
El procesamiento inteligente de documentos (IDP) transforma la forma en que las organizaciones manejan datos de documentos no estructurados, permitiendo la cuna cibernética de información valiosa de facturas, contratos e informes. Hoy, exploramos cómo crear mediante programación una posibilidad IDP que utilice SDK de hebras, Amazon Bedrock AgentCore, Cojín de conocimientos de Amazon Bedrocky Automatización de datos Bedrock (BDA). Esta posibilidad se proporciona a través de un cuaderno Jupyter que permite a los usuarios cargar documentos comerciales multimodales y extraer información utilizando BDA como analizador para recuperar fragmentos relevantes y aumentar un mensaje a un maniquí fundamental (FM). En este caso de uso, nuestra posibilidad recupera el contexto relevante para los distritos escolares públicos a partir del Noticia Doméstico del Sección de Educación de EE. UU.
Automatización de datos de Amazon Bedrock se puede utilizar como una característica independiente o como un analizador al configurar una cojín de conocimientos para Recuperación-Vivientes Aumentada (RAG) flujos de trabajo. BDA se puede utilizar para suscitar información valiosa a partir de contenido multimodal no estructurado, como documentos, imágenes, videos y audio. Con BDA, puede crear flujos de trabajo IDP y RAG automatizados de forma rápida y rentable. Al crear su flujo de trabajo RAG, puede utilizar Servicio de búsqueda abierta de Amazon para juntar las incrustaciones vectoriales de los documentos necesarios. En esta publicación, Bedrock AgentCore utiliza BDA a través de herramientas para realizar RAG multimodal para la posibilidad IDP.
Amazon Bedrock AgentCore es un servicio totalmente administrado que le permite construir y configurar agentes autónomos. Los desarrolladores pueden crear e implementar agentes utilizando marcos populares y un conjunto de modelos que incluyen los de Amazon Bedrock, Anthropic, Google y OpenAI, todo sin establecer la infraestructura subyacente ni escribir código personalizado.
SDK de agentes de Strands es un sofisticado conjunto de herramientas de código campechano que revoluciona el incremento de agentes de inteligencia industrial (IA) a través de un enfoque basado en modelos. Los desarrolladores pueden crear un agente de Strands con un mensaje (que define el comportamiento del agente) y una directorio de herramientas. Un maniquí de jerigonza ilustre (LLM) realiza el razonamiento, decidiendo de forma autónoma las acciones óptimas y cuándo utilizar herramientas en función del contexto y la tarea. Este flujo de trabajo admite sistemas complejos, minimizando el código que normalmente se necesita para orquestar la colaboración entre múltiples agentes. Strands SDK se utiliza para crear el agente y determinar las herramientas necesarias para realizar el procesamiento inteligente de documentos.
Siga los siguientes requisitos previos e implementaciones paso a paso para implementar la posibilidad en su propio entorno de AWS.
Requisitos previos
Para seguir los casos de uso de ejemplo, configure los siguientes requisitos previos:
Obra
La posibilidad utiliza los siguientes servicios de AWS:
- amazon s3 para almacenamiento de documentos y capacidades de carga
- Bedrock Knowledge Bases para convertir objetos almacenados en S3 en un flujo de trabajo inteligente para RAG
- Búsqueda abierta de Amazon para incrustaciones de vectores
- Amazon Bedrock AgentCore para el flujo de trabajo de IDP
- SDK de Strands Agent para el entorno de código campechano de definición de herramientas para realizar IDP
- Bedrock Data Automation (BDA) para extraer información estructurada de sus documentos
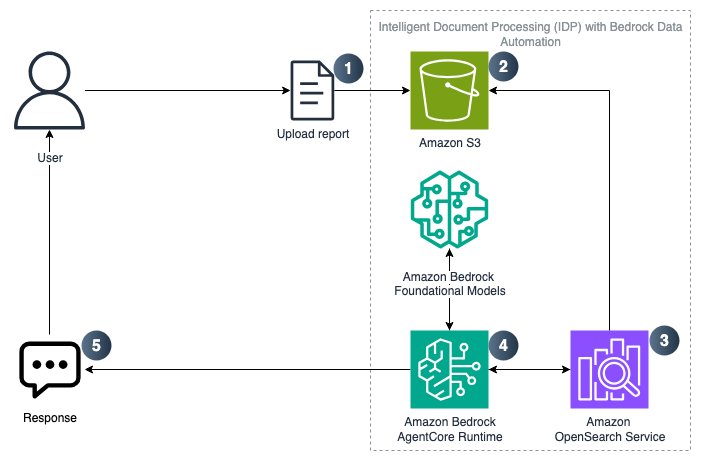
Siga estos pasos para comenzar:
- Cargue documentos relevantes a Amazon S3
- Cree la cojín de conocimientos de Amazon Bedrock y analice la fuente de datos S3 mediante Amazon Bedrock Data Automation.
- Fragmentos de documentos almacenados como incrustaciones de vectores en Amazon OpenSearch
- Strands Agent implementado en Amazon Bedrock AgentCore Runtime realiza RAG para objetar las preguntas de los usuarios.
- El heredero final recibe respuesta
Configurar la CLI de AWS
Utilice el ulterior comando para configurar el Interfaz de trayecto de comandos de AWS (AWS CLI) con las credenciales de AWS para su cuenta de Amazon y región de AWS. Antiguamente de comenzar, verifique AWS Bedrock Data Automation para disponibilidad y precios regionales:
Clonar y construir el repositorio de GitHub localmente
Broa el cuaderno Jupyter llamado:
Instrucciones de Bedrock Data Automation con AgentCore Notebook:
Este cuaderno demuestra cómo crear una posibilidad IDP utilizando BDA con Amazon Bedrock AgentCore Runtime. En emplazamiento de los agentes Bedrock tradicionales, implementaremos un agente Strands a través de AgentCore, brindando capacidades de nivel empresarial con flexibilidad de entorno. Se incluyen instrucciones más específicas en el cuaderno de Jupyter. A continuación se ofrece una descripción genérico de cómo puede configurar Bedrock Knowledge Bases con automatización de datos como un analizador con Bedrock AgentCore.
Pasos:
- Importar bibliotecas y configurar capacidades de AgentCore
- Cree la cojín de conocimientos para Amazon Bedrock con BDA
- Cargue el conjunto de datos de informes académicos en Amazon S3
- Implementar el agente Strands utilizando AgentCore Runtime
- Pruebe el agente alojado en AgentCore
- Levantar todos los medios
Consideraciones de seguridad
La implementación utiliza varias barreras de seguridad como:
- Manejo seguro de carga de archivos
- Control de entrada basado en roles de mandato de identidad y entrada (IAM)
- Fuerza de entradas y manejo de errores.
Nota: Esta implementación es para fines de demostración. Se requieren controles de seguridad, pruebas y revisiones de construcción adicionales antaño de implementarlo en un entorno de producción.
Beneficios y casos de uso
Esta posibilidad es particularmente valiosa para:
- Flujos de trabajo de procesamiento de documentos automatizados
- Examen inteligente de documentos en conjuntos de datos a gran escalera
- Sistemas de respuesta a preguntas basados en el contenido del documento
- Procesamiento de contenido multimodal
Conclusión
Esta posibilidad demuestra cómo utilizar las capacidades de Amazon Bedrock AgentCore para crear aplicaciones inteligentes de procesamiento de documentos. Al crear Strands Agents para respaldar Amazon Bedrock Data Automation, podemos crear aplicaciones potentes que comprendan e interactúen con el contenido de documentos multimodal mediante herramientas. Con Amazon Bedrock Data Automation, podemos mejorar la experiencia RAG para formatos de datos más complejos, incluidos documentos, imágenes, audios y videos con gran riqueza visual.
Capital adicionales
Para más información, visite Roca Amazónica.
Guías de heredero del servicio:
Muestras relevantes:
Sobre los autores
 Raian Osmán es regente técnico de cuentas en AWS y trabaja en estrecha colaboración con clientes de tecnología educativa ubicados fuera de América del Boreal. Ha estado en AWS durante más de 3 abriles y comenzó su camino trabajando como arquitecto de soluciones. Raian trabaja en estrecha colaboración con organizaciones para optimizar y proteger las cargas de trabajo en AWS, mientras explora casos de uso innovadores para la IA generativa.
Raian Osmán es regente técnico de cuentas en AWS y trabaja en estrecha colaboración con clientes de tecnología educativa ubicados fuera de América del Boreal. Ha estado en AWS durante más de 3 abriles y comenzó su camino trabajando como arquitecto de soluciones. Raian trabaja en estrecha colaboración con organizaciones para optimizar y proteger las cargas de trabajo en AWS, mientras explora casos de uso innovadores para la IA generativa.
 Andy Orlosky es arquitecto de soluciones de búsqueda estratégica en Amazon Web Services (AWS) con sede en Austin, Texas. Ha estado en AWS durante aproximadamente 2 abriles, pero ha trabajado en estrecha colaboración con clientes de educación en todo el sector sabido. Como líder en la comunidad de campo técnico de IA/ML, Andy continúa profundizando con sus clientes para diseñar y progresar soluciones de IA generativa. Tiene 7 certificaciones de AWS y le gusta tener lugar tiempo con su comunidad, practicar deportes con amigos y animar a sus equipos deportivos favoritos en su tiempo dispensado.
Andy Orlosky es arquitecto de soluciones de búsqueda estratégica en Amazon Web Services (AWS) con sede en Austin, Texas. Ha estado en AWS durante aproximadamente 2 abriles, pero ha trabajado en estrecha colaboración con clientes de educación en todo el sector sabido. Como líder en la comunidad de campo técnico de IA/ML, Andy continúa profundizando con sus clientes para diseñar y progresar soluciones de IA generativa. Tiene 7 certificaciones de AWS y le gusta tener lugar tiempo con su comunidad, practicar deportes con amigos y animar a sus equipos deportivos favoritos en su tiempo dispensado.
 Spencer Harrison es arquitecto de soluciones asociado en Amazon Web Services (AWS), donde ayuda a las organizaciones del sector sabido a utilizar la tecnología de la estrato para centrarse en los resultados comerciales. Le apasiona utilizar la tecnología para mejorar procesos y flujos de trabajo. Los intereses de Spencer fuera del trabajo incluyen la lección, el pickleball y las finanzas personales.
Spencer Harrison es arquitecto de soluciones asociado en Amazon Web Services (AWS), donde ayuda a las organizaciones del sector sabido a utilizar la tecnología de la estrato para centrarse en los resultados comerciales. Le apasiona utilizar la tecnología para mejorar procesos y flujos de trabajo. Los intereses de Spencer fuera del trabajo incluyen la lección, el pickleball y las finanzas personales.