
Los datos son esenciales para las decisiones comerciales modernas. Muchos empleados, sin incautación, no están familiarizados con SQL. Esto crea un cuello de botella entre preguntas y respuestas. Un sistema de texto a SQL resuelve este problema directamente. Traduce preguntas simples en consultas de bases de datos. Este artículo le muestra cómo construir un turbina SQL. Seguiremos las ideas del equipo de ingeniería de texto a SQL de Pinterest. Aprenderá a convertir el lengua natural en SQL. Asimismo utilizaremos técnicas avanzadas como RAG para la selección de mesa.
Comprender el enfoque de Pinterest
Pinterest quería hacer que los datos sean accesibles para todos. Sus empleados necesitaban ideas de vastas conjuntos de datos. La mayoría de ellos no fueron Sql expertos. Este desafío condujo a la creación de la plataforma Text-to SQL de Pinterest. Su delirio ofrece una excelente hoja de ruta para construir herramientas similares.
La primera traducción
Su primer sistema fue sencillo. Un legatario haría una pregunta y igualmente enumeraría las tablas de la almohadilla de datos que creía que eran relevantes. El sistema generaría una consulta SQL.
Echemos un vistazo más de cerca a su cimentación:
El legatario hace una pregunta analítica, eligiendo las tablas para ser utilizadas.
- Los esquemas de tabla relevantes se recuperan de la tienda de metadatos de tabla.
- La pregunta, el dialecto SQL seleccionado y los esquemas de tabla se compilan en una solicitud de texto a SQL.
- El aviso se alimenta al LLM.
- Se genera y se muestra una respuesta de transmisión al legatario.
Este enfoque funcionó, pero tenía un defecto importante. Los usuarios a menudo no tenían idea de qué tablas contenían sus respuestas.
La segunda traducción
Para resolver esto, su equipo construyó un sistema más inteligente. Usó una técnica emplazamiento Reproducción de recuperación de una coexistentes (trapo). En emplazamiento de pedirles tablas al legatario, el sistema las encontró automáticamente. Buscó una colección de descripciones de tabla para encontrar las más relevantes para la pregunta. Este uso de RAG para la selección de mesa hizo que la utensilio fuera mucho más ligera de usar.
- Se emplea un trabajo fuera de cadena para originar un índice vectorial de resúmenes de tablas y consultas históricas contra ellos.
- Supongamos que el legatario no especifica ninguna tabla. En ese caso, su pregunta se transforma en incrustaciones, y se realiza una búsqueda de similitud contra el índice de vectores para inferir la parte superior ideal mesas adecuadas.
- La parte superior ideal Las tablas, unido con el esquema de la tabla y la pregunta analítica, se compilan en un aviso para LLM Para optar la parte superior K tablas más relevantes.
- La parte superior K Las tablas se devuelven al legatario para su fuerza o perturbación.
- El proceso estereotipado de texto a SQL se reanuda con las tablas confirmadas por el legatario.
Replicaremos este poderoso enfoque de dos pasos.
Nuestro plan: una replicación simplificada
Esta consejo lo ayudará a construir un turbina SQL en dos partes. Primero, crearemos el motor central que convierte el lengua natural en SQL. En segundo emplazamiento, agregaremos la función inteligente de búsqueda de mesa.
- El sistema central: Construiremos una dependencia básica. Se necesita una pregunta y una letanía de nombres de tabla para crear una consulta SQL.
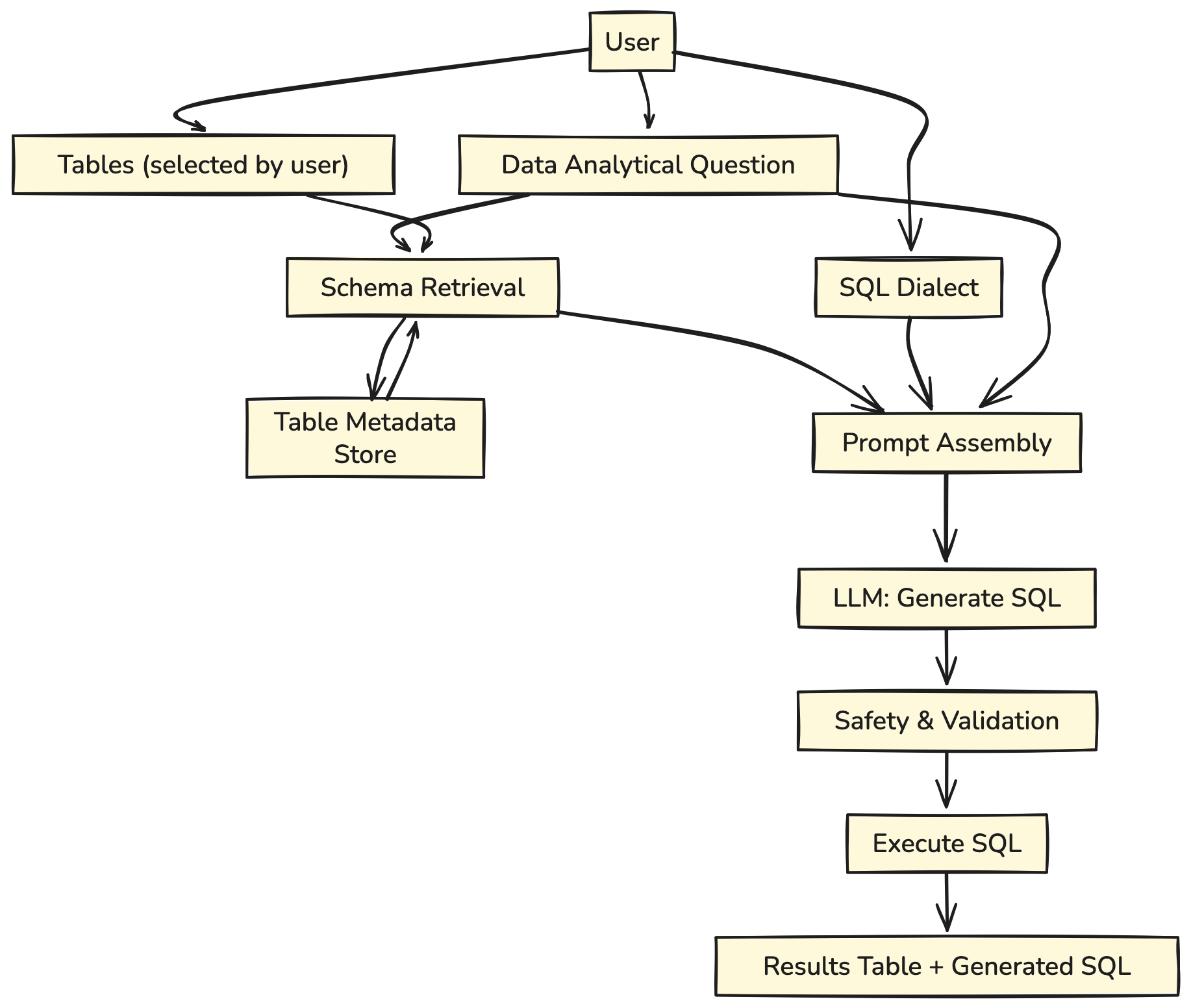
- Entrada del legatario: Proporciona una pregunta analítica, tablas seleccionadas y dialecto SQL.
- Recuperación del esquema: El sistema obtiene esquemas de tabla relevantes de la tienda de metadatos.
- Ensamblaje rápido: Combina preguntas, esquemas y dialecto en un aviso.
- Reproducción LLM: El maniquí emite la consulta SQL.
- Garra y ejecución: La consulta se verifica por seguridad, se ejecuta y se devuelven los resultados.
- El sistema mejorado de trapo: agregaremos un retriever. Este componente sugiere automáticamente las tablas correctas para cualquier pregunta.
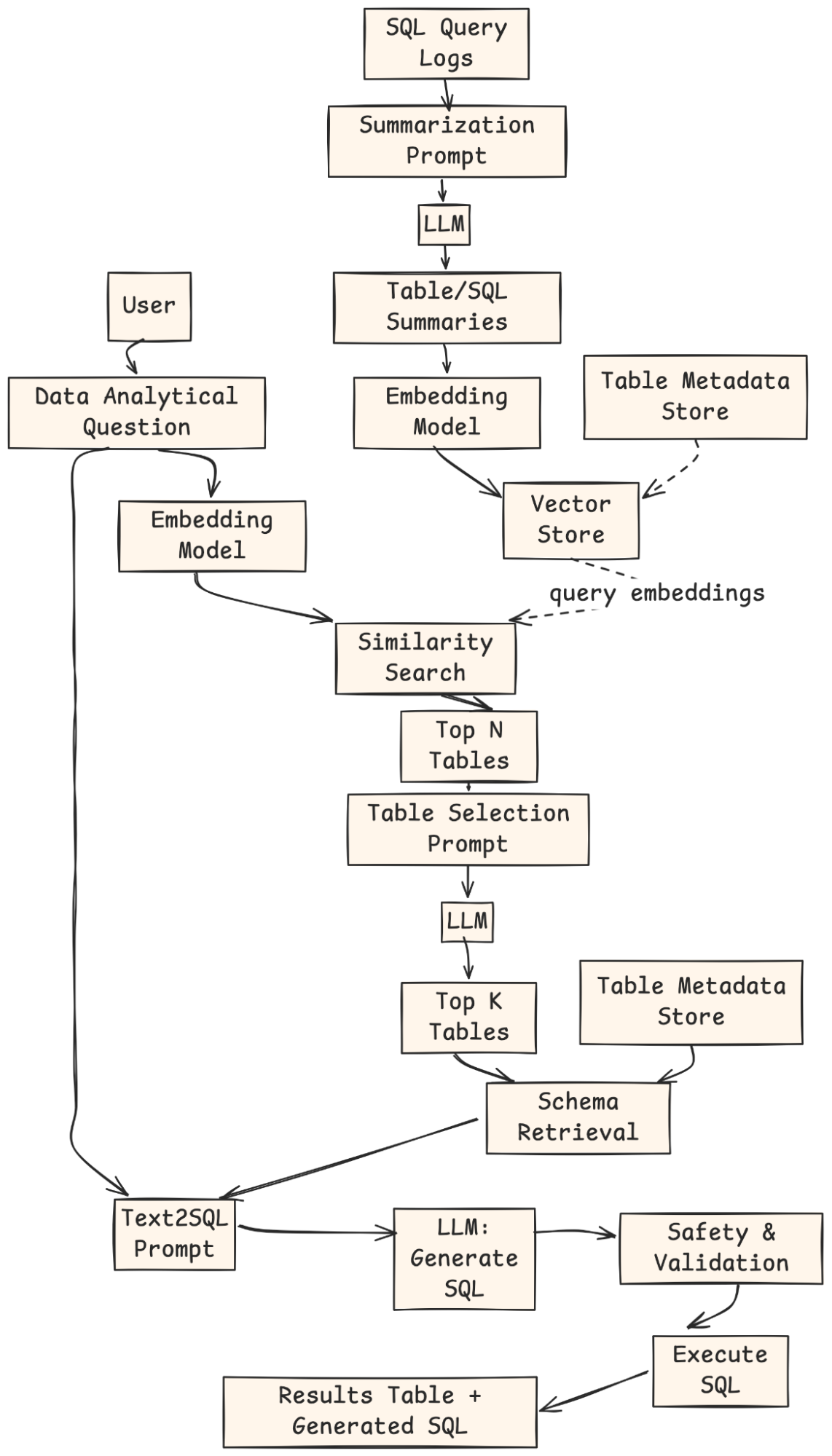
- Indexación fuera de cadena: Los registros de consultas SQL se sinopsis mediante un LLM, integrado y almacenados en un índice de vectores con metadatos.
- Consulta de legatario: El legatario proporciona una pregunta analítica en lengua natural.
- Recuperación: La pregunta está integrada, coincidía con la tienda Vector, y se devuelven las tablas candidatas TOP-N.
- Selección de tabla: Un LLM clasifica y selecciona las tablas más relevantes de Top-K.
- Recuperación de esquema y indicación: El sistema obtiene esquemas para esas tablas y construye un mensaje de texto a SQL.
- Reproducción SQL: Un LLM genera la consulta SQL.
- Garra y ejecución: La consulta se verifica, ejecuta y los resultados + SQL se devuelven al legatario.
Usaremos Pitón, Langchainy OpenAi para construir este sistema de texto a SQL. Una almohadilla de datos SQLite en memoria actuará como nuestra fuente de datos.
Dirección experiencia: construir su propio turbina SQL
Comencemos a construir nuestro sistema. Siga estos pasos para crear un prototipo de trabajo.
Paso 1: Configuración de su entorno
Primero, instalamos las bibliotecas de Python necesarias. Langchain nos ayuda a conectar componentes. Langchain-Openai proporciona la conexión al LLM. FAISS ayuda a crear nuestro Retriever, y Pandas muestra muy perfectamente datos.
!pip install -qU langchain langchain-openai faiss-cpu pandas langchain_communityA continuación, debe configurar su tecla API OpenAI. Esta secreto permite que nuestra aplicación use los modelos de OpenAI.
import os
from getpass import getpass
OPENAI_API_KEY = getpass("Enter your OpenAI API key: ")
os.environ("OPENAI_API_KEY") = OPENAI_API_KEYPaso 2: simulando la almohadilla de datos
Un sistema de texto a SQL necesita una almohadilla de datos para consultar. Para esta demostración, creamos una almohadilla de datos SQLite simple en memoria. Contendrá tres tablas: usuarios, alfileres y tableros. Esta configuración imita una traducción básica de la estructura de datos de Pinterest.
import sqlite3
import pandas as pd
# Create a connection to an in-memory SQLite database
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
# Create tables
cursor.execute('''
CREATE TABLE users (
user_id INTEGER PRIMARY KEY,
username TEXT NOT NULL,
join_date DATE NOT NULL,
country TEXT
)
''')
cursor.execute('''
CREATE TABLE pins (
pin_id INTEGER PRIMARY KEY,
user_id INTEGER,
board_id INTEGER,
image_url TEXT,
description TEXT,
created_at DATETIME,
FOREIGN KEY(user_id) REFERENCES users(user_id),
FOREIGN KEY(board_id) REFERENCES boards(board_id)
)
''')
cursor.execute('''
CREATE TABLE boards (
board_id INTEGER PRIMARY KEY,
user_id INTEGER,
board_name TEXT NOT NULL,
category TEXT,
FOREIGN KEY(user_id) REFERENCES users(user_id)
)
''')
# Insert sample data
cursor.execute("INSERT INTO users (user_id, username, join_date, country) VALUES (1, 'alice', '2023-01-15', 'USA')")
cursor.execute("INSERT INTO users (user_id, username, join_date, country) VALUES (2, 'bob', '2023-02-20', 'Canada')")
cursor.execute("INSERT INTO boards (board_id, user_id, board_name, category) VALUES (101, 1, 'DIY Crafts', 'DIY')")
cursor.execute("INSERT INTO boards (board_id, user_id, board_name, category) VALUES (102, 1, 'Travel Dreams', 'Travel')")
cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1001, 1, 101, 'Handmade birthday card', '2024-03-10 10:00:00')")
cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1002, 2, 102, 'Eiffel Tower at night', '2024-05-15 18:30:00')")
cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1003, 1, 101, 'Knitted scarf pattern', '2024-06-01 12:00:00')")
conn.commit()
print("Database created and populated successfully.")Producción:

Paso 3: Construyendo la dependencia de texto central a SQL
El maniquí de idioma no puede ver nuestra almohadilla de datos directamente. Necesita conocer las estructuras o esquemas de la tabla. Creamos una función para obtener el CREATE TABLE declaraciones. Esta información le dice al maniquí sobre columnas, tipos de datos y claves.
def get_table_schemas(conn, table_names):
"""Fetches the CREATE TABLE statement for a list of tables."""
schemas = ()
cursor = conn.cursor() # Get cursor from the passed connection
for table_name in table_names:
query = f"SELECT sql FROM sqlite_master WHERE type="table" AND name="{table_name}";"
cursor.execute(query)
result = cursor.fetchone()
if result:
schemas.append(result(0))
return "nn".join(schemas)
# Example usage
sample_schemas = get_table_schemas(conn, ('users', 'pins'))
print(sample_schemas)Producción:
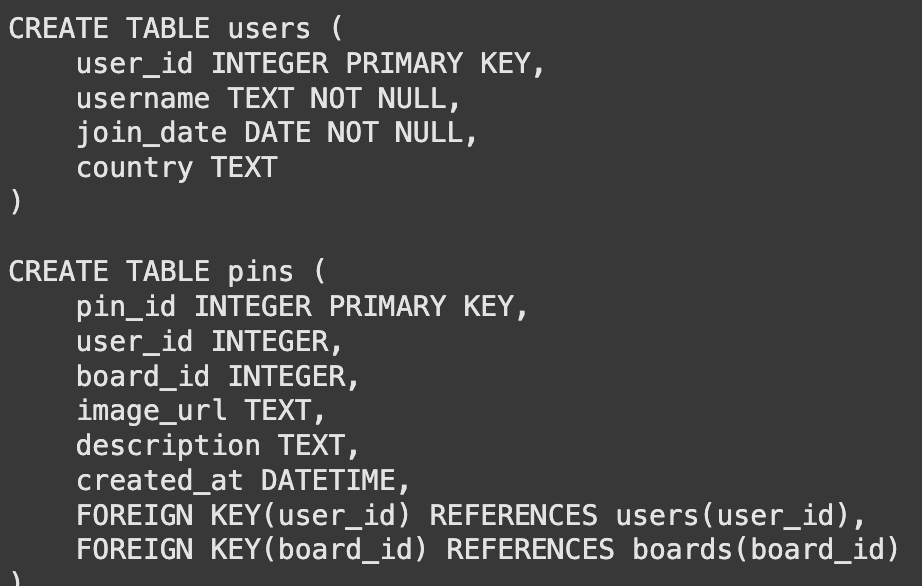
Con la función de esquema letanía, construimos nuestra primera dependencia. Una plantilla de inmediato instruye al maniquí en su tarea. Combina los esquemas y la pregunta del legatario. Luego conectamos este aviso al maniquí.
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
import sqlite3 # Import sqlite3
template = """
You are a master SQL expert. Based on the provided table schema and a user's question, write a syntactically correct SQLite SQL query.
Only return the SQL query and nothing else.
Here is the database schema:
{schema}
Here is the user's question:
{question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
sql_chain = prompt | llm | StrOutputParser()
Let's test our chain with a question where we explicitly provide the table names.
user_question = "How many pins has alice created?"
table_names_provided = ("users", "pins")
# Retrieve the schema in the main thread before invoking the chain
schema = get_table_schemas(conn, table_names_provided)
# Pass the schema directly to the chain
generated_sql = sql_chain.invoke({"schema": schema, "table_names": table_names_provided, "question": user_question})
print("User Question:", user_question)
print("Generated SQL:", generated_sql)
# Clean the generated SQL by removing markdown code block syntax
cleaned_sql = generated_sql.strip()
if cleaned_sql.startswith("```sql"):
cleaned_sql = cleaned_sql(len("```sql"):).strip()
if cleaned_sql.endswith("```"):
cleaned_sql = cleaned_sql(:-len("```")).strip()
print("Cleaned SQL:", cleaned_sql)
# Let's run the generated SQL to verify it works
try:
result_df = pd.read_sql_query(cleaned_sql, conn)
display(result_df)
except Exception as e:
print(f"Error executing SQL query: {e}")Producción:
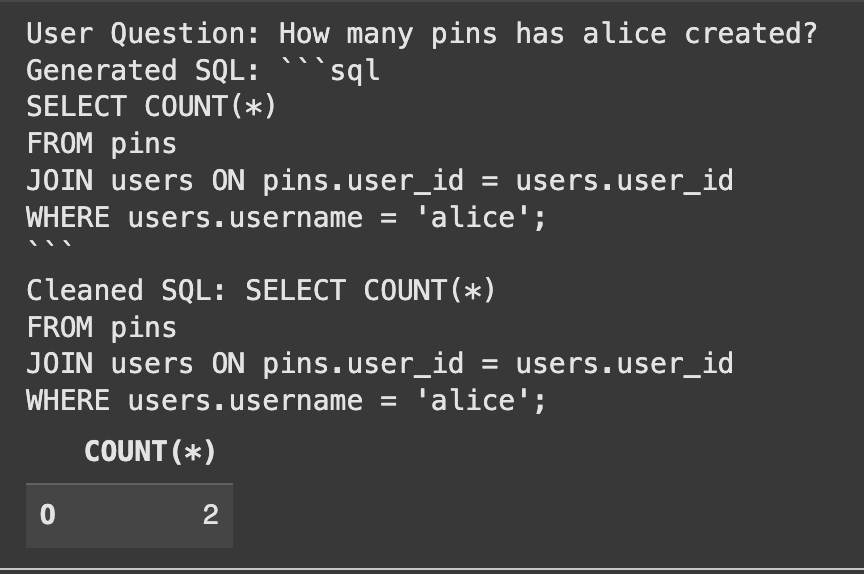
El sistema generó correctamente el SQL y encontró la respuesta correcta.
Paso 4: Mejoramiento con trapo para la selección de mesa
Nuestro sistema central funciona perfectamente, pero requiere que los usuarios conozcan los nombres de las mesa. Este es el problema exacto en el equipo de texto a SQL de Pinterest resuelto. Ahora implementaremos trapo para la selección de mesa. Comenzamos escribiendo resúmenes simples de lengua natural para cada mesa. Estos resúmenes capturan el significado del contenido de cada tabla.
table_summaries = {
"users": "Contains information about individual users, including their username, join date, and country of origin.",
"pins": "Contains data about individual pins, linking to the user who created them and the board they belong to. Includes descriptions and creation timestamps.",
"boards": "Stores information about user-created boards, including the board's name, category, and the user who owns it."
}A continuación, creamos una tienda vectorial. Esta utensilio convierte nuestros resúmenes en representaciones numéricas (incrustaciones). Nos permite encontrar los resúmenes de tabla más relevantes para la pregunta de un legatario a través de una búsqueda de similitud.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.schema import Document
# Create LangChain Document objects for each summary
summary_docs = (
Document(page_content=summary, metadata={"table_name": table_name})
for table_name, summary in table_summaries.items()
)
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(summary_docs, embeddings)
retriever = vector_store.as_retriever()
print("Vector store created successfully.")Paso 5: Combinar todo en una dependencia con trapo
Ahora construimos la dependencia final e inteligente. Esta dependencia automatiza todo el proceso. Se necesita una pregunta, usa el Retriever para encontrar tablas relevantes, obtiene sus esquemas y luego pasa todo a nuestro sql_chain.
def get_table_names_from_docs(docs):
"""Extracts table names from the metadata of retrieved documents."""
return (doc.metadata('table_name') for doc in docs)
# We need a way to get schema using table names and the connection within the chain
# Use the thread-safe function that recreates the database for each call
def get_schema_for_rag(x):
table_names = get_table_names_from_docs(x('table_docs'))
# Call the thread-safe function to get schemas
schema = get_table_schemas(conn, table_names)
return {"question": x('question'), "table_names": table_names, "schema": schema}
full_rag_chain = (
RunnablePassthrough.assign(
table_docs=lambda x: retriever.invoke(x('question'))
)
| RunnableLambda(get_schema_for_rag) # Use RunnableLambda to call the schema fetching function
| sql_chain # Pass the dictionary with question, table_names, and schema to sql_chain
)
Let's test the complete system. We ask a question without mentioning any tables. The system should handle everything.
user_question_no_tables = "Show me all the boards created by users from the USA."
# Pass the user question within a dictionary
final_sql = full_rag_chain.invoke({"question": user_question_no_tables})
print("User Question:", user_question_no_tables)
print("Generated SQL:", final_sql)
# Clean the generated SQL by removing markdown code block syntax, being more robust
cleaned_sql = final_sql.strip()
if cleaned_sql.startswith("```sql"):
cleaned_sql = cleaned_sql(len("```sql"):).strip()
if cleaned_sql.endswith("```"):
cleaned_sql = cleaned_sql(:-len("```")).strip()
# Also handle cases where there might be leading/trailing newlines after cleaning
cleaned_sql = cleaned_sql.strip()
print("Cleaned SQL:", cleaned_sql)
# Verify the generated SQL
try:
result_df = pd.read_sql_query(cleaned_sql, conn)
display(result_df)
except Exception as e:
print(f"Error executing SQL query: {e}")Producción:
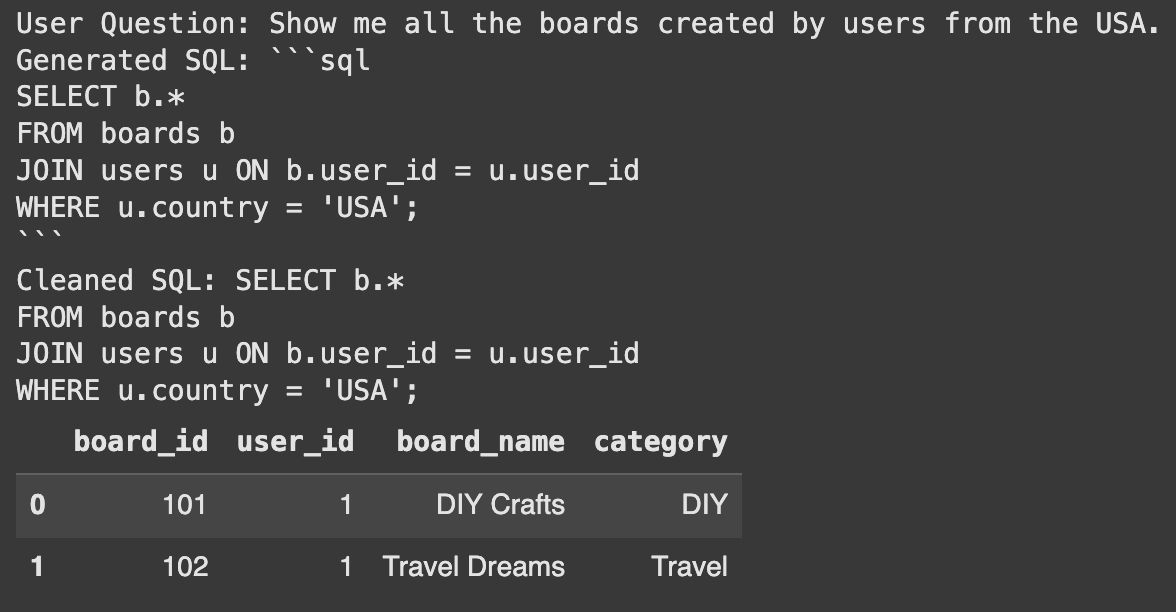
¡Éxito! El sistema identificó automáticamente a los usuarios y tablas de placa. Luego generó la consulta correcta para objetar la pregunta. Esto muestra el poder de usar trapo para la selección de mesa.
Conclusión
Hemos construido con éxito un prototipo que muestra cómo construir un turbina SQL. Mover esto a un entorno de producción requiere más pasos. Puede automatizar el proceso de sinopsis de la tabla. Asimismo puede incluir consultas históricas en la tienda Vector para mejorar la precisión. Esto sigue el camino tomado por el equipo de texto a SQL de Pinterest. Esta almohadilla proporciona una ruta clara para crear una utensilio de datos poderosa.
Preguntas frecuentes
A. El sistema de texto a SQL traduce preguntas escritas en lengua sencillo (como inglés) en consultas de bases de datos SQL. Esto permite a los usuarios no técnicos obtener datos sin escribir código.
A. RAG ayuda al sistema a encontrar automáticamente las tablas de almohadilla de datos más relevantes para la pregunta de un legatario. Esto elimina la privación de que los usuarios conozcan la estructura de la almohadilla de datos.
A. Langchain es un situación para desarrollar aplicaciones alimentadas por modelos de idiomas. Ayuda a conectar diferentes componentes como indicaciones, modelos y retriever en una sola dependencia.
Harsh Mishra es un ingeniero de IA/ML que pasa más tiempo hablando con modelos de idiomas grandes que los humanos reales. Apasionado por Genai, PNL, y hacer máquinas más inteligentes (por lo que todavía no lo reemplazan). Cuando no optimiza los modelos, probablemente esté optimizando su consumo de café. 🚀☕
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.