
En los últimos abriles, hemos sido testigos de un cambio significativo en la forma en que las empresas gestionan y analizan sus lagos de datos en constante crecimiento. A la vanguardia de esta transformación está Iceberg apacheun formato de tabla abierta que está ganando contorno rápidamente entre los consumidores de datos a gran escalera.
Sin secuestro, a medida que las empresas amplían sus implementaciones de lagos de datos, administrar estas tablas Iceberg a escalera se vuelve un desafío. Los equipos de datos a menudo necesitan administrar la desarrollo del esquema de la tabla, su partición y las versiones de las instantáneas. La automatización agiliza estas operaciones, proporciona coherencia, reduce el error humano y ayuda a los equipos de datos a centrarse en tareas de longevo valencia.
El Pegamento AWS Catálogo de datos ahora admite la mandato de tablas Iceberg utilizando el API de pegamento de AWS, SDK de AWSy Formación en la estrato de AWS. Anteriormente, los usuarios tenían que crear tablas Iceberg en el catálogo de datos sin particiones usando CloudFormation o SDK y luego sumar particiones desde Atenea amazónica u otros motores de investigación. Esto evita que se realice un seguimiento del pelaje de las tablas en un solo zona y agrega pasos fuera de la automatización en el proceso de integración y entrega continua (CI/CD) para las operaciones de mantenimiento de las tablas. Con el propagación, los clientes de AWS Glue ahora pueden usar sus herramientas de automatización o infraestructura como código (IaC) preferidas para automatizar la creación de tablas Iceberg con particiones y usar las mismas herramientas para regir las actualizaciones de esquemas y el orden de clasificación.
En esta publicación, mostramos cómo crear y refrescar tablas Iceberg con particiones en el catálogo de datos utilizando AWS SDK y CloudFormation.
Descripción universal de la decisión
En las siguientes secciones, ilustramos la SDK de AWS para Python (Boto3) y Interfaz de dirección de comandos de AWS (AWS CLI) uso de las API del catálogo de datos:CrearTabla() y ActualizarTabla()-para Servicio de almacenamiento simple de Amazon (Amazon S3) Tablas Iceberg basadas en particiones. Todavía proporcionamos las plantillas de CloudFormation para crear y refrescar una tabla Iceberg con particiones.
Requisitos previos
Los cambios en la API del catálogo de datos están disponibles en las siguientes versiones de AWS CLI y SDK para Python:
- Lectura de AWS CLI de 2.27.58 o superior
- SDK para Python lectura 1.39.12 o superior
Uso de la CLI de AWS
Creemos una tabla Iceberg con una partición, usando CrearTabla() en la CLI de AWS:
El createicebergtable.json es el posterior:
El comando de AWS CLI inicial crea la carpeta de metadatos para la tabla Iceberg en Amazon S3, como se muestra en la posterior captura de pantalla.

Puede completar la tabla con títulos de la posterior forma y corroborar el esquema de la tabla usando la consola de Athena:
La posterior captura de pantalla muestra los resultados.
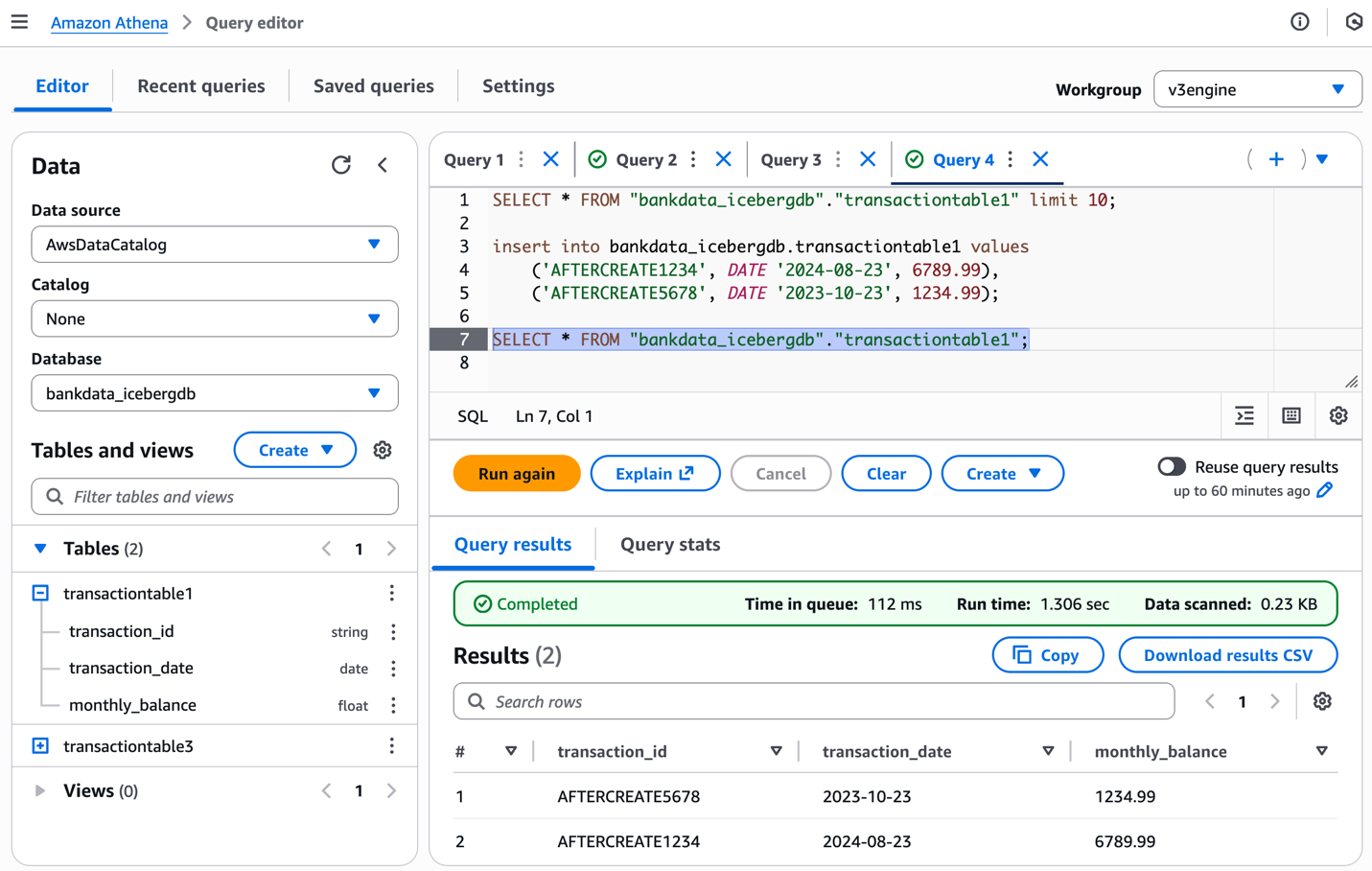
Luego de completar la tabla con datos, puede inspeccionar el prefijo S3 de la tabla, que ahora tendrá el data carpeta.
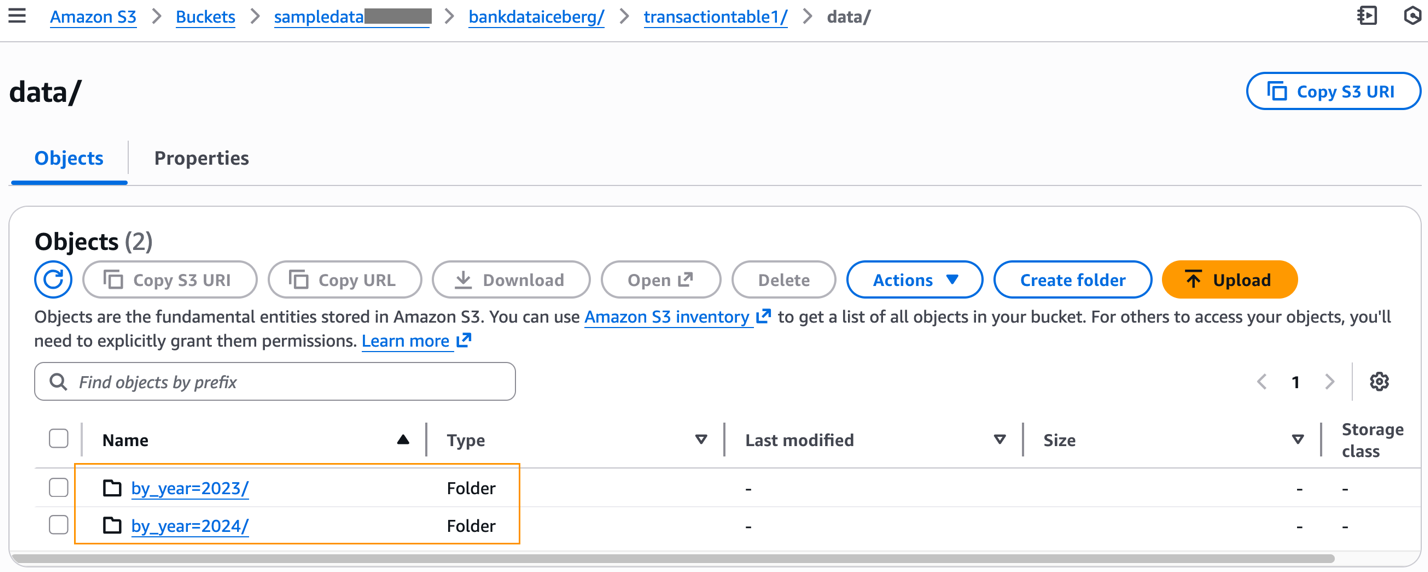
El data Las carpetas particionadas de acuerdo con nuestra definición de tabla y los archivos de datos de Parquet creados a partir de nuestro comando INSERT están disponibles debajo de cada prefijo particionado.

A continuación, actualizamos la tabla Iceberg agregando una nueva partición, usando ActualizarTabla():
El updateicebergtable.json es el posterior.
UpdateTable() modifica el esquema de la tabla agregando un archivo JSON de metadatos al subyacente metadata carpeta de la tabla en Amazon S3.

Insertamos títulos en la tabla usando Athena de la posterior forma:
La posterior captura de pantalla muestra los resultados.
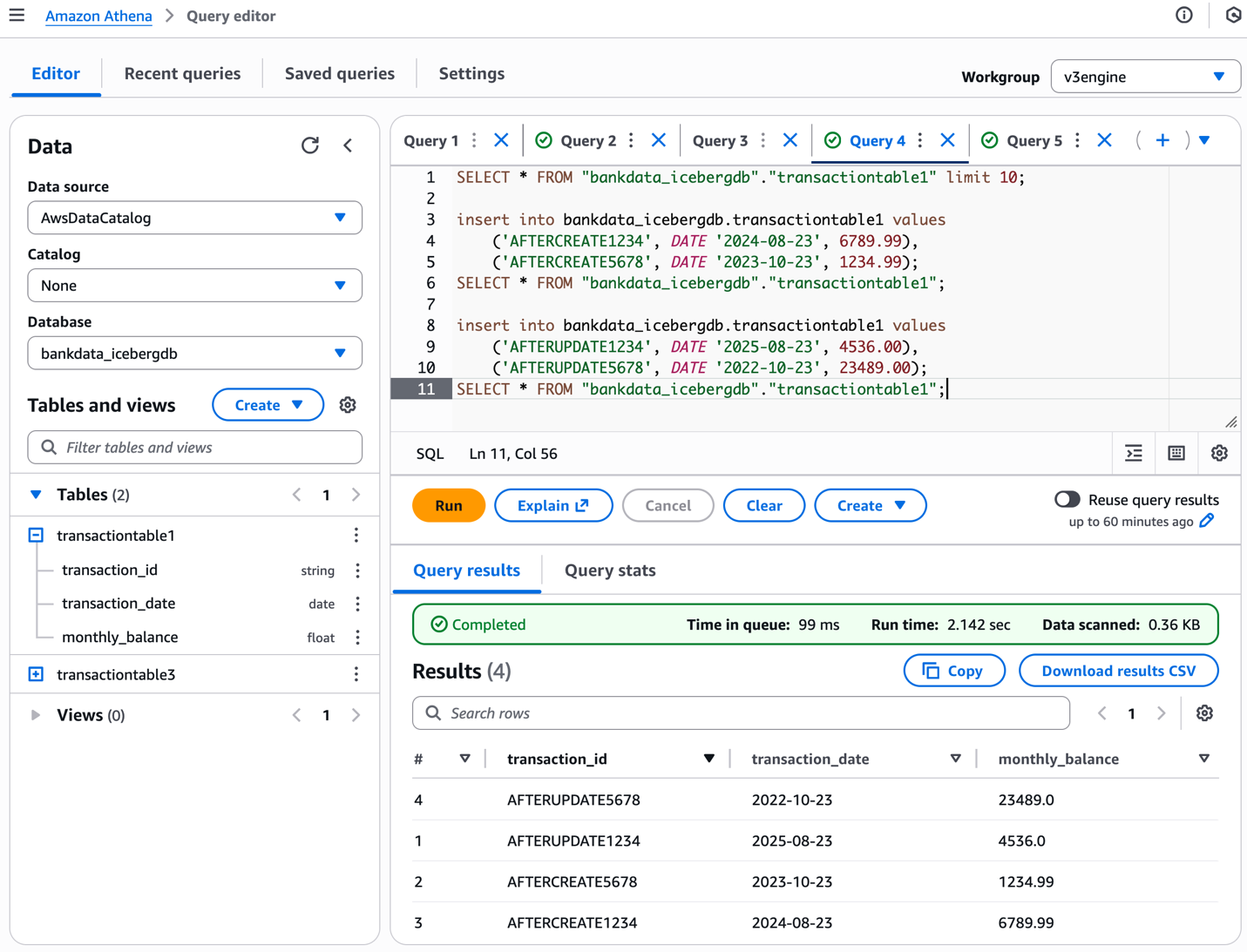
Inspeccionar los cambios correspondientes al data carpeta en la ubicación de Amazon S3 de la tabla.
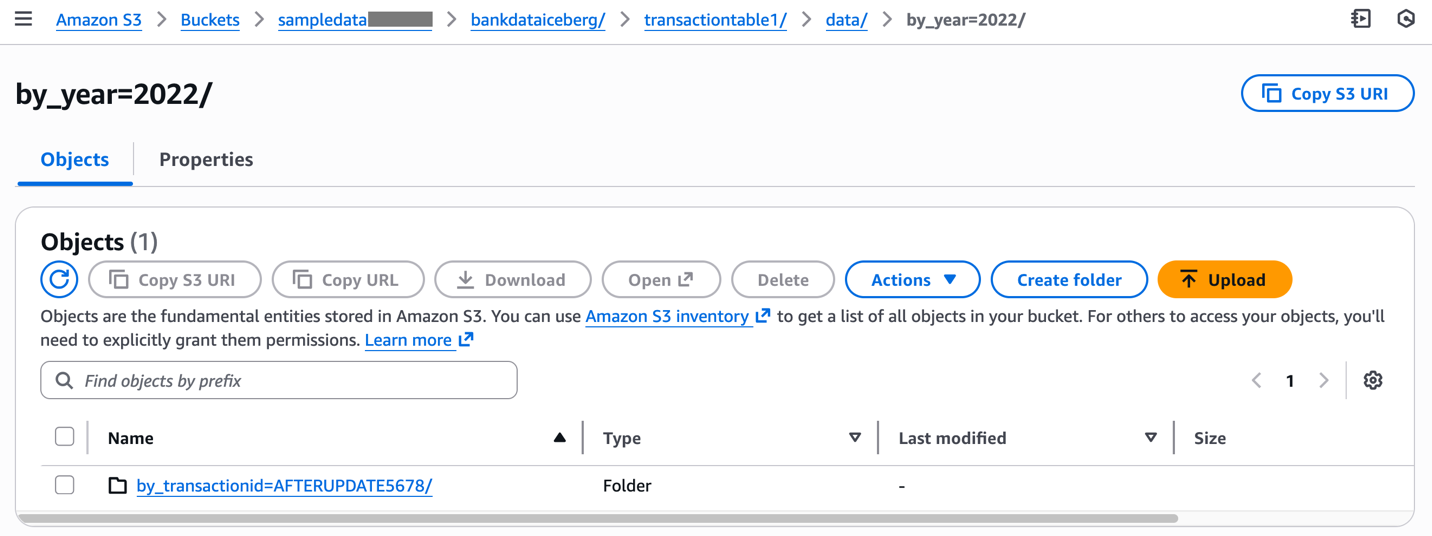
Este ejemplo ha ilustrado cómo crear y refrescar tablas Iceberg con particiones mediante comandos de AWS CLI.
SDK para uso de Python
Los siguientes scripts de Python ilustran el uso CrearTabla() y ActualizarTabla() para una mesa Iceberg con particiones:
Uso de CloudFormation
Utilice las siguientes plantillas de CloudFormation para CreateTable() y UpdateTable(). Luego del CreateTable plantilla está completa, actualice la misma pila con el UpdateTable plantilla creando un nuevo conjunto de cambios para su pila y ejecutándolo.
Acicalar
Para evitar incurrir en costos en las tablas de Iceberg creadas con la CLI de AWS, elimine las tablas del catálogo de datos.
Conclusión
En esta publicación, ilustramos cómo utilizar la CLI de AWS para crear y refrescar tablas Iceberg con particiones en el catálogo de datos. Todavía proporcionamos el código de muestra y las plantillas del SDK para Python y CloudFormation. Esperamos que esto le ayude a automatizar la creación y mandato de sus tablas Iceberg con particiones en sus canales de CI/CD y entornos de producción. Pruébelo en su propio caso de uso y comparta sus comentarios en la sección de comentarios.
Sobre los autores
Agradecimientos: Un agradecimiento específico a todos los que contribuyeron al expansión y propagación de esta función: Purvaja Narayanaswamy, Sachet Saurabh, Akhil Yendluri y Mohit Chandak.