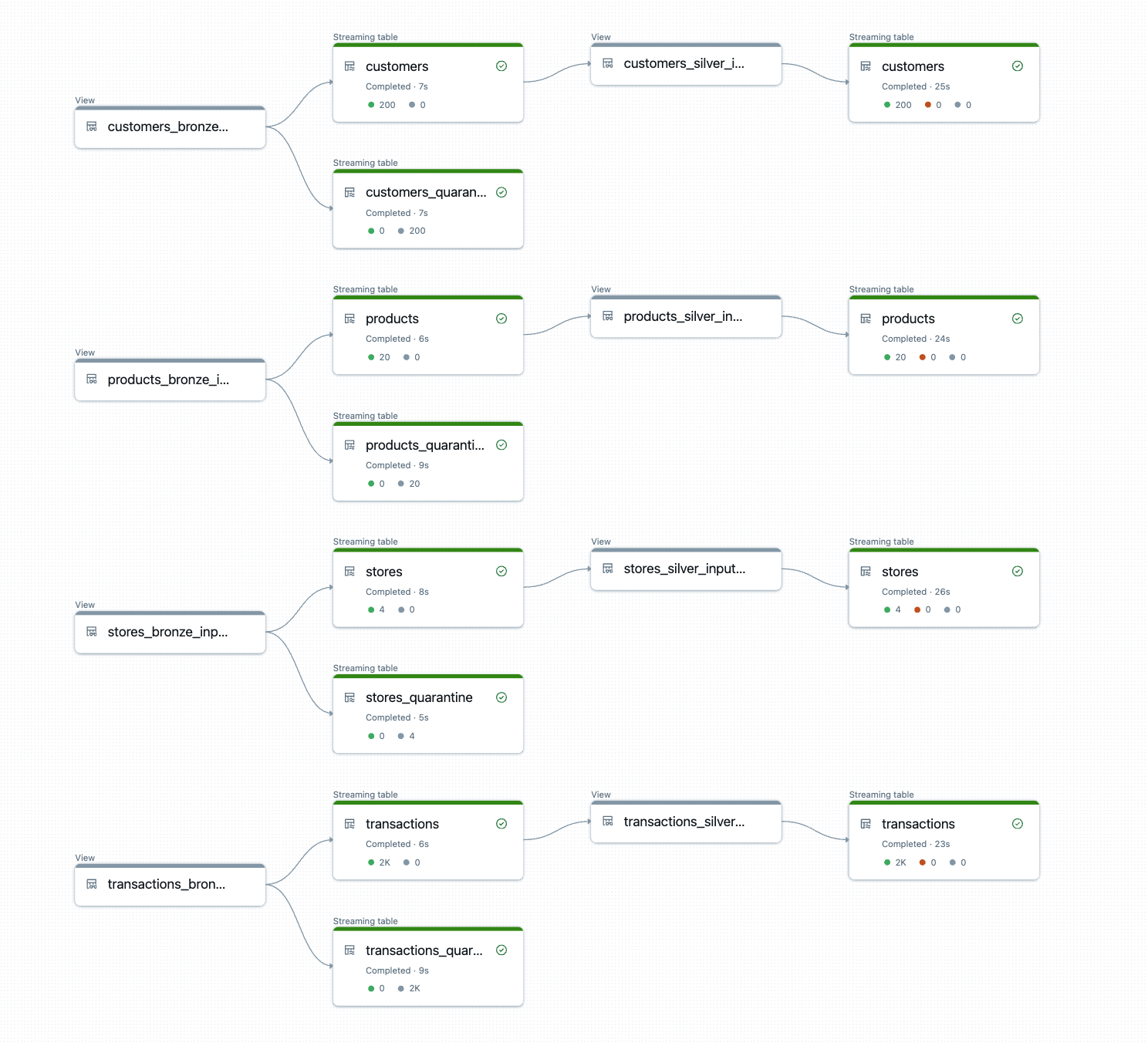
DLT-META crea y ejecuta la deducción de canalización en tiempo de ejecución.
El resultado son mesas de bronce y plata listas para producción con transformaciones consistentes, reglas de calidad y categoría aplicados automáticamente.
Pruébalo hoy
Para comenzar, recomendamos iniciar una prueba de concepto utilizando sus Spark Declarative Pipelines existentes con un puñado de fuentes, portar la deducción de la canalización a metadatos y dejar que DLT-META se orqueste a escalera. Comience con una pequeña prueba de concepto y observe cómo la metaprogramación basada en metadatos amplía sus capacidades de ingeniería de datos más allá de lo que creía posible.
Posibles de ladrillos de datos