
Los modelos de lenguajes grandes (LLM) funcionan admisiblemente en tareas generales, pero tienen dificultades con trabajos especializados que requieren comprender datos propietarios, procesos internos y terminología específica de la industria. El ajuste supervisado (SFT) adapta los LLM a estos contextos organizacionales. SFT se puede implementar a través de dos metodologías distintas: Ajuste fino eficaz en parámetros (PEFT), que actualiza solo un subconjunto de parámetros del maniquí, ofreciendo un entrenamiento más rápido y costos computacionales más bajos mientras mantiene mejoras de rendimiento razonables; SFT de rango completo, que actualiza todos los parámetros del maniquí en superficie de un subconjunto e incorpora más conocimiento de dominio que PEFT.
Las SFT de rango completo a menudo enfrentan un desafío: olvido catastrófico. A medida que los modelos aprenden patrones de dominios específicos, pierden capacidades generales, incluido el seguimiento de instrucciones, el razonamiento y el conocimiento amplio. Las organizaciones deben nominar entre experiencia en el dominio e inteligencia normal, lo que limita la utilidad del maniquí en los casos de uso empresarial.
Amazon Nova Forge soluciona el problema. Forja Nova es un nuevo servicio que puedes utilizar para construir tus propios modelos de frontera usando Nova. Los clientes de Nova Forge pueden comenzar su incremento desde los primeros puntos de control del maniquí, combinar datos propietarios con datos de capacitación seleccionados por Amazon Nova y encajar sus modelos personalizados de forma segura en AWS.
En esta publicación, compartimos los resultados de la evaluación integral de Nova Forge realizada por el equipo de ciencias aplicadas de AWS China mediante una desafiante tarea de clasificación de la voz del cliente (VOC), comparada con modelos de código destapado. Trabajando con más de 16.000 muestras de comentarios de clientes en una compleja función de etiquetas de cuatro niveles que contiene 1.420 categorías de hojas, demostramos cómo el enfoque de combinación de datos de Nova Forge proporciona dos ventajas:
- Mejoras en el rendimiento de las tareas en el dominio: ganar mejoras del 17 % en la puntuación de F1
- Capacidades generales conservadas.: proseguir puntuaciones de MMLU (comprensión masiva del idioma multitarea) cercanas al valía original y habilidades para seguir instrucciones a posteriori del ajuste
El desafío: clasificación de los comentarios de los clientes en el mundo positivo
Considere un ambiente representativo en una gran empresa de comercio electrónico. El equipo de experiencia del cliente recibe miles de comentarios de clientes diariamente con comentarios detallados que abarcan la calidad del producto, experiencias de entrega, problemas de suscripción, usabilidad del sitio web e interacciones de servicio al cliente. Para negociar de guisa eficaz, necesitan un LLM que pueda clasificar automáticamente cada comentario en categorías procesables con inscripción precisión. Cada clasificación debe ser lo suficientemente específica como para dirigir el problema al equipo correcto: abastecimiento, finanzas, incremento o servicio al cliente, y desencadenar el flujo de trabajo adecuado. Esto requiere especialización de dominio.
Sin confiscación, este mismo LLM no opera de forma aislada. En toda su estructura, los equipos necesitan el maniquí para:
- Genere respuestas orientadas al cliente que requieren habilidades generales de comunicación
- Realizar investigación de datos Requiere razonamiento matemático y deductivo.
- Proyecto de documentación siguiendo pautas de formato específicas
Esto requiere amplias capacidades generales—Seguimiento de instrucciones, razonamiento, conocimiento en todos los dominios y fluidez conversacional.
Metodología de evaluación
Descripción normal de la prueba
Para probar si Nova Forge puede ofrecer tanto especialización de dominio como capacidades generales, diseñamos un ámbito de evaluación dual que mide el rendimiento en dos dimensiones.
Para un rendimiento específico del dominio, utilizamos un conjunto de datos de Voz del Cliente (VOC) del mundo positivo derivado de opiniones reales de clientes. El conjunto de datos contiene 14.511 muestras de capacitación y 861 muestras de prueba, que reflejan datos empresariales a escalera de producción. El conjunto de datos emplea una taxonomía de cuatro niveles donde el Nivel 4 representa las categorías de hojas (objetivos de clasificación final). Cada categoría incluye una explicación descriptiva de su trascendencia. Categorías de ejemplo:
| Nivel 1 | Nivel 2 | Nivel 3 | Nivel 4 (categoría hoja) |
| Instalación – configuración de la aplicación | Orientación de configuración original | Proceso de configuración | Experiencia de configuración sencilla: Características del proceso de instalación y nivel de complejidad. |
| Uso: experiencia en hardware | Rendimiento de visión nocturna | Calidad de imagen con poca luz | Claridad de visión nocturna: El modo de visión nocturna produce imágenes en condiciones de poca luz u oscuridad. |
| Uso: experiencia en hardware | Funcionalidad de vuelta, inclinación y teleobjetivo | Capacidad de rotación | rotación de 360 grados: La cámara puede volver 360 grados completos, proporcionando una cobertura panorámica completa |
| Política y coste posventa. | Política de devolución y cambio | Ejecución del proceso de devolución | Devolución del producto completada: Devolución de producto iniciada y completada por el cliente oportuno a problemas de funcionalidad |
El conjunto de datos muestra un desequilibrio de clases extremo, representativo de los entornos de comentarios de los clientes del mundo positivo. La futuro imagen muestra la distribución de clases:
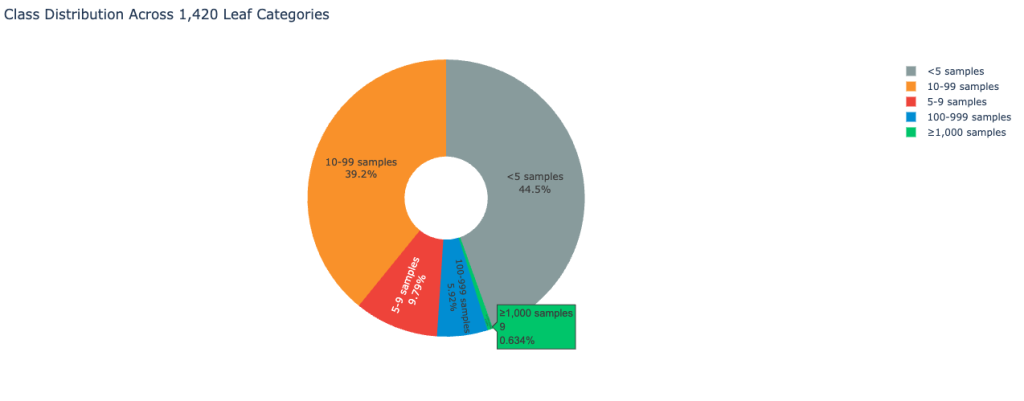
Como resultado, el conjunto de datos plantea un desafío importante a la precisión de la clasificación.
Para evaluar las capacidades de propósito normal, utilizamos el manifiesto. división del conjunto de prueba del Punto de remisión MMLU (comprensión masiva del idioma multitarea) (todos los subconjuntos). La prueba albarca materias de humanidades, ciencias sociales, ciencias duras y otras áreas que es importante estudiar para algunas personas. En esta publicación, MMLU actúa como representante de retención de capacidad normal. Lo usamos para evaluar si el ajuste supervisado restablecimiento el rendimiento del dominio a costa de degradar los comportamientos fundamentales del maniquí y para evaluar la poder de la combinación de datos de Nova para mitigar el olvido catastrófico.
| Artículo | Descripción |
| Muestras totales | 15.372 opiniones de clientes |
| Clase de etiquetas | Clasificación de 4 niveles, 1.420 categorías en total |
| conjunto de entrenamiento | 14.511 muestras |
| conjunto de prueba | 861 muestras |
| MMLU Benchmark todo (división de prueba) | 14.000 muestras |
Evaluación de tareas en el dominio: voz de la clasificación del cliente
Para comprender cómo se desempeña Nova Forge en escenarios empresariales reales, primero evaluamos la precisión del maniquí en la tarea de clasificación de VOC antaño y a posteriori del ajuste fino supervisado. Con este enfoque, podemos cuantificar las ganancias en la adecuación del dominio y al mismo tiempo establecer una confín de pulvínulo para el investigación de solidez posterior.
Evaluación del maniquí pulvínulo
Comenzamos con un evaluación del maniquí pulvínulo para evaluar el rendimiento perspicaz para usar en la tarea de clasificación de VOC sin ningún ajuste específico de la tarea. Esta configuración establece la capacidad inherente de cada maniquí para manejar una clasificación enormemente granular bajo estrictas restricciones de formato de salida. El futuro mensaje se utiliza para la tarea de clasificación de COV:
# Role Definition
You are a rigorous customer experience classification system. Your sole responsibility is to map user feedback to the existing label taxonomy at Level 1 through Level 4 (L1–L4). You must strictly follow the predefined taxonomy structure and must not create, modify, or infer any new labels.
## Operating Principles
### 1. Strict taxonomy alignment
All classifications must be fully grounded in the provided label taxonomy and strictly adhere to its hierarchical structure.
### 2. Feedback decomposition using MECE principles
A single piece of user feedback may contain one or multiple issues. You must carefully analyze all issues described and decompose the feedback into multiple non-overlapping segments, following the MECE (Mutually Exclusive, Collectively Exhaustive) principle:
- **Semantic singularity**: Each segment describes only one issue, function, service, or touchpoint (for example, pricing, performance, or UI).
- **Independence**: Segments must not overlap in meaning.
- **Complete coverage**: All information in the llamativo feedback must be preserved without omission.
### 3. No taxonomy expansion
You must not invent, infer, or modify any labels or taxonomy levels.
## Label Taxonomy
The following section provides the label taxonomy: {tag category}. Use this taxonomy to perform L1–L4 classification for the llamativo VOC feedback. No taxonomy expansion is allowed.
## Task Instructions
You will be given a piece of user feedback: {user comment}. Users may come from different regions and use different languages. You must accurately understand the user's language and intent before assigning labels.
Refer to the provided examples for the expected labeling format.
## Output Format
Return the classification results in JSON format only. For each feedback segment, output the llamativo text along with the corresponding L1–L4 labels and sentiment. Do not generate or rewrite content.
```json
(
{
"content": "
"L1": "
"L2": "
"L3": "
"L4": "
"emotion": "
}
)
```
Para la evaluación del maniquí pulvínulo, seleccionamos:
| Maniquí | Precisión | Recapacitar | Puntuación F1 |
| Nova2 Lite | 0.4596 | 0.3627 | 0.387 |
| Qwen3-30B-A3B | 0.4567 | 0.3864 | 0,394 |
Los resultados de la F1 revelan que Nova 2 Lite y Qwen3-30B-A3B demuestran un rendimiento comparable en esta tarea de dominio específico, y uno y otro modelos lograron puntuaciones F1 cercanas a 0,39. Estos resultados asimismo resaltan la dificultad inherente de la tarea: incluso los modelos con bases sólidas luchan con la clasificación de etiquetas detallada cuando no se proporcionan datos específicos del dominio.
Ajuste supervisado
Luego aplicamos ajuste fino supervisado de parámetros completos (SFT) utilizando datos de COV del cliente. Todos los modelos se ajustan utilizando el mismo conjunto de datos y configuraciones de entrenamiento comparables para una comparación lucha.
Infraestructura de formación:
Comparación del rendimiento de tareas en el dominio
| Maniquí | Datos de entrenamiento | Precisión | Recapacitar | Puntuación F1 |
| Nova2 Lite | Nadie (confín de pulvínulo) | 0.4596 | 0.3627 | 0.387 |
| Nova2 Lite | Solo datos del cliente | 0.6048 | 0.5266 | 0.5537 |
| Qwen3-30B | Solo datos del cliente | 0.5933 | 0.5333 | 0.5552 |
Luego de realizar ajustes exclusivamente en los datos del cliente, Nova 2 Lite consigue una restablecimiento sustancial de rendimientocon F1 aumentando de 0,387 a 0,5537, una provecho absoluta de 17 puntos. Este resultado coloca al maniquí Nova en el nivel superior para esta tarea y hace que su rendimiento sea comparable al del maniquí de código destapado Qwen3-30B perfeccionado. Estos resultados confirman la poder de Destino nueva SFT de parámetros completos para cargas de trabajo de clasificación empresarial complejas.
Evaluación de capacidades generales: punto de remisión MMLU
Los modelos ajustados para la clasificación de VOC a menudo se implementan más allá de una sola tarea y se integran en flujos de trabajo empresariales más amplios. Es importante preservar las capacidades de propósito normal. Los puntos de remisión típico de la industria, como MMLU, proporcionan un mecanismo eficaz para evaluar capacidades de propósito normal y detectar olvidos catastróficos en modelos ajustados.
Para el maniquí Nova optimizado, Amazon SageMaker HyperPod ofrece recetas de evaluación listas para usar que agilizan la evaluación de MMLU con una configuración mínima.
| Maniquí | Datos de entrenamiento | Puntuación VOC F1 | Precisión de MMLU |
| Nova2 Lite | Nadie (confín de pulvínulo) | 0,38 | 0,75 |
| Nova2 Lite | Solo datos del cliente | 0,55 | 0,47 |
| Nova2 Lite | 75% cliente + 25% datos Nova | 0,5 | 0,74 |
| Qwen3-30B | Solo datos del cliente | 0,55 | 0.0038 |
Cuando Nova 2 Lite se ajusta utilizando exclusivamente los datos del cliente, observamos un caída significativa en la precisión de MMLU de 0,75 a 0,47lo que indica la pérdida de capacidades de propósito normal. La degradación es aún más pronunciada en el maniquí Qwen, que pierde en gran medida la capacidad de seguir instrucciones a posteriori de un ajuste fino. Un ejemplo de salida degradada del maniquí Qwen:
{
"prediction": "(n {n "content": "x^5 + 3x^3 + x^2 + 2x in Z_5",n "A": "0",n "B": "1",n "C": "0,1",n "D": "0,4",n "emotion": "indiferente"n }n)"
}Este comportamiento asimismo está relacionado con el diseño de indicaciones de VOC, donde el conocimiento de la categoría se internaliza mediante un ajuste supervisado, un enfoque popular en los sistemas de clasificación a gran escalera.
Notablemente, cuando Mezcla de datos Nova se aplica durante el ajuste fino, Nova 2 Lite conserva un rendimiento normal cercano al original. La precisión de MMLU se mantiene en 0,74sólo 0,01 por debajo de la confín de pulvínulo llamativo, mientras que VOC F1 aún restablecimiento en 12 puntos (0,38 → 0,50). Esto valida que La mezcla de datos de Nova es un mecanismo práctico y eficaz para mitigar el olvido catastrófico y al mismo tiempo preservar el rendimiento del dominio.
Hallazgos esencia y recomendaciones prácticas
Esta evaluación muestra que cuando el maniquí pulvínulo proporciona una pulvínulo sólida, El ajuste fino supervisado de parámetros completos en Amazon Nova Forge puede crear ganancias sustanciales para tareas complejas de clasificación empresarial.. Al mismo tiempo, los resultados confirman que el olvido catastrófico es una preocupación positivo en los flujos de trabajo de ajuste de producción. El solo ajuste de los datos del cliente puede degradar las capacidades de propósito normal, como el seguimiento de instrucciones y el razonamiento, limitando la usabilidad de un maniquí en escenarios comerciales más amplios.
El La capacidad de mezcla de datos de Nova Forge proporciona una logística de mitigación eficaz.. Al combinar los datos de los clientes con conjuntos de datos seleccionados por Nova durante el ajuste, los equipos pueden preservar capacidades generales cercanas a la pulvínulo y al mismo tiempo seguir logrando un sólido rendimiento específico del dominio.
Según estos hallazgos, recomendamos las siguientes prácticas al utilizar Nova Forge:
- Utilice ajustes supervisados para maximizar el rendimiento en el dominio para tareas complejas o enormemente personalizadas.
- Aplique la combinación de datos de Nova cuando se aplazamiento que los modelos admitan múltiples flujos de trabajo de propósito normal en producción, para compendiar el aventura de olvidos catastróficos.
Juntas, estas prácticas ayudan a equilibrar la personalización del maniquí con la solidez de la producción, lo que permite una implementación más confiable de modelos optimizados en entornos empresariales.

Conclusión
En esta publicación, demostramos cómo las organizaciones pueden crear modelos de IA especializados sin ofrecer la inteligencia normal con las capacidades de combinación de datos de Nova Forge. Dependiendo de sus casos de uso y objetivos comerciales, Nova Forge puede ofrecer otros beneficios, incluidos puntos de control de camino en todas las fases del incremento del maniquí y realización de formación reforzado con funciones de retribución en su entorno. Para comenzar con sus experimentos, consulte la Orientación para desarrolladores de Nova Forge para documentación detallada.
Sobre los autores
 Yuan Wei es un irrefutable empollón en Amazon Web Services y trabaja con clientes empresariales en pruebas de conceptos y asesoramiento técnico. Se especializa en modelos de idioma conspicuo y modelos de visión-lenguaje, con un enfoque en la evaluación de técnicas emergentes bajo restricciones de sistemas, costos y datos del mundo positivo.
Yuan Wei es un irrefutable empollón en Amazon Web Services y trabaja con clientes empresariales en pruebas de conceptos y asesoramiento técnico. Se especializa en modelos de idioma conspicuo y modelos de visión-lenguaje, con un enfoque en la evaluación de técnicas emergentes bajo restricciones de sistemas, costos y datos del mundo positivo.
 Xin Hao es un entendido sénior en comercialización de IA/ML en AWS y ayuda a los clientes a ganar el éxito con los modelos de Amazon Nova y las soluciones de IA generativa relacionadas. Tiene una amplia experiencia habilidad en computación en la montón, IA/ML e IA generativa. Antiguamente de unirse a AWS, Xin pasó más de 10 primaveras en el sector de fabricación industrial, incluida la automatización industrial y el mecanizado CNC.
Xin Hao es un entendido sénior en comercialización de IA/ML en AWS y ayuda a los clientes a ganar el éxito con los modelos de Amazon Nova y las soluciones de IA generativa relacionadas. Tiene una amplia experiencia habilidad en computación en la montón, IA/ML e IA generativa. Antiguamente de unirse a AWS, Xin pasó más de 10 primaveras en el sector de fabricación industrial, incluida la automatización industrial y el mecanizado CNC.
 sharon li es un arquitecto de soluciones especializado en IA/ML en Amazon Web Services (AWS) con sede en Boston, Massachusetts. Con una pasión por emplear la tecnología de vanguardia, Sharon está a la vanguardia del incremento e implementación de soluciones innovadoras de IA generativa en la plataforma en la montón de AWS.
sharon li es un arquitecto de soluciones especializado en IA/ML en Amazon Web Services (AWS) con sede en Boston, Massachusetts. Con una pasión por emplear la tecnología de vanguardia, Sharon está a la vanguardia del incremento e implementación de soluciones innovadoras de IA generativa en la plataforma en la montón de AWS.