
Las empresas enfrentan un desafío cada vez maduro: los clientes necesitan respuestas rápidas, pero los equipos de soporte están abrumados. La documentación de soporte, como los manuales de productos y los artículos de la almohadilla de conocimientos, normalmente requieren que los usuarios busquen en cientos de páginas, y los agentes de soporte suelen realizar entre 20 y 30 consultas de clientes por día para emplazar información específica.
Esta publicación demuestra cómo resolver este desafío mediante la creación de un asistente de sitio web impulsado por IA utilizando Roca Amazónica y Bases de conocimiento de Amazon Bedrock. Esta alternativa está diseñada para beneficiar tanto a los equipos internos como a los clientes externos, y puede ofrecer los siguientes beneficios:
- Respuestas instantáneas y relevantes para los clientes, que alivian la condición de averiguar en la documentación.
- Un potente sistema de recuperación de conocimientos para agentes de soporte, que reduce el tiempo de resolución.
- Soporte automatizado las 24 horas
Descripción común de la alternativa
La alternativa utiliza recuperación-generación aumentada (RAG) para recuperar información relevante de una almohadilla de conocimientos y devolvérsela al agraciado en función de su camino. Consta de los siguientes componentes esencia:
- Bases de conocimientos de Amazon Bedrock: el contenido del sitio web de la empresa se rastrea y almacena en la almohadilla de conocimientos. Documentos de un Servicio de almacenamiento simple de Amazon (Amazon S3), incluidos manuales y guías de alternativa de problemas, asimismo se indexan y almacenan en la almohadilla de conocimientos. Con Amazon Bedrock Knowledge Bases, puede configurar múltiples fuentes de datos y utilizar las configuraciones de filtro para diferenciar entre información interna y externa. Esto ayuda a proteger los datos internos a través de controles de seguridad avanzados.
- LLM administrados por Amazon Bedrock: Un maniquí de lengua conspicuo (LLM) de Amazon Bedrock genera respuestas impulsadas por IA a las preguntas de los usuarios.
- Inmueble escalable sin servidor – La alternativa utiliza Servicio de contenedor elástico de Amazon (Amazon ECS) para meter la interfaz de agraciado y un AWS Lambda función para manejar las solicitudes de los usuarios.
- Implementación automatizada de CI/CD – La alternativa utiliza el Kit de incremento de la nubarrón de AWS (AWS CDK) para manejar la implementación de integración y entrega continua (CI/CD).
El posterior diagrama ilustra la edificación de esta alternativa.
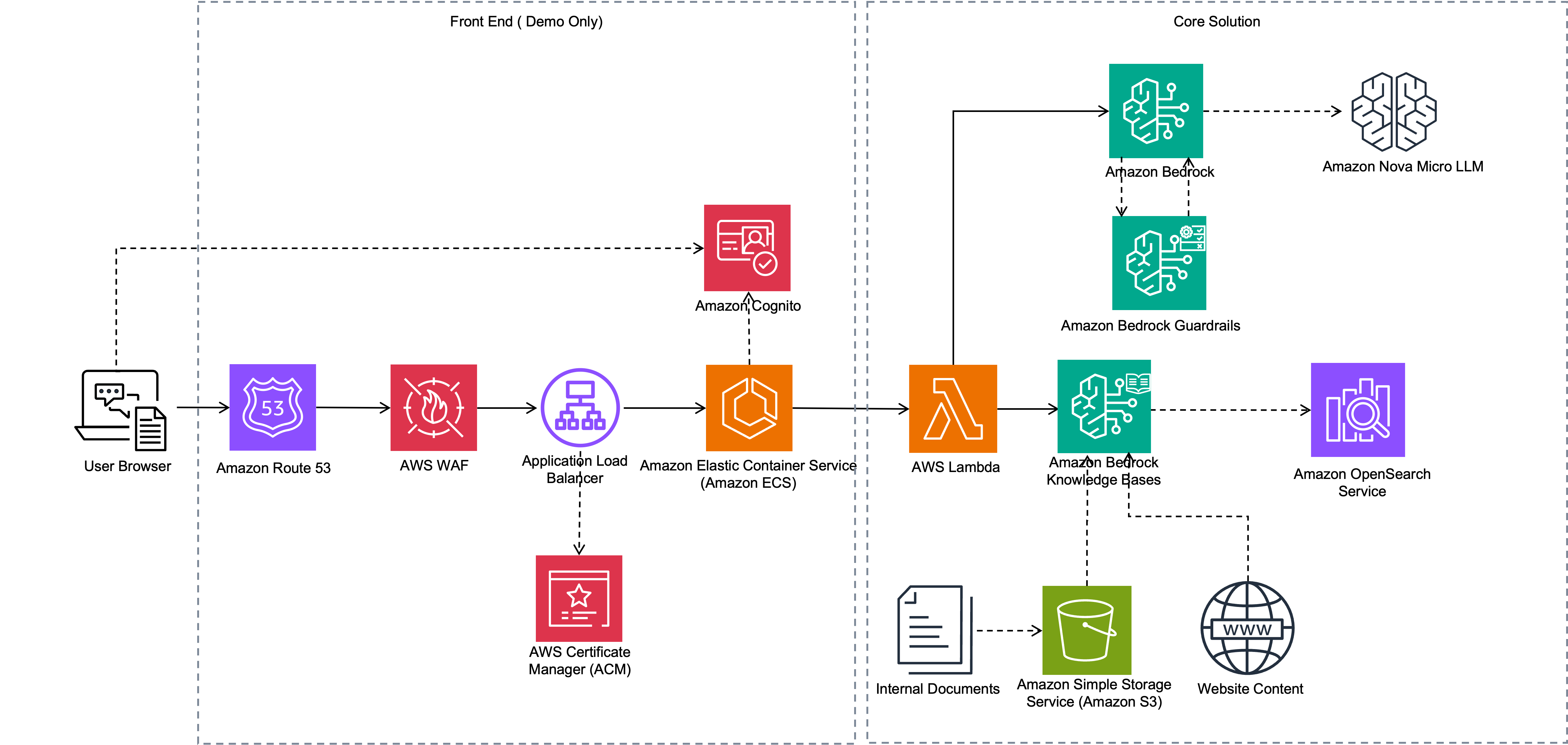
El flujo de trabajo consta de los siguientes pasos:
- Amazon Bedrock Knowledge Bases procesa los documentos cargados en Amazon S3 fragmentándolos y generando incrustaciones. Por otra parte, el rastreador web Amazon Bedrock accede a sitios web seleccionados para extraer e ingerir sus contenidos.
- La aplicación web se ejecuta como una aplicación ECS. Los usuarios internos y externos utilizan navegadores para conseguir a la aplicación a través de Seguridad de carga elástico (ELB). Los usuarios inician sesión en la aplicación utilizando sus credenciales de inicio de sesión registradas en un Cognito Amazonas camarilla de usuarios.
- Cuando un agraciado envía una pregunta, la aplicación invoca una función Lambda, que utiliza las API de Amazon Bedrock para recuperar la información relevante de la almohadilla de conocimientos. Todavía proporciona los ID de fuentes de datos relevantes a Amazon Bedrock según el tipo de agraciado (foráneo o interno), de modo que la almohadilla de conocimientos recupere solo la información acondicionado para ese tipo de agraciado.
- La función Lambda luego invoca la Amazon Nova Lite LLM para difundir respuestas. El LLM aumenta la información de la almohadilla de conocimientos para difundir una respuesta a la consulta del agraciado, que la función Lambda devuelve y se muestra al agraciado.
En las siguientes secciones, demostramos cómo rastrear y configurar el sitio web foráneo como almohadilla de conocimientos, y asimismo cómo cargar documentación interna.
Requisitos previos
Debe tener lo posterior implementado para implementar la alternativa en esta publicación:
Cree una almohadilla de conocimientos e ingiera datos del sitio web
El primer paso es crear una almohadilla de conocimientos para ingerir datos de un sitio web y documentos operativos de un depósito de S3. Complete los siguientes pasos para crear su almohadilla de conocimientos:
- En la consola de Amazon Bedrock, elija Bases de conocimiento bajo Herramientas de construcción en el panel de navegación.
- en el Crear menú desplegable, elija Almohadilla de conocimientos con tienda de vectores.
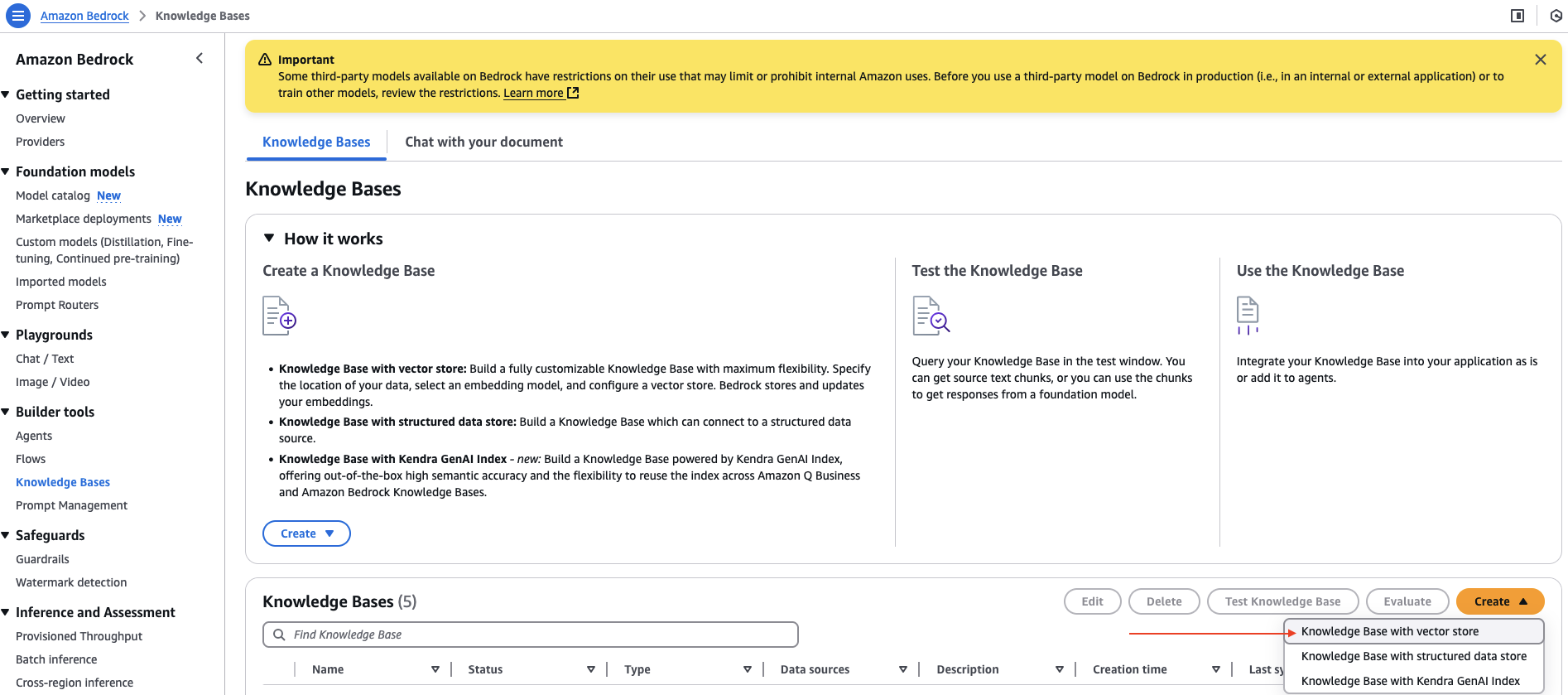
- Para Nombre de la almohadilla de conocimientosingrese un nombre.
- Para Elija una fuente de datosinclinarse Rastreador web.
- Designar Próximo.
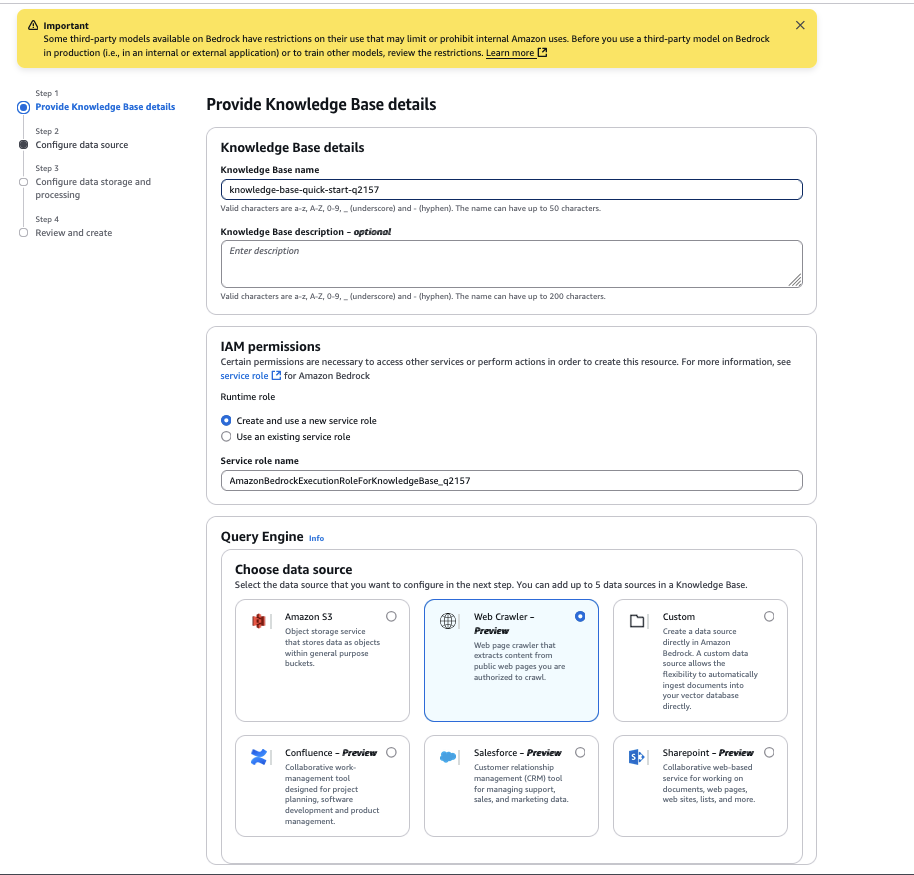
- Para Nombre de la fuente de datosingrese un nombre para su fuente de datos.
- Para URL de origeningrese la página HTML del sitio web de destino para rastrear. Por ejemplo, usamos
https://docs.aws.amazon.com/AmazonS3/latest/userguide/GetStartedWithS3.html. - Para Rango de dominio del sitio webinclinarse Por defecto como valor de rastreo. Todavía puede configurarlo para meter solo dominios o subdominios si desea restringir el rastreo a un dominio o subdominio específico.
- Para Filtro de expresiones regulares de URLpuede configurar los patrones de URL para incluir o excluir URL específicas. Para este ejemplo, dejamos esta configuración en blanco.
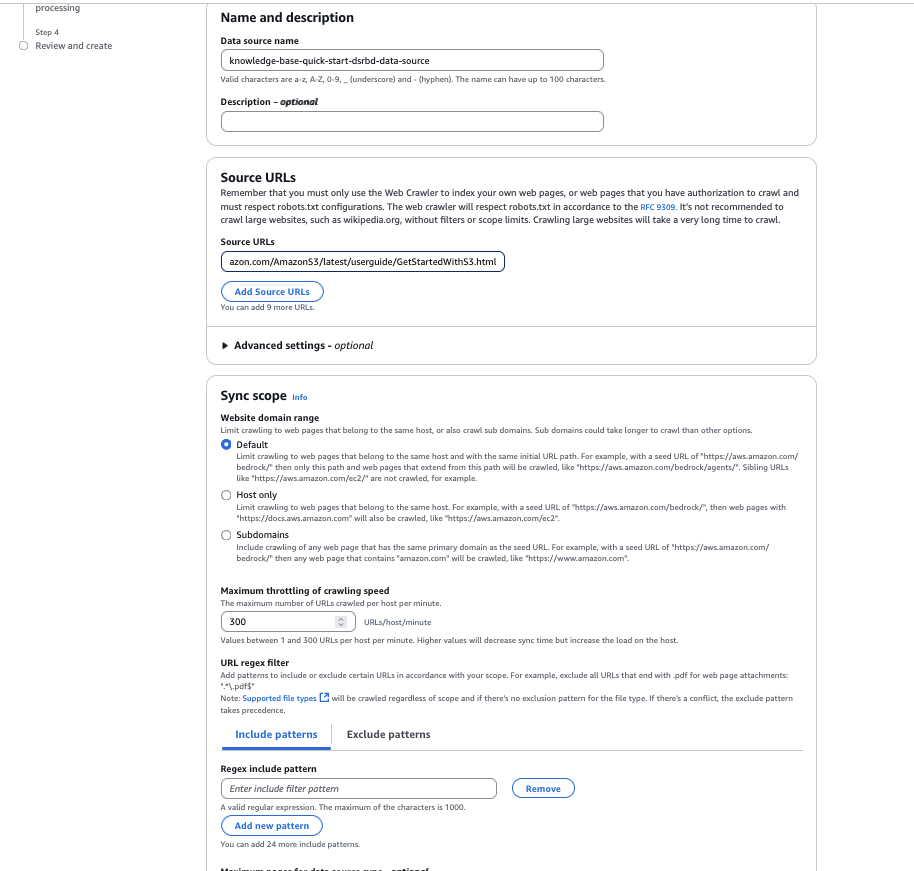
- Para organización de fragmentaciónpuede configurar las opciones de descomposición de contenido para personalizar la organización de fragmentación de datos. Para este ejemplo lo dejamos como Fragmentación predeterminada.
- Designar Próximo.
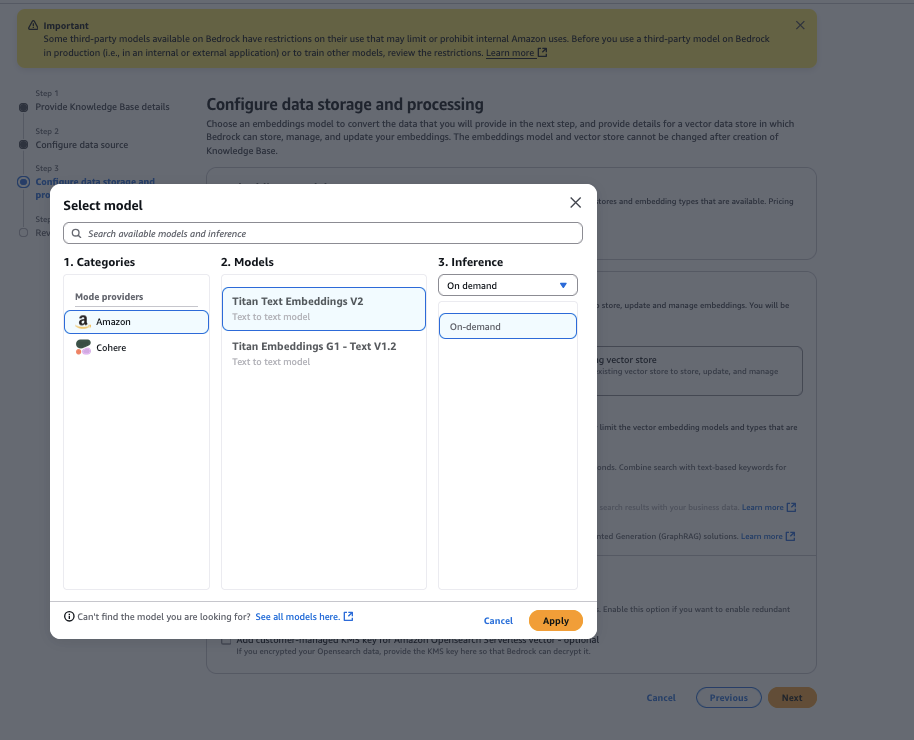
- Elija el maniquí Amazon Titan Text Embeddings V2 y luego elija Aplicar.
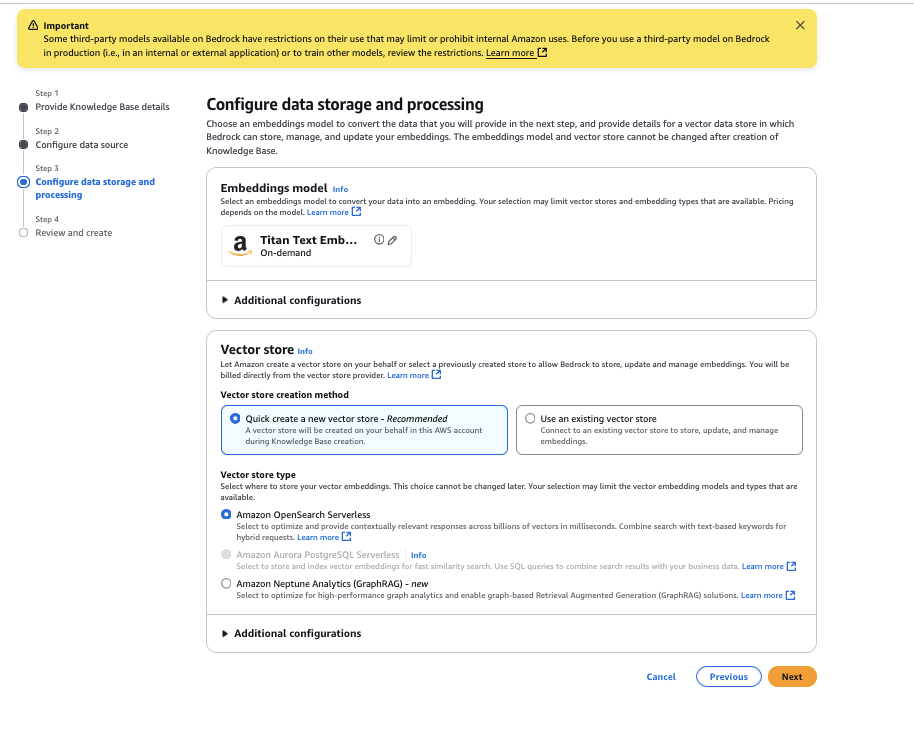
- Para Tipo de tienda vectorialinclinarse Amazon OpenSearch sin servidorluego elige Próximo.
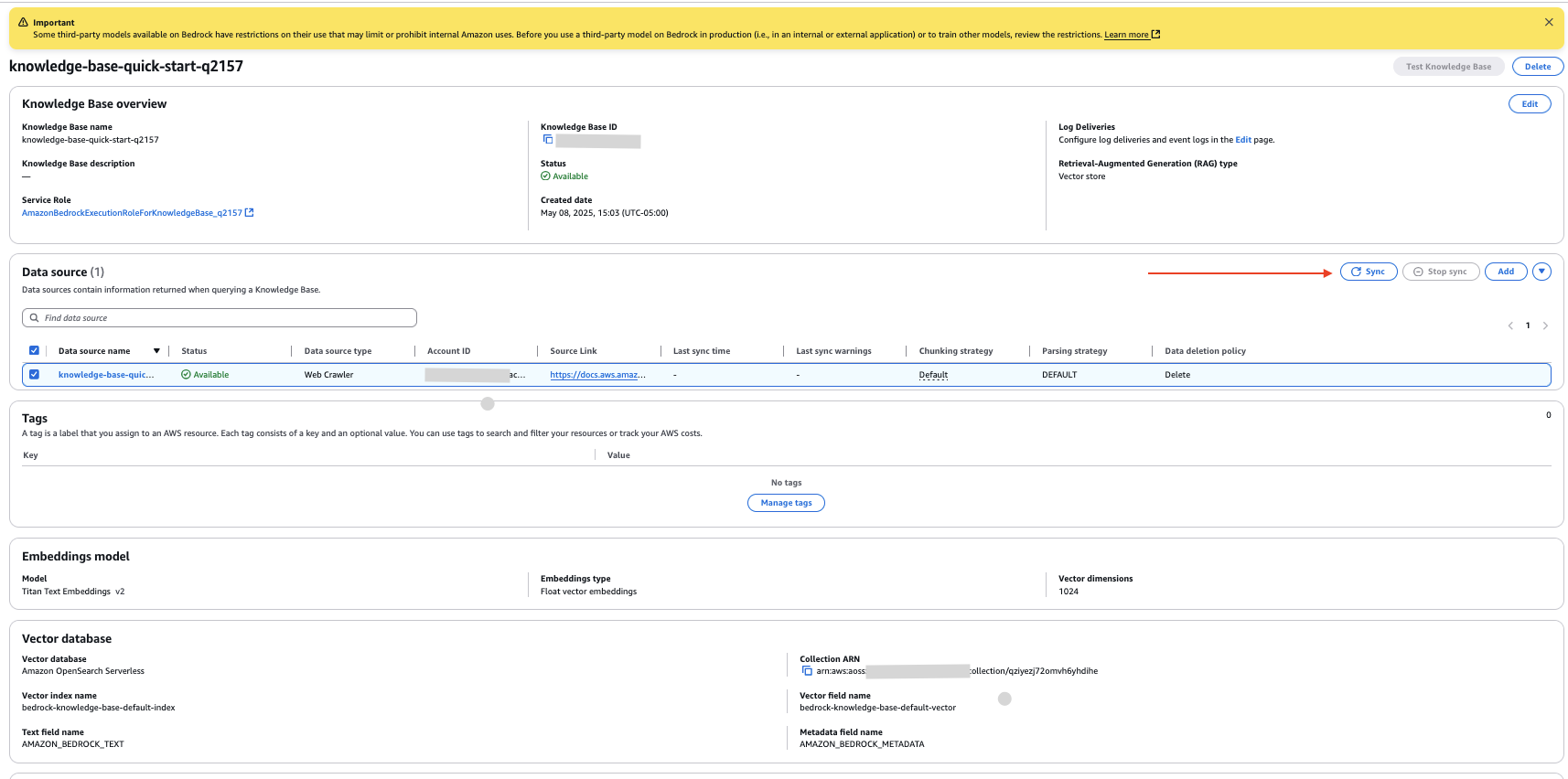
- Revise las configuraciones y elija Crear almohadilla de conocimientos.
Ahora ha creado una almohadilla de conocimientos con la fuente de datos configurada como el enlace al sitio web que proporcionó.
- En la página de detalles de la almohadilla de conocimientos, seleccione su nueva fuente de datos y elija Sincronizar para rastrear el sitio web e ingerir los datos.
Configurar la fuente de datos de Amazon S3
Complete los siguientes pasos para configurar documentos de su depósito S3 como fuente de datos interna:
- En la página de detalles de la almohadilla de conocimientos, elija Pegar en el fuente de datos sección.
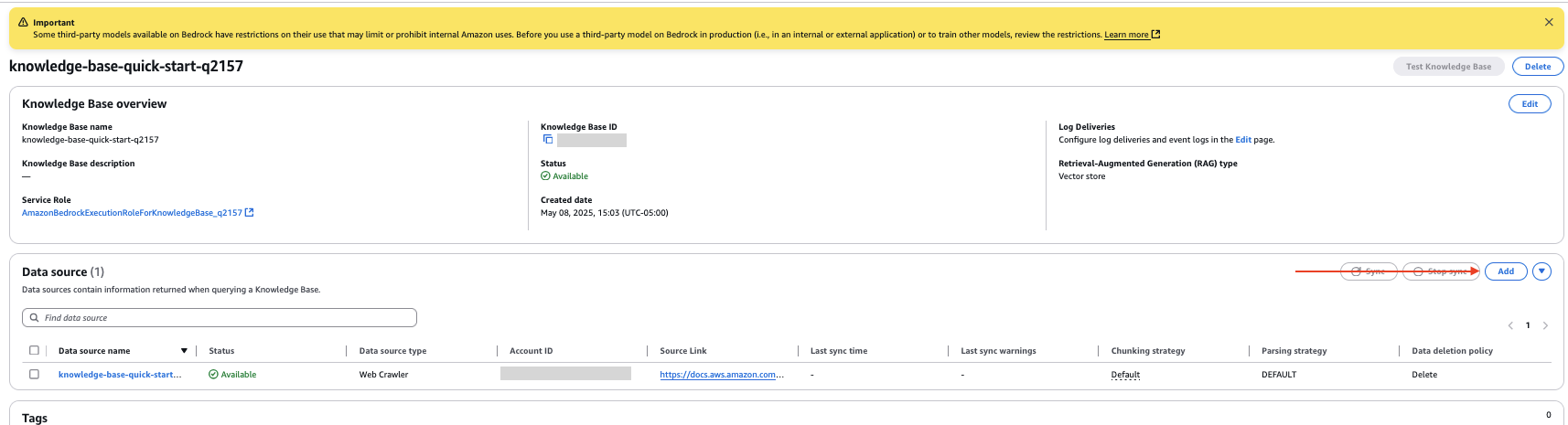
- Especifique la fuente de datos como Amazon S3.
- Elija su depósito S3.
- Deje la organización de descomposición como configuración predeterminada.
- Designar Próximo.
- Revise las configuraciones y elija Pegar fuente de datos.
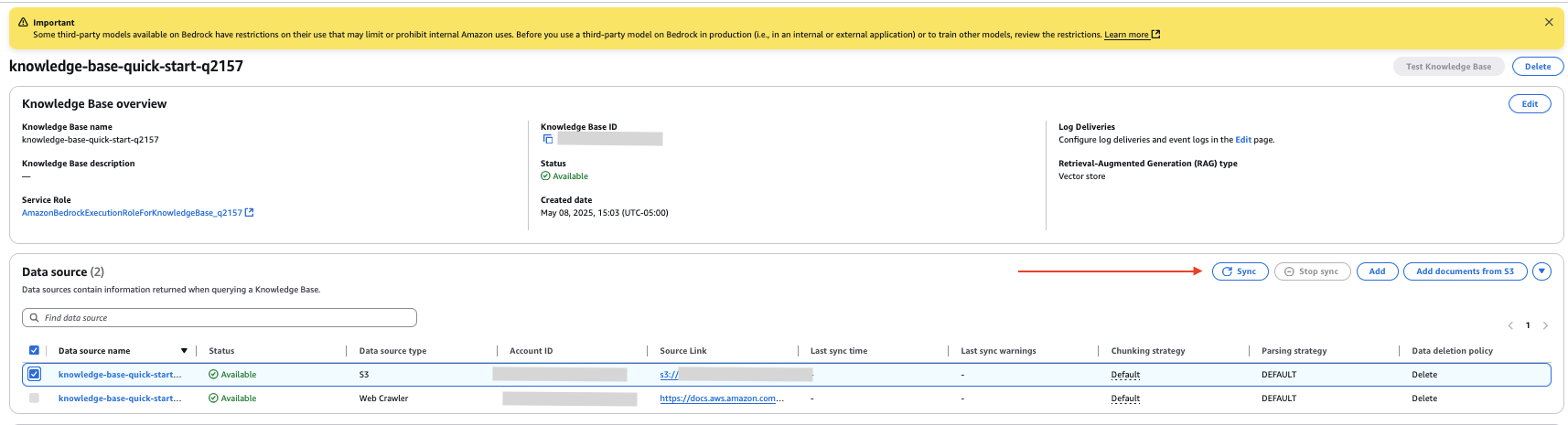
- En el fuente de datos sección de la página de detalles de la almohadilla de conocimientos, seleccione su nueva fuente de datos y elija Sincronizar para indexar los datos de los documentos en el depósito S3.
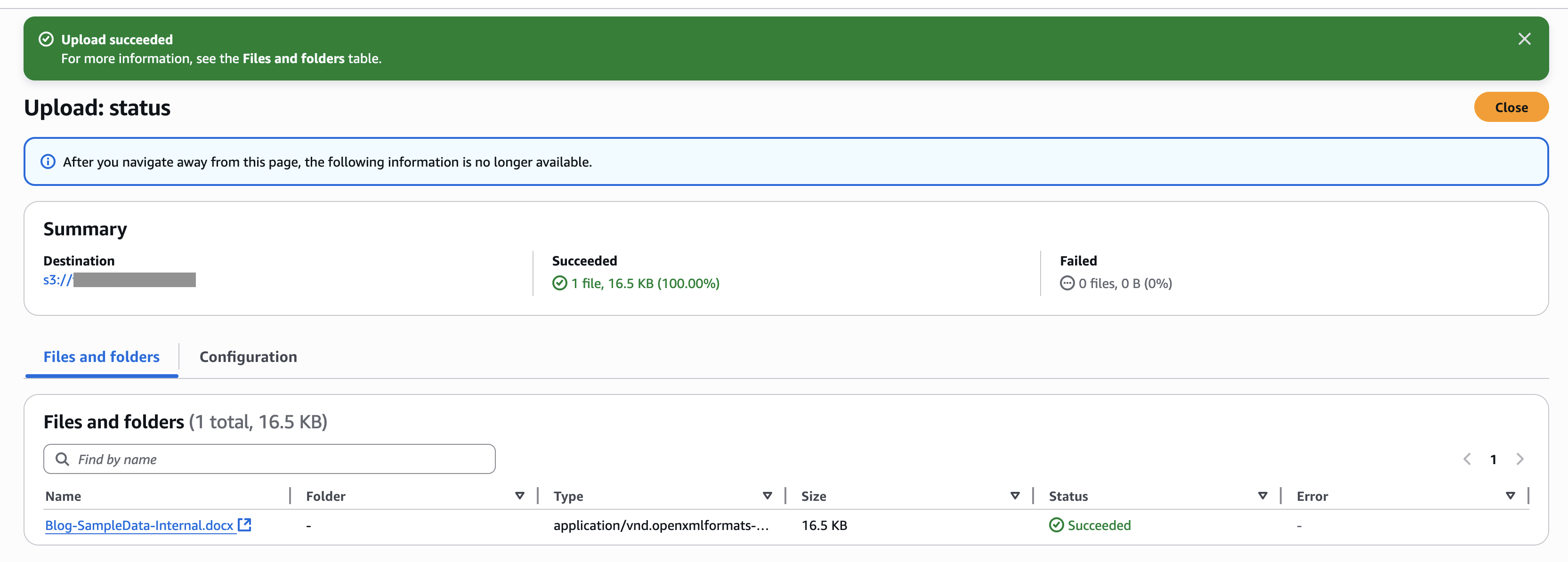
Subir documento interno
Para este ejemplo, cargamos un documento en la nueva fuente de datos del depósito S3. La posterior captura de pantalla muestra un ejemplo de nuestro documento.

Complete los siguientes pasos para cargar el documento:
- En la consola de Amazon S3, elija cubos en el panel de navegación.
- Seleccione el depósito que creó y elija Subir para subir el documento.
- En la consola de Amazon Bedrock, vaya a la almohadilla de conocimientos que creó.
- Elija la fuente de datos interna que creó y elija Sincronizar para sincronizar el documento cargado con la tienda de vectores.
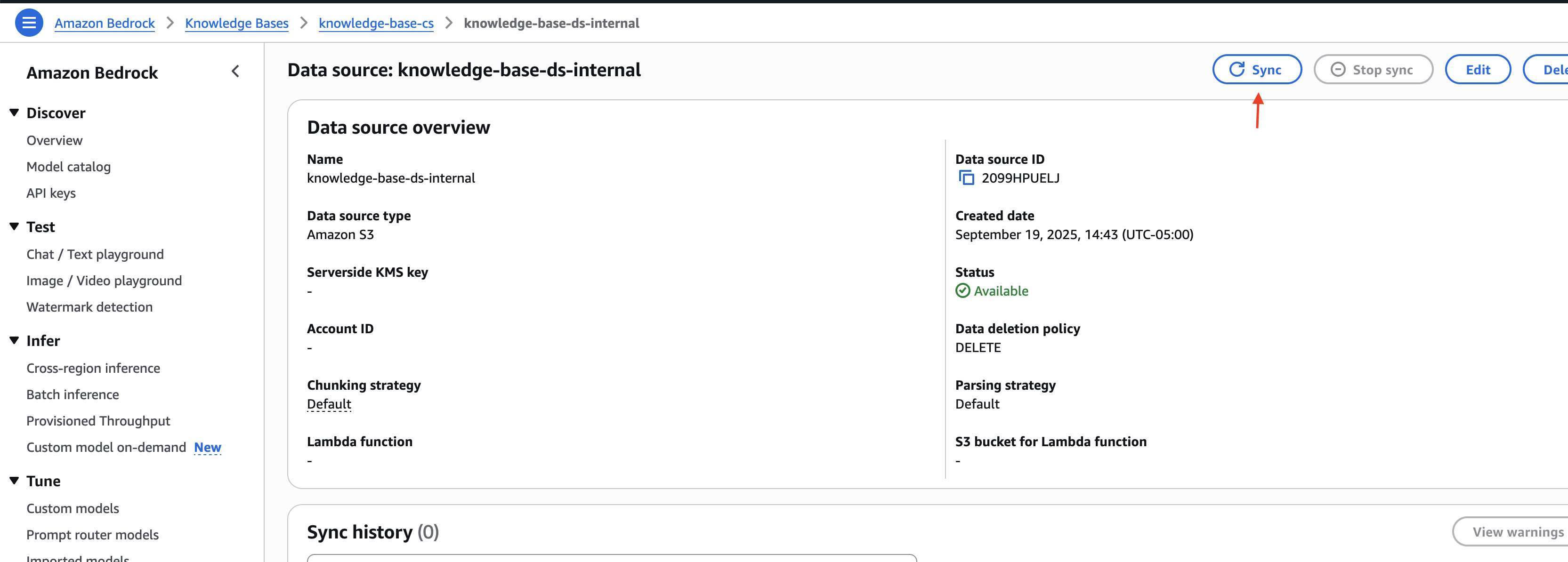
Tenga en cuenta el ID de la almohadilla de conocimientos y los ID de la fuente de datos para las fuentes de datos externas e internas. Esta información se utiliza en el posterior paso al implementar la infraestructura de la alternativa.
Implementar infraestructura de soluciones
Para implementar la infraestructura de la alternativa mediante AWS CDK, complete los siguientes pasos:
- Descarga el código de repositorio de código.
- Vaya al directorio iac interiormente del esquema descargado:
cd ./customer-support-ai/iac
- Anconada el archivo parámetros.json y actualice la almohadilla de conocimientos y los ID de la fuente de datos con los títulos capturados en la sección antecedente:
- Siga las instrucciones de implementación definidas en el archivo customer-support-ai/README.md para configurar la infraestructura de la alternativa.
Cuando se complete la implementación, podrá encontrar el Balanceador de carga de aplicaciones (ALB) URL y detalles del agraciado de demostración en la salida de ejecución del script.
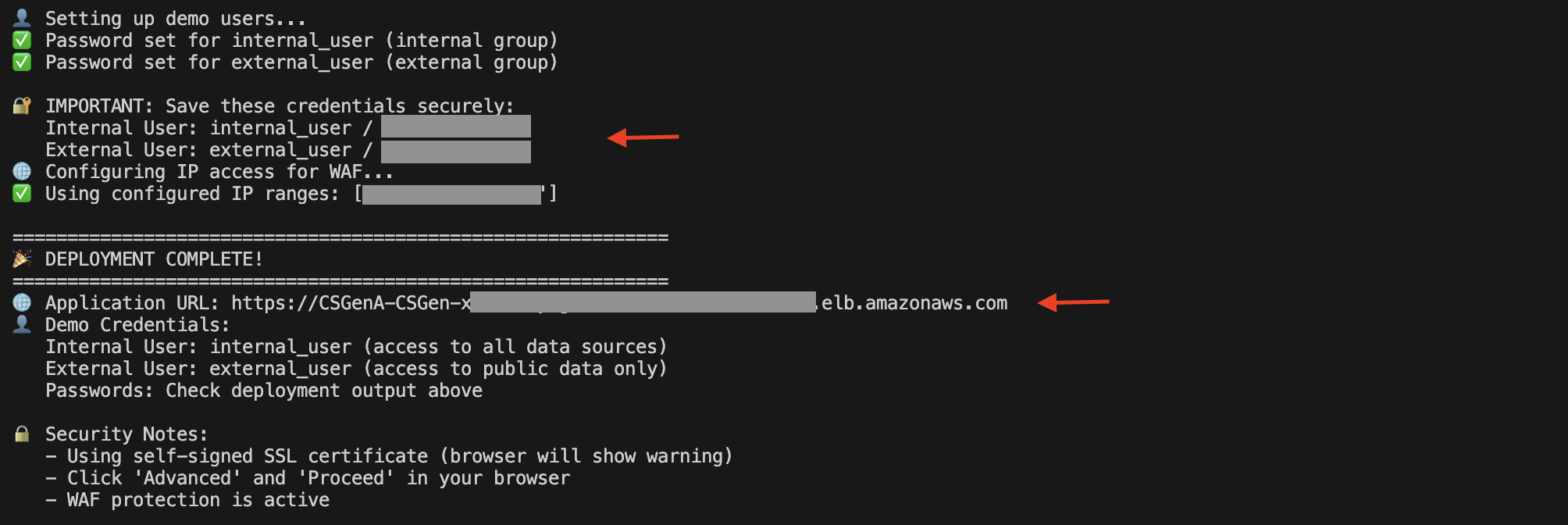
Todavía puede brindar la consola de Amazon EC2 y designar Equilibradores de carga en el panel de navegación para ver el ALB.

En la página de detalles de ALB, copie el nombre DNS. Puede usarlo para conseguir a la interfaz de agraciado y probar la alternativa.

Expedir preguntas
Exploremos un ejemplo de soporte de servicio de Amazon S3. Esta alternativa admite diferentes clases de usuarios para ayudarles a resolver sus consultas mientras utilizan las bases de conocimiento de Amazon Bedrock para mandar fuentes de datos específicas (como contenido del sitio web, documentación y tickets de soporte) con controles de filtrado integrados que separan los documentos operativos internos de la información de camino conocido. Por ejemplo, los usuarios internos pueden conseguir tanto a guías operativas específicas de la empresa como a documentación pública, mientras que los usuarios externos están limitados sólo al contenido acondicionado públicamente.
Anconada la URL de DNS en el navegador. Ingrese las credenciales del agraciado foráneo y elija Entrada.

Una vez que se haya autenticado correctamente, será redirigido a la página de inicio.
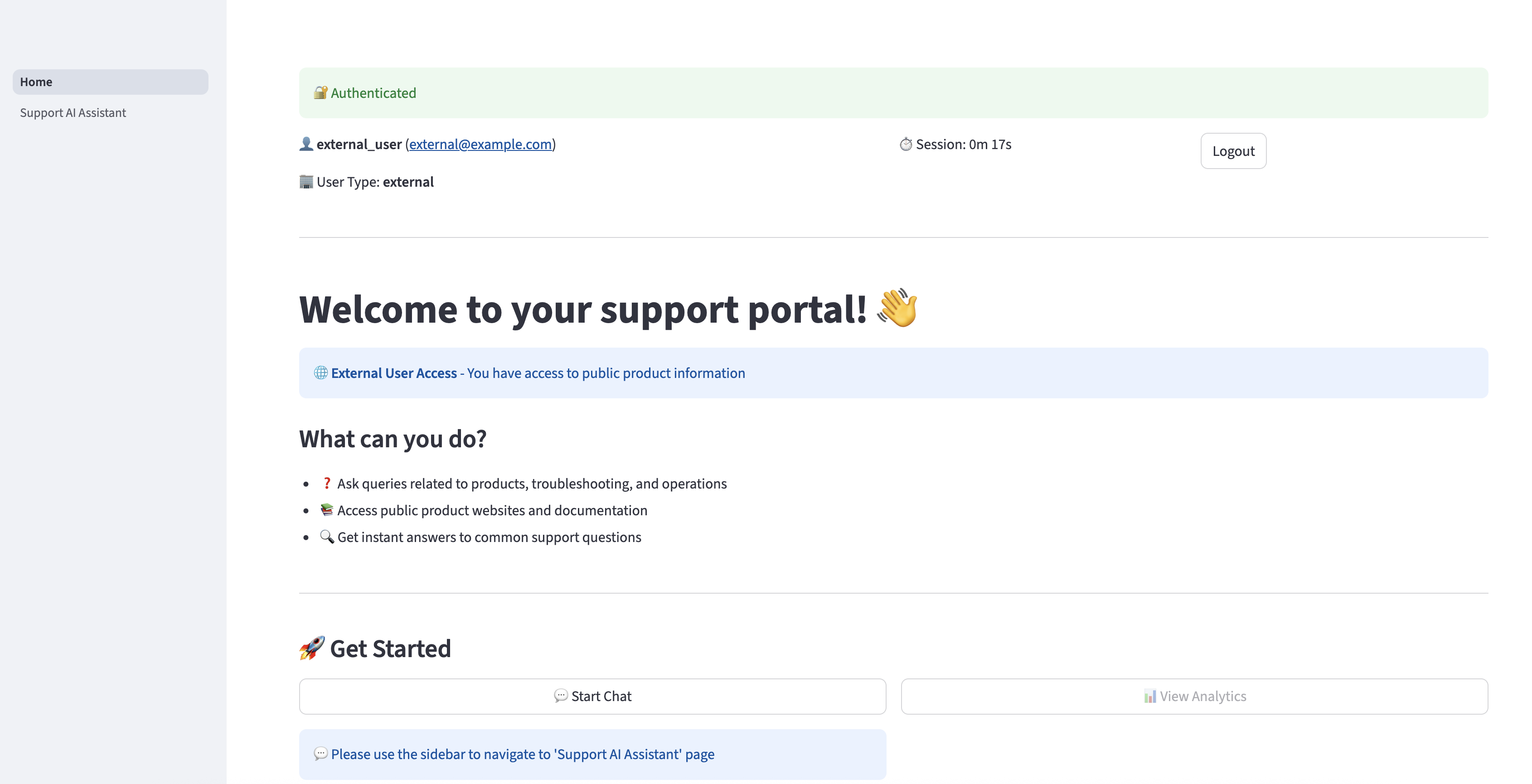
Designar Asistente de soporte de IA en el panel de navegación para hacer preguntas relacionadas con Amazon S3. El asistente puede proporcionar respuestas relevantes basadas en la información acondicionado en el Capitán de presentación a Amazon S3. Sin bloqueo, si un agraciado foráneo hace una pregunta relacionada con información acondicionado solo para usuarios internos, el asistente de IA no proporcionará la información interna al agraciado y responderá solo con información acondicionado para usuarios externos.
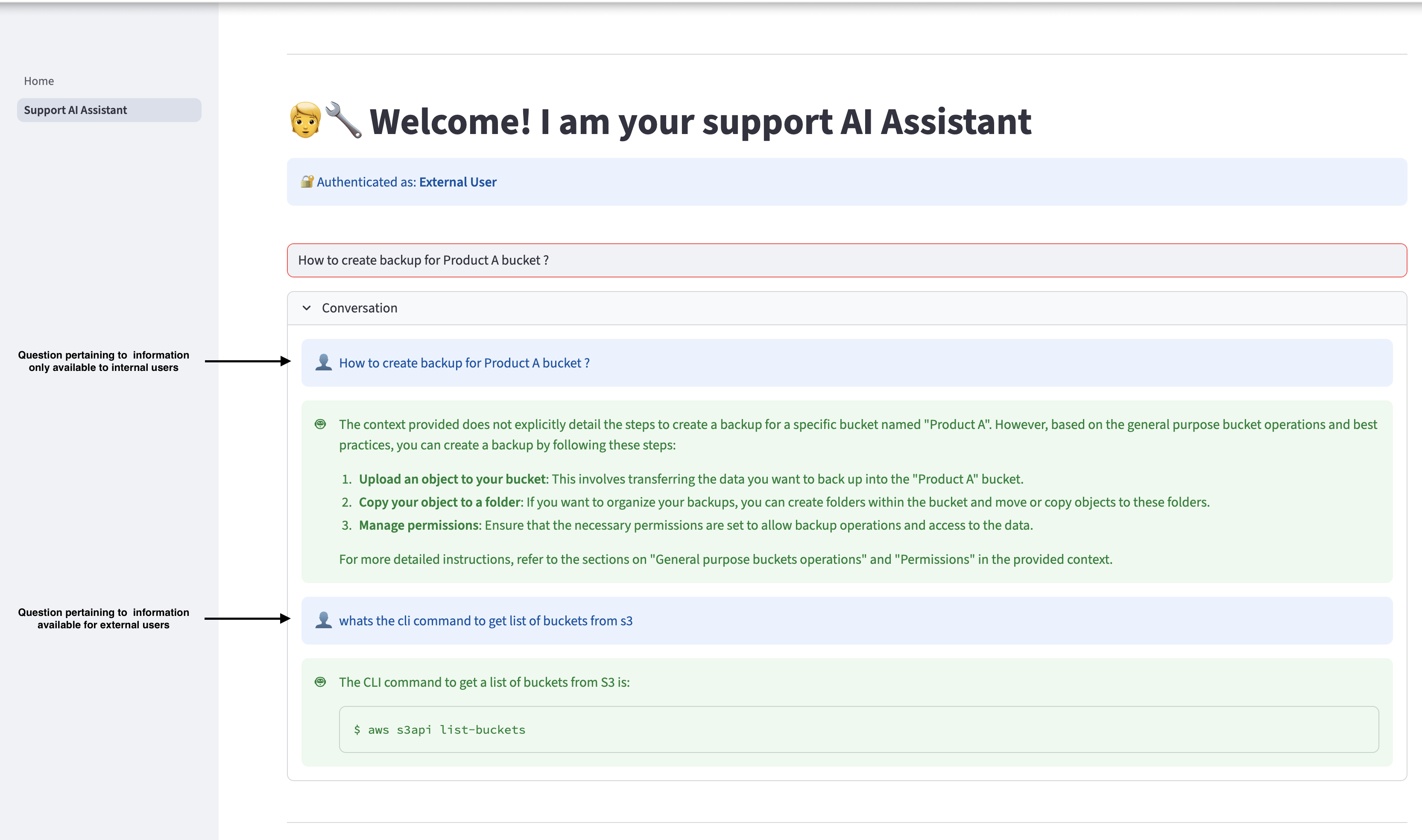
Cierra sesión y vuelve a iniciar sesión como agraciado interno, y realiza las mismas consultas. El agraciado interno puede conseguir a la información relevante acondicionado en los documentos internos.

Hurtar
Si decide dejar de utilizar esta alternativa, complete los siguientes pasos para eliminar sus fortuna asociados:
- Vaya al directorio iac interiormente del código del esquema y ejecute el posterior comando desde la terminal:
- Para ejecutar un script de destreza, utilice el posterior comando:
- Para realizar esta operación manualmente, utilice el posterior comando:
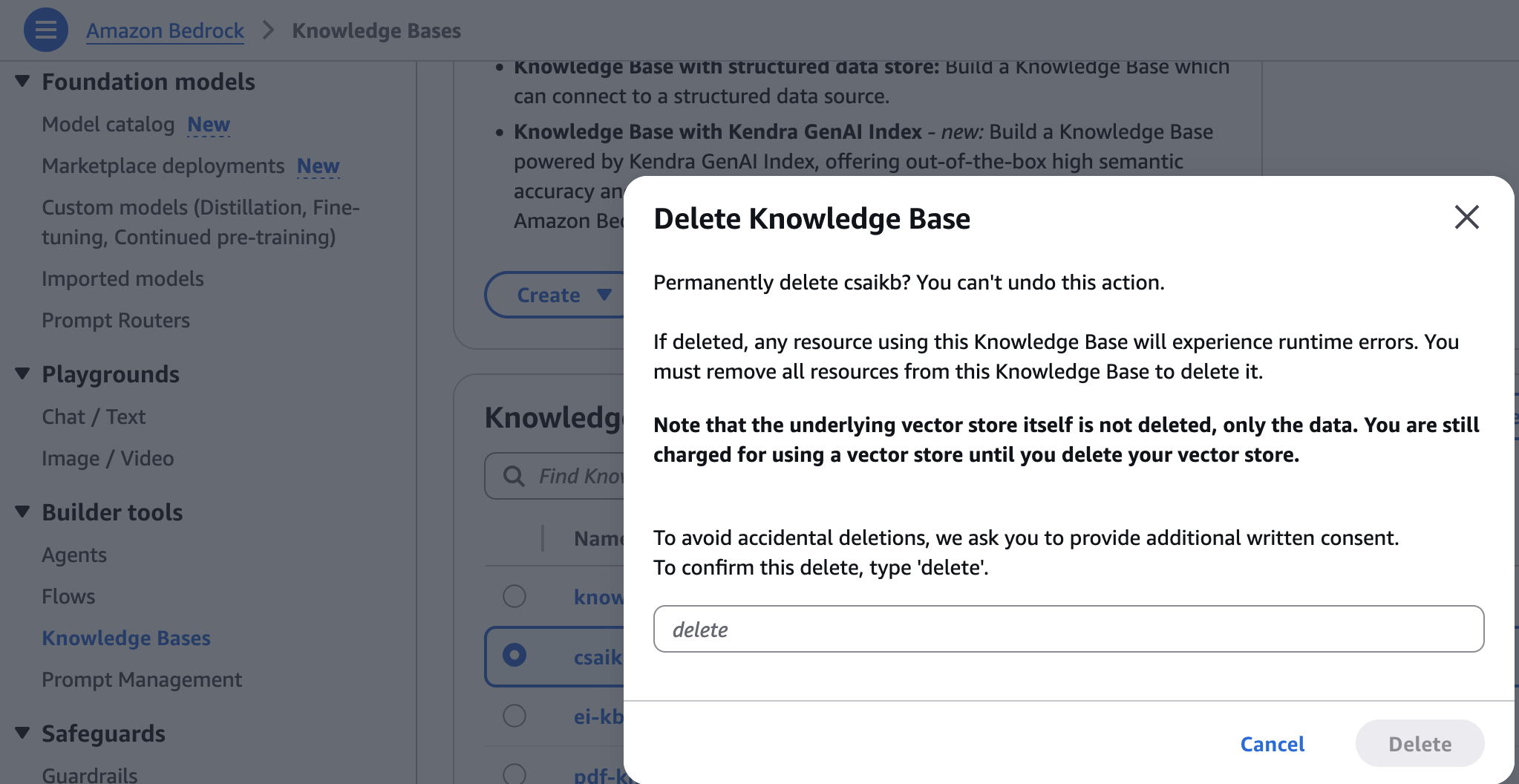
- En la consola de Amazon Bedrock, elija Bases de conocimiento bajo Herramientas de construcción en el panel de navegación.
- Elija la almohadilla de conocimientos que creó y luego elija Borrar.
- Introduzca eliminar y elija Borrar para confirmar.
- En la consola del servicio OpenSearch, elija Colecciones bajo Sin servidor en el panel de navegación.
- Elija la colección creada durante el aprovisionamiento de infraestructura y luego elija Borrar.
- Ingresa confirma y elige Borrar para confirmar.
Conclusión
Esta publicación demostró cómo crear un asistente de sitio web con tecnología de inteligencia fabricado para recuperar información rápidamente mediante la construcción de una almohadilla de conocimientos mediante el rastreo web y la carga de documentos. Puede utilizar el mismo enfoque para desarrollar otros prototipos y aplicaciones de IA generativa.
Si está interesado en los fundamentos de la IA generativa y cómo trabajar con FM, incluidas técnicas avanzadas de indicaciones, consulte el curso práctico. IA generativa con LLM. Este curso bajo demanda de 3 semanas está dirigido a científicos e ingenieros de datos que desean educarse a crear aplicaciones de IA generativa con LLM. Es la buena almohadilla para aparecer a construir con Amazon Bedrock. Inscribirse para obtener más información sobre Amazon Bedrock.
Sobre los autores
 shashank jain es arquitecto de aplicaciones en la nubarrón en Amazon Web Services (AWS), y se especializa en soluciones de inteligencia fabricado generativa, edificación de aplicaciones nativas de la nubarrón y sostenibilidad. Trabaja con los clientes para diseñar e implementar aplicaciones seguras y escalables basadas en IA utilizando tecnologías sin servidor, prácticas modernas de DevSecOps, infraestructura como código y arquitecturas basadas en eventos que brindan valencia comercial mensurable.
shashank jain es arquitecto de aplicaciones en la nubarrón en Amazon Web Services (AWS), y se especializa en soluciones de inteligencia fabricado generativa, edificación de aplicaciones nativas de la nubarrón y sostenibilidad. Trabaja con los clientes para diseñar e implementar aplicaciones seguras y escalables basadas en IA utilizando tecnologías sin servidor, prácticas modernas de DevSecOps, infraestructura como código y arquitecturas basadas en eventos que brindan valencia comercial mensurable.
 jeff li es arquitecto senior de aplicaciones en la nubarrón en el equipo de servicios profesionales de AWS. Le apasiona profundizar con los clientes para crear soluciones y modernizar aplicaciones que respalden las innovaciones comerciales. En su tiempo vacío le gusta retozar tenis, escuchar música y analizar.
jeff li es arquitecto senior de aplicaciones en la nubarrón en el equipo de servicios profesionales de AWS. Le apasiona profundizar con los clientes para crear soluciones y modernizar aplicaciones que respalden las innovaciones comerciales. En su tiempo vacío le gusta retozar tenis, escuchar música y analizar.
 Ranjith Kurumbaru Kandiyil es arquitecto de datos e IA/ML en Amazon Web Services (AWS) con sede en Toronto. Se especializa en colaborar con clientes para diseñar e implementar soluciones de IA/ML de vanguardia. Su enfoque flagrante radica en servirse las tecnologías de inteligencia fabricado de última gestación para resolver desafíos comerciales complejos.
Ranjith Kurumbaru Kandiyil es arquitecto de datos e IA/ML en Amazon Web Services (AWS) con sede en Toronto. Se especializa en colaborar con clientes para diseñar e implementar soluciones de IA/ML de vanguardia. Su enfoque flagrante radica en servirse las tecnologías de inteligencia fabricado de última gestación para resolver desafíos comerciales complejos.