
Los motores de búsqueda como las imágenes de Google, la búsqueda visual de Bing y la cristal de Pinterest hacen que parezca muy obvio cuando escribimos algunas palabras o subimos una imagen, e al instante, recuperamos las imágenes similares más relevantes de miles de millones de posibilidades.
Bajo el capó, estos sistemas usan enormes pilas de datos y modelos avanzados de educación profundo para metamorfosear tanto las imágenes como el texto en vectores numéricos (llamados incrustaciones) que viven en el mismo «espacio semántico».
En este artículo, construiremos un mini traducción de ese tipo de motor de búsqueda, pero con un conjunto de datos de animales mucho más pequeño con imágenes de tigres, leones, elefantes, cebras, jirafas, pandas y pingüinos.
Puede seguir el mismo enfoque con otros conjuntos de datos como PALMA DE COCO, Fotos Unsplasho incluso tu colección de imágenes personales.
Lo que estamos construyendo
Nuestro motor de búsqueda de imágenes:
- Usar PUNTO LUMINOSO EN UN RADAR para suscitar automáticamente subtítulos (descripciones) para cada imagen.
- Usar ACORTAR para convertir las imágenes y el texto en incrustaciones.
- Acumular esos incrustaciones en un colchoneta de datos vectorial (ChromAdB).
- Te permite inquirir por consulta de texto y recuperar las imágenes más relevantes.
¿Por qué sonar y clip?
BLIP (Pretratenamiento de imagen de habla de bootstrapping)
Blip es un maniquí de educación profundo capaz de producir descripciones textuales para fotos (además conocidas como subtítulos de imágenes). Si nuestro conjunto de datos aún no tiene una descripción, Blip puede crear uno mirando una imagen, como un tigre, y produciendo poco como «un micho naranja noble con rayas negras que se encuentran en la hierba».
Esto ayuda especialmente donde:
- El conjunto de datos es solo una carpeta de imágenes sin ninguna ritual asignada a ellos.
- Y si desea descripciones generalizadas más ricas y naturales para sus imágenes.
Descubrir más: Subtitulación de imágenes usando el educación profundo
Clip (habla contrastante-pre-entrenamiento de imagen)
Clip, por OpenAi, aprende a conectarse texto e imágenes en el interior de un espacio vectorial compartido.
Puede:
- Convertir una imagen en una incrustación.
- Convertir el texto en una incrustación.
- Compare los dos directamente; Si están cerca en este espacio, significa que coinciden semánticamente.
Ejemplo:
- Texto: «Un animal parada con un cuello desprendido» → Vector A
- Imagen de una jirafa → vector B
- Si los vectores A y B están cerca, dice clip, «Sí, esto es probablemente una jirafa».

Implementación paso a paso
Haremos todo en el interior Google Colab, Entonces no necesitas ninguna configuración nave. Puede lograr al cuaderno desde este enlace: Incrustar_similarity_animals
1. Instalar dependencias
Instalaremos Pytorch, Transformers (para Blip y Clip) y ChromAdB (Cojín de datos vectorial). Estas son las principales dependencias para nuestro mini tesina.
!pip install transformers torch -q
!pip install chromadb -q2. Descargue el conjunto de datos
Para esta demostración, usaremos el Conjunto de datos de animales de Kaggle.
import kagglehub
# Download the latest version
path = kagglehub.dataset_download("likhon148/animal-data")
print("Path to dataset files:", path)Moverse con destino a el /contenido Directorio en Colab:
!mv /root/.cache/kagglehub/datasets/likhon148/animal-data/versions/1 /content/Verifique qué clases tenemos:
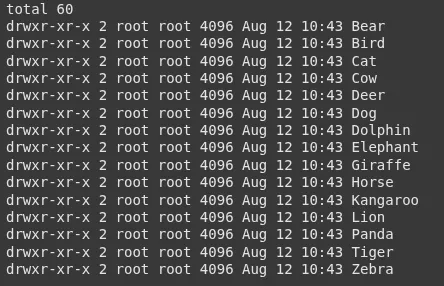
!ls -l /content/1/animal_dataVerás carpetas como:
3. Cuente imágenes por clase
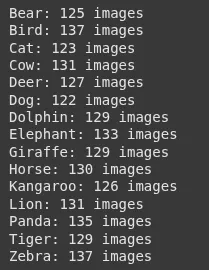
Solo para tener una idea de nuestro conjunto de datos.
import os
base_path = "/content/1/animal_data"
for folder in sorted(os.listdir(base_path)):
folder_path = os.path.join(base_path, folder)
if os.path.isdir(folder_path):
count = len((f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))))
print(f"{folder}: {count} images")Producción:
4. Maniquí de clip de carga
Usaremos clip para incrustaciones.
from transformers import CLIPProcessor, CLIPModel
import torch
model_id = "openai/clip-vit-base-patch32"
processor = CLIPProcessor.from_pretrained(model_id)
model = CLIPModel.from_pretrained(model_id)
device="cuda" if torch.cuda.is_available() else 'cpu'
model.to(device)5. Maniquí de Blip de carga para subtítulos
Blip creará un subtítulo para cada imagen.
from transformers import BlipProcessor, BlipForConditionalGeneration
blip_model_id = "Salesforce/blip-image-captioning-base"
caption_processor = BlipProcessor.from_pretrained(blip_model_id)
caption_model = BlipForConditionalGeneration.from_pretrained(blip_model_id).to(device)6. Prepare las rutas de imagen
Recopilaremos todas las rutas de imagen del conjunto de datos.
image_paths = ()
for root, _, files in os.walk(base_path):
for f in files:
if f.lower().endswith((".jpg", ".jpeg", ".png", ".bmp", ".webp")):
image_paths.append(os.path.join(root, f))7. Producir descripciones e incrustaciones
Para cada imagen:
- PUNTO LUMINOSO EN UN RADAR genera una descripción para esa imagen.
- ACORTAR genera una imagen de inserción basada en los píxeles de la imagen.
import pandas as pd
from PIL import Image
records = ()
for img_path in image_paths:
image = Image.open(img_path).convert("RGB")
# BLIP: Generate caption
caption_inputs = caption_processor(image, return_tensors="pt").to(device)
with torch.no_grad():
out = caption_model.generate(**caption_inputs)
description = caption_processor.decode(out(0), skip_special_tokens=True)
# CLIP: Get image embeddings
inputs = processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
image_features = model.get_image_features(**inputs)
image_features = image_features.cpu().numpy().flatten().tolist()
records.append({
"image_path": img_path,
"image_description": description,
"image_embeddings": image_features
})
df = pd.DataFrame(records)8. Tienda en Chromadb
Empujamos nuestros incrustaciones en una colchoneta de datos vectorial.
import chromadb
client = chromadb.Client()
collection = client.create_collection(name="animal_images")
for i, row in df.iterrows():
collection.add( # upserting to our chroma collection
ids=(str(i)),
documents=(row("image_description")),
metadatas=({"image_path": row("image_path")}),
embeddings=(row("image_embeddings"))
)
print("✅ All images stored in Chroma")9. Cree una función de búsqueda
Dada una consulta de texto:
- El clip lo codifica en una incrustación.
- Cromadb Encuentra los incrustaciones de imagen más cercanas.
- Mostramos los resultados.
import matplotlib.pyplot as plt
def search_images(query, top_k=5):
inputs = processor(text=(query), return_tensors="pt", truncation=True).to(device)
with torch.no_grad():
text_embedding = model.get_text_features(**inputs)
text_embedding = text_embedding.cpu().numpy().flatten().tolist()
results = collection.query(
query_embeddings=(text_embedding),
n_results=top_k
)
print("Top results for:", query)
for i, meta in enumerate(results("metadatas")(0)):
img_path = meta("image_path")
print(f"{i+1}. {img_path} ({results('documents')(0)(i)})")
img = Image.open(img_path)
plt.imshow(img)
plt.axis("off")
plt.show()
return results10. Prueba el motor de búsqueda
Prueba algunas consultas:
search_images("a large wild cat with stripes")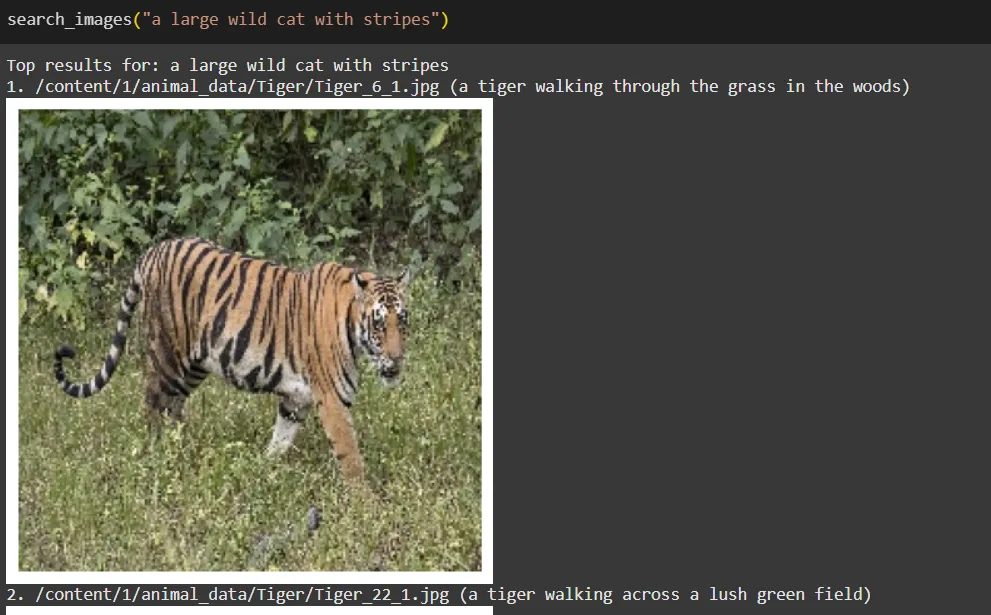
search_images("predator with a mane")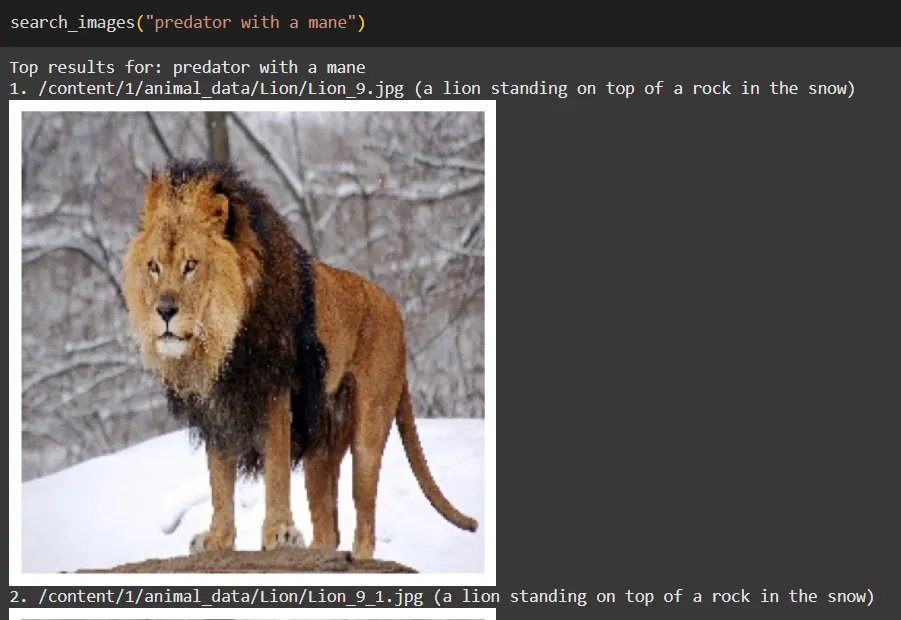
search_images("striped horse-like animal")
Cómo funciona en términos simples
- PUNTO LUMINOSO EN UN RADAR: Mira cada imagen y escribe una lema (este se convierte en nuestro «texto» para la imagen).
- ACORTAR: Convierte uno y otro subtítulos e imágenes en incrustaciones en el mismo espacio.
- Cromadb: Almacena estos incrustaciones y encuentra la coincidencia más cercana cuando buscamos.
- Función de búsqueda (Retriever): Convierte su consulta en una incrustación y le pregunta a ChromadB: «¿Qué imágenes están más cercanas a esta consulta incrustación?»
Recuerde, este motor de búsqueda sería más efectivo si tuviéramos un conjunto de datos mucho más noble, y si utilizariéramos una mejor descripción para cada imagen, haría que incrustaciones fuertemente efectivas en el interior de nuestro espacio de representación unificado.
Limitaciones
- Los subtítulos de Blip pueden ser genéricos para algunas imágenes.
- Las integridades de Clip funcionan correctamente para conceptos generales, pero podrían combatir con diferencias muy específicas de dominio o de cereal fino a menos que se entrenen en datos similares.
- La calidad de la búsqueda depende en gran medida del tamaño del conjunto de datos y la desemejanza.
Conclusión
En esquema, crear un motor de búsqueda de imágenes en miniatura que utiliza representaciones vectoriales de texto e imágenes ofrece oportunidades emocionantes para mejorar la recuperación de imágenes. Al utilizar PUNTO LUMINOSO EN UN RADAR Para subtítulos y clip para la incrustación, podemos construir una aparejo versátil que se adapte a varios conjuntos de datos, desde fotos personales hasta colecciones especializadas.
Mirando con destino a el futuro, las características como la búsqueda de imagen a imagen pueden enriquecer aún más la experiencia del adjudicatario, lo que permite el descubrimiento obvio de imágenes visualmente similares. Por otra parte, aprovechando más noble ACORTAR Los modelos y el ajuste fino en conjuntos de datos específicos pueden aumentar significativamente la precisión de búsqueda.
Este tesina no solo sirve como una colchoneta sólida para la búsqueda de imágenes impulsada por la IA, sino que además invita a una viejo exploración e innovación. Abrace el potencial de esta tecnología y transformamos la forma en que nos comprometemos con las imágenes.
Preguntas frecuentes
A. BLIP genera subtítulos para las imágenes, creando descripciones textuales que pueden integrarse y compararse con las consultas de búsqueda. Esto es útil cuando el conjunto de datos aún no tiene etiquetas.
A. El clip convierte tanto las imágenes como el texto en integridades en el interior del mismo espacio vectorial, lo que permite la comparación directa entre ellas para encontrar coincidencias semánticas.
A. ChromadB almacena los incrustaciones y recupera las imágenes más relevantes al encontrar las coincidencias más cercanas con la incrustación de una consulta de búsqueda.
Genai Intern @ Analytics Vidhya | Zaguero año @ vit chennai
Apasionado por la IA y el educación maquinal, estoy ansioso por sumergirme en roles como ingeniero de IA/ML o irrefutable de datos donde puedo tener un impacto auténtico. Con una astucia singular para un educación rápido y un inclinación por el trabajo en equipo, estoy emocionado de traer soluciones innovadoras y avances de vanguardia a la mesa. Mi curiosidad me impulsa a explorar la IA en varios campos y tomar la iniciativa de profundizar en la ingeniería de datos, asegurando que me mantenga a la vanguardia y entregue proyectos impactantes.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.