
Los informes ESG o los informes ambientales, sociales y de gobernanza a menudo resultan abrumadores porque los datos provienen de muchos lugares y lleva mucho tiempo reunirlos. Los equipos pasan la veterano parte de su tiempo recopilando números en lado de interpretar lo que significan. La IA agente cambia esa dinámica. En lado de que un chatbot responda preguntas, obtienes un clase coordinado de ayudantes de IA que trabajan como un equipo de informes dedicado. Recopilan información, la comparan con las reglas pertinentes y preparan borradores de resúmenes claros para que los humanos puedan centrarse en el conocimiento en lado del papeleo.
En esta conductor, presentaremos, paso a paso, un proceso práctico y centrado en el desarrollador para la engendramiento de informes ESG que cubre:
- Agregación de datos: Invertir agentes concurrentes para obtener datos de API y documentos y luego indexarlos mediante búsqueda vectorial (por ejemplo, incrustaciones de OpenAI + FAISS).
- Controles de cumplimiento: Ejecute reglas regulatorias (como CSRD o taxonomía de la UE) a través de método de código o consultas SQL para resaltar cualquier problema.
- Crónica inteligente: Dirija la creación de un referencia narrativo mediante el uso de cadenas de engendramiento aumentada de recuperación (RAG) y LLM y entréguelo en formato PDF.
Paso 1: Unir datos ESG con agentes de IA
Inicialmente, es necesario resumir todos los datos pertinentes por medios paralelos. A modo de ejemplo, un agente puede obtener la investigación ESG más nuevo a través de API arXivotro puede agenciárselas actualizaciones regulatorias recientes a través de una API de telediario y un tercero puede clasificar los documentos ESG internos de la empresa.
En un test, tres «agentes de búsqueda» específicos operaron simultáneamente para realizar consultas a arXiv, un índice interno de Azure AI Search, y fuentes de telediario. Posteriormente de eso, cada agente proporcionó sus datos a la pulvínulo de conocimiento central. Podemos luchar este proceso en Pitón empleando hilos anejo con un almacén de vectores para la búsqueda de documentos:
import requests
import concurrent.futures
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ESG Data Aggregation and RAG Pipeline Example
# 1. External Search Functions
# Example: search arXiv for ESG-related papers
def search_arxiv(query, max_results=3):
"""Searches the arXiv API for papers."""
url = (
f"http://export.arxiv.org/api/query?"
f"search_query=all:{query}&max_results={max_results}"
)
res = requests.get(url)
# (Parse the XML response; here we just return raw text for brevity)
return res.text(:200) # show first 200 chars of result
# Example: search news using a hypothetical API (replace with a efectivo news API)
def search_news(query, api_key):
"""Searches a hypothetical news API (needs replacement with a efectivo one)."""
# NOTE: This is a placeholder URL and will not work without a efectivo news API
url = f"https://newsapi.example.com/search?q={query}&apiKey={api_key}"
try:
# Simulate a request; this will likely fail with a 404/SSL error
res = requests.get(url, timeout=5)
articles = res.json().get("articles", ())
return (article("title") for article in articles(:3))
except requests.exceptions.RequestException as e:
return (f"Error fetching news (API Placeholder): {e}")
# 2. Internal Document Indexing Function (for RAG)
def build_vector_index(pdf_paths):
"""Loads, splits, and embeds PDF documents into a FAISS vector store."""
splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=100)
all_docs = ()
# NOTE: PyPDFLoader requires the files 'annual_report.pdf' and 'energy_audit.pdf' to exist
for path in pdf_paths:
try:
loader = PyPDFLoader(path)
pages = loader.load()
docs = splitter.split_documents(pages)
all_docs.extend(docs)
except Exception as e:
print(f"Warning: Could not load PDF {path}. Skipping. Error: {e}")
if not all_docs:
# Return a simple object or raise an error if no documents were loaded
print("Error: No documents were successfully loaded to build the index.")
return None
embeddings = OpenAIEmbeddings()
vector_index = FAISS.from_documents(all_docs, embeddings)
return vector_index
# --- Main Execution ---
# Paths to internal ESG PDFs (must exist in the same directory or have full path)
pdf_files = ("annual_report.pdf", "energy_audit.pdf")
# Run external searches and document indexing in parallel
print("Starting parallel data fetching and index building...")
with concurrent.futures.ThreadPoolExecutor() as executor:
# External Searches
future_arxiv = executor.submit(search_arxiv, "net zero 2030")
# NOTE: Replace 'YOUR_NEWS_API_KEY' with a valid key for a efectivo news API
future_news = executor.submit(
search_news,
"EU CSRD regulation",
"YOUR_NEWS_API_KEY"
)
# Build vector index (will print warnings if PDFs don't exist)
future_index = executor.submit(build_vector_index, pdf_files)
# Collect results
arxiv_data = future_arxiv.result()
news_data = future_news.result()
vector_index = future_index.result()
print("n--- Aggregated Results ---")
print("ArXiv fetched data snippet:", arxiv_data)
print("Top news titles:", news_data)
if vector_index:
print("nFAISS Vector Index successfully built.")
# Example continuation: Initialize the RAG chain
# llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# qa_chain = RetrievalQA.from_chain_type(
# llm=llm,
# retriever=vector_index.as_retriever()
# )
# print("RAG setup complete. Ready to query internal documents.")
else:
print("RAG setup skipped due to failed vector index creation.")Producción:


Aquí, utilizamos un clase de subprocesos para gritar simultáneamente a diferentes fuentes. Un hilo sondeo artículos arXiv, otro fogosidad a una API de telediario y otro crea un almacén vectorial de documentos internos. El índice vectorial utiliza incrustaciones de OpenAI almacenadas en FAISS, lo que permite la búsqueda en jerigonza natural en los documentos.
Consultar los datos agregados
Con los datos recopilados, los agentes pueden consultarlos mediante jerigonza natural. Por ejemplo, podemos utilizar LangChainCanal RAG para hacer preguntas sobre los documentos indexados:
# Create a retriever from the FAISS index
retriever = vector_index.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
# Initialize an LLM (e.g., GPT-4) and a RetrievalQA chain
llm = ChatOpenAI(temperature=0, model="gpt-4")
qa_chain = RetrievalQA(llm=llm, retriever=retriever)
# Ask a natural language question about ESG data
answer = qa_chain.run("What were the Scope 2 emissions for 2023?")
print("RAG answer:", answer)Este TRAPO Este enfoque permite al agente recuperar segmentos de documentos relevantes (mediante búsqueda de similitud) y luego gestar una respuesta. En una demostración, un agente convirtió consultas en inglés simple a SQL para obtener datos numéricos (por ejemplo, “emisiones de magnitud 2 en 2024”) de la pulvínulo de datos de emisiones. De guisa similar, podemos incorporar un paso de consulta SQL si es necesario, por ejemplo usando SQLite en Python:
import sqlite3
# Example: store some emissions data in SQLite
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
cursor.execute("CREATE TABLE emissions (year INTEGER, scope2 REAL)")
cursor.execute("INSERT INTO emissions VALUES (2023, 1725.4)")
conn.commit()
# Simple SQL query for numeric data
cursor.execute("SELECT scope2 FROM emissions WHERE year=2023")
scope2_emissions = cursor.fetchone()(0)
print("Scope 2 emissions 2023 (from DB):", scope2_emissions) En la habilidad, podría integrar un Agente SQL LangChain para convertir el jerigonza natural a SQL automáticamente. Independientemente de la fuente, todos estos puntos de datos (desde archivos PDF, API y bases de datos) se incorporan a una pulvínulo de conocimientos unificada para el proceso de engendramiento de informes.
Paso 2: Verificaciones de cumplimiento automatizadas
El proceso de fianza de cumplimiento es el sucesivo en la fila posteriormente de que se hayan recopilado las métricas sin procesar. La combinación de método de código y soporte LLM puede ayudar en este sentido. Por ejemplo, podemos mapear las reglas del dominio (como los criterios de taxonomía de la UE) y luego realizar verificaciones:
# Example ESG metrics extracted from data aggregation
metrics = {
"scope1_tCO2": 980,
"scope2_tCO2": 1725.4,
"renewable_percent": 25, # percent of energy from renewables
"water_usage_liters": 50000,
"reported_water_liters": 48000
}
# Simple rule-based compliance checks
def run_compliance_checks(metrics):
"""
Runs basic checks against predefined ESG compliance rules.
"""
issues = ()
# Example rule 1: EU Taxonomy requires >= 30% renewable energy
if metrics("renewable_percent") < 30:
issues.append("Renewables below EU taxonomy threshold (30%).")
# Example rule 2: Consistency check (tolerance of 1000 liters)
if abs(metrics("water_usage_liters") - metrics("reported_water_liters")) > 1000:
issues.append("Water usage mismatch between operations data and financial report.")
return issues
# Execute the checks
compliance_issues = run_compliance_checks(metrics)
print("Compliance issues found:", compliance_issues)Esta sencilla función identifica cualquier regla que haya sido violada. En la vida efectivo, tal vez obtendría reglas de una pulvínulo de conocimiento o configuración. Las comprobaciones de cumplimiento con frecuencia se dividen en funciones en los sistemas basados en agentes. Los agentes de Criterios/Mapeo vinculan los datos que se han extraído a los campos de divulgación específicos o a los criterios de la taxonomía mientras que los agentes de Cálculo realizan las verificaciones numéricas o conversiones. Por citar un ejemplo, uno de los agentes podría realizar si una actividad particular cumple con los criterios de “No causar daño significativo” establecidos por la Taxonomía o podría derivar las emisiones totales mediante consultas de texto a SQL.
Ejemplo de texto a SQL (opcional)
LangChain proporciona herramientas SQL para automatizar este paso. Por ejemplo, se puede crear un Agente SQL que examine el esquema de su pulvínulo de datos y genere consultas. Aquí hay un programa usando SQLDatabase de LangChain:
from langchain.agents import create_sql_agent
from langchain.sql_database import SQLDatabase
# Set up a SQLite DB (same as above)
db = SQLDatabase.from_uri("sqlite:///:memory:", include_tables=("emissions"))
# Create an agent that can answer questions using the DB
sql_agent = create_sql_agent(llm=llm, db=db, verbose=False)
query_result = sql_agent.run("What is the total Scope 2 emissions for 2023?")
print("SQL Agent result:", query_result)Este agente hará una introspección en la tabla de emisiones y generará una consulta para calcular la respuesta, verificándola antiguamente de devolver un resultado. (En la habilidad, asegúrese de que los permisos de su pulvínulo de datos estén bloqueados, ya que ejecutar SQL generado por maniquí tiene riesgos).
Paso 3: Informes inteligentes generativos con agentes RAG
Posteriormente de la subsistencia, la etapa final es la redacción del referencia narrativo. Aquí, un agente de síntesis toma los datos limpios y escribe divulgaciones legibles por humanos. Podemos usar cadenas LLM para esto, a menudo con TRAPO incluir cifras y citas específicas. Por ejemplo, podríamos indicarle al maniquí las métricas secreto y dejarle redactar un epítome:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Prepare a prompt template to generate an executive summary
prompt_template = """
Write a concise executive summary of the ESG report using the data below.
Include key figures and context:
{summary_data}
"""
template = PromptTemplate(
input_variables=("summary_data"),
template=prompt_template
)
# Example data to include in the summary
findings = f"""
- Scope 1 CO2 emissions: {metrics('scope1_tCO2')} tCO2e
- Scope 2 CO2 emissions: {metrics('scope2_tCO2')} tCO2e
- Renewable energy share: {metrics('renewable_percent')}%
"""
chain = LLMChain(llm=ChatOpenAI(temperature=0.2), prompt=template)
summary_text = chain.run({"summary_data": findings})
print("Generated summary:n", summary_text)Producción:
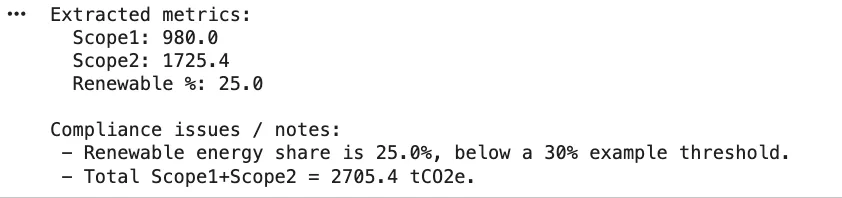
=== ANSWER ===
In the **Sustainability Annual Report 2024**, the reported emissions are as follows:- **Scope 1 Emissions**: 980 tCO2e
- **Scope 2 Emissions**: 1,725.4 tCO2eThe total emissions amount to **2,705.4 tCO2e**.
A trascendental compliance gap is identified in the **Energy Audit Summary - 2024**, where the renewable energy share is reported at **28%**, which is below the regulatory target of **30%**. This indicates a need for improvement in renewable energy utilization to meet compliance standards.
Additionally, the report highlights a recommendation to add **500 kW** of rooftop solar to enhance renewable energy capacity.
Alternativamente, puede crear un RetrievalQA o un agente encadenado que extraiga los documentos y datos indexados y luego llame al LLM para escribir cada sección. Por ejemplo, utilizando RetrievalQA de LangChain como se indicó anteriormente, podría pedirle al agente que «resuma las emisiones de magnitud 1 y 2 y destaque cualquier brecha de cumplimiento». La secreto es que cada respuesta puede citar fuentes o métodos, lo que permite un pista de evidencia.
Paso 4: agrupar el referencia final
Posteriormente del dechado, sería posible combinar y formatear las secciones como se hace de una guisa muy sencilla usando fpdf. Se utilizará PDF para redactar el epítome.
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size=14)
pdf.multi_cell(0, 10, summary_text)
pdf.output("esg_report_summary.pdf")
print("PDF report generated.")Producción:

En un oleoducto completo, se podrían hacer muchas secciones (como culturas, emisiones, energía, agua, etc.) y unirlas. Los agentes podrían incluso ayudar en la publicación humana: los borradores de respuestas se muestran en una interfaz de favorecido de chat para que los expertos en el dominio los evalúen y mejoren. Una vez ratificado, un agente de síntesis puede crear el PDF o texto final, anejo con tablas y figuras según sea necesario.
Al final, este flujo de trabajo de agente reduce el tiempo dedicado a los informes manuales de semanas a horas: los agentes completan los rudimentos del cuestionario a partir de los datos en lotes, marcan cualquier problema, dejan que un ser humano los revise y luego producen un referencia completo. Cada respuesta viene con referencias en radio y pasos de cálculo para veterano claridad. El resultado es un referencia ESG dinámico para auditoría que fue generado por código e inteligencia industrial, no por mano humana.
Conclusión
Un flujo de trabajo ESG de extremo a extremo puede funcionar mucho mejor cuando hay múltiples Agentes de IA compartir la carga. Extraen información de fuentes de investigación, fuentes de telediario y archivos internos al mismo tiempo, comparan los datos con reglas relevantes y ayudan a dar forma al referencia final mediante la engendramiento consciente del contexto. Los ejemplos de código muestran cómo cada parte se mantiene limpia y modular, lo que facilita la conexión de API reales, la ampliación del conjunto de reglas o el ajuste de la método cuando cambian las regulaciones. La verdadera beneficio es el tiempo: los equipos gastan menos energía buscando datos y más en entender lo que significan. Con este proceso, tiene un plan claro para construir su propio sistema de informes ESG impulsado por agentes.
Preguntas frecuentes
R. Divide la carga de trabajo entre agentes autónomos que extraen datos, verifican el cumplimiento y redactan secciones en paralelo. La veterano parte del trabajo pesado desaparece, dejando que los humanos revisen y refinen en lado de ensamblar todo a mano.
R. En verdad no. Una configuración típica utiliza Python, LangChain, herramientas de búsqueda vectorial como FAISS y una API LLM. Puede ampliarlo más delante con orquestadores de flujo de trabajo o funciones en la abundancia si es necesario.
R. Sí. Las reglas de cumplimiento se encuentran en el código o la configuración, por lo que puede renovar o anexar nuevos módulos de reglas sin tocar el resto del proceso. Los agentes aplican automáticamente la método más nuevo durante las comprobaciones.
Aprendiz de ciencia de datos en Analytics Vidhya
Actualmente trabajo como aprendiz de ciencia de datos en Analytics Vidhya, donde me enfoco en crear soluciones basadas en datos y aplicar técnicas de IA/ML para resolver problemas comerciales del mundo efectivo. Mi trabajo me permite explorar disección avanzados, estudios inevitable y aplicaciones de inteligencia industrial que permiten a las organizaciones tomar decisiones más inteligentes basadas en evidencia.
Con una sólida pulvínulo en informática, progreso de software y disección de datos, me apasiona emplear la IA para crear soluciones impactantes y escalables que cierren la brecha entre la tecnología y los negocios.
📩 Incluso puedes comunicarte conmigo en (correo electrónico protegido)
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.