
¿Alguna vez te has sentido perdido en carpetas desordenadas, tantos scripts y códigos desorganizados? Ese caos sólo lo ralentiza y endurece el alucinación en dirección a la ciencia de datos. Los flujos de trabajo organizados y las estructuras de los proyectos no sólo son agradables de tener, porque afectan la reproducibilidad, la colaboración y la comprensión de lo que sucede en el esquema. En este blog, exploraremos las mejores prácticas y veremos un esquema de muestra para aconsejar sus próximos proyectos. Sin más preámbulos, analicemos algunos de los marcos importantes, las prácticas comunes y cómo mejorarlos.
Marcos de flujo de trabajo de ciencia de datos populares para la estructura de proyectos
Marcos de ciencia de datos Proporciona una forma estructurada de puntualizar y proseguir una estructura clara de proyectos de ciencia de datos, guiando a los equipos desde la definición del problema hasta la implementación, al tiempo que mejoría la reproducibilidad y la colaboración.
CRISP-DM
CRISP-DM es el siglas de Proceso intersectorial para minería de datos. Sigue una estructura iterativa cíclica que incluye:
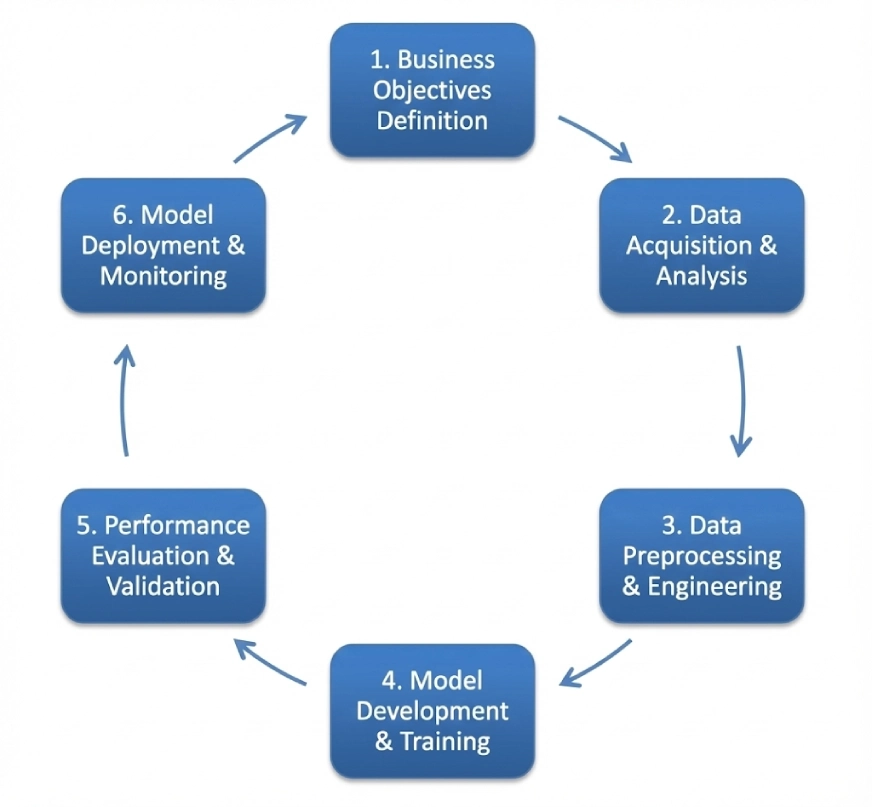
- Comprensión empresarial
- Comprensión de datos
- Preparación de datos
- Modelado
- Evaluación
- Despliegue
Este entorno se puede utilizar como estereotipado en múltiples dominios, aunque el orden de los pasos puede ser flexible y puede retroceder o contrario al flujo unidireccional. Veremos un esquema que utiliza este entorno más delante en este blog.
SOmiMinnesota
Otro entorno popular en el mundo de la ciencia de datos. La idea aquí es dividir los problemas complejos en 5 pasos y resolverlos paso a paso, los 5 pasos de OSEMN (pronunciado Awesome) son:
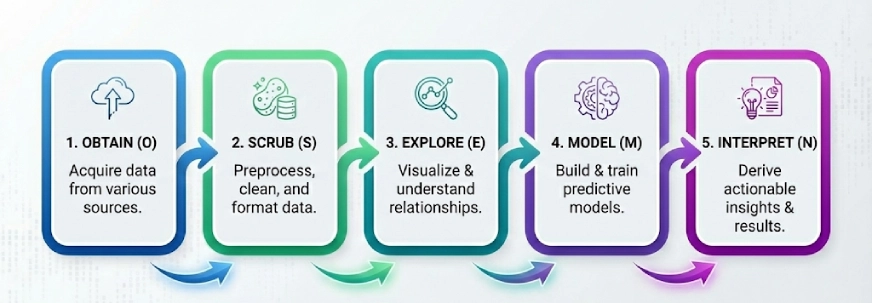
- Obtener
- Fregar
- Explorar
- Maniquí
- Interpretar
Nota: La ‘N’ en “OSEMN” es la N en iNterpret.
Seguimos estos 5 pasos lógicos para «obtener» los datos, «depurar» o preprocesar los datos, luego «explorar» los datos mediante visualizaciones y comprender las relaciones entre los datos, y luego «modelar» los datos para usar las entradas para predecir las futuro. Finalmente, «interpretamos» los resultados y encontramos información útil.
KDD
KDD o Knowledge Discovery in Databases consta de múltiples procesos que tienen como objetivo convertir datos sin procesar en descubrimiento de conocimiento. Estos son los pasos en este entorno:

- Selección
- Preprocesamiento
- Transformación
- Minería de datos
- Interpretación/Evaluación
Vale la pena mencionar que la concurrencia se refiere a KDD como minería de datos, pero la minería de datos es el paso específico donde se utilizan algoritmos para encontrar patrones. Mientras que KDD cubre todo el ciclo de vida desde el principio hasta el final.
SEMMA
Este entorno hace más hincapié en el explicación del maniquí. El SEMMA surge de los pasos lógicos del entorno que son:
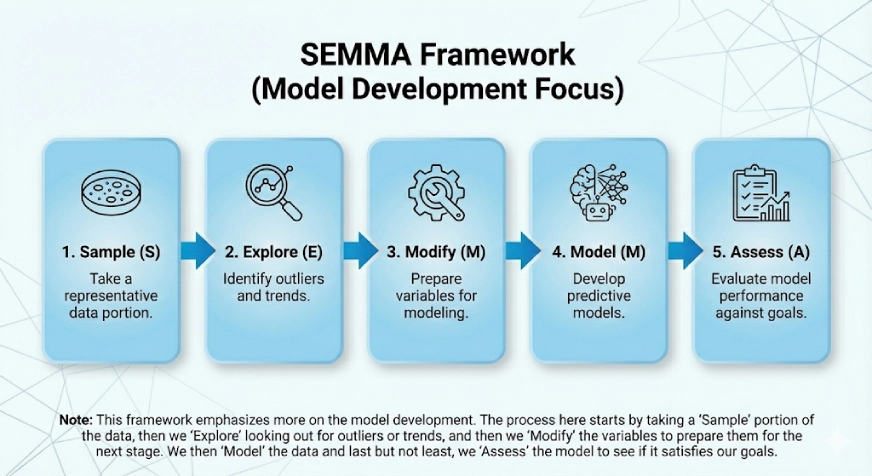
- Muestra
- Explorar
- Modificar
- Maniquí
- Evaluar
El proceso aquí comienza tomando una porción de «Muestra» de los datos, luego «Exploramos» buscando títulos atípicos o tendencias, y luego «Modificamos» las variables para prepararlas para la próximo etapa. Luego «modelamos» los datos y, por extremo, pero no menos importante, «evaluamos» el maniquí para ver si satisface nuestros objetivos.
Prácticas comunes que deben mejorarse
Mejorar estas prácticas es fundamental para proseguir un sistema despejado y escalable. ciencia de datos estructura del esquema, especialmente a medida que los proyectos crecen en tamaño y complejidad.
1. El problema de los “Caminos”
La concurrencia suele codificar rutas absolutas como pd.read_csv(“C:/Users/Name/Downloads/data.csv”). Esto está aceptablemente al probar cosas en Jupyter Notebook, pero cuando se usa en el esquema auténtico, rompe el código para todos los demás.
La alternativa: Utilice siempre rutas relativas con la ayuda de bibliotecas como “os” o “pathlib”. Alternativamente, puede optar por juntar las rutas en un archivo de configuración (por ejemplo: DATA_DIR=/home/ubuntu/path).
2. El enmarañado cuaderno de Jupyter
A veces, las personas usan un único Jupyter Notebook con más de 100 celdas que contienen importaciones, EDA, aseo, modelado y visualización. Esto haría irrealizable realizar pruebas o controlar la traducción.
La alternativa: Utilice Jupyter Notebooks solo para la exploración y siga los scripts de Python para la automatización. Una vez que funcione la función de aseo, agréguela a un archivo src/processing.py y luego podrá importarla al cuaderno. Esto añade modularidad y reutilización y igualmente simplifica mucho las pruebas y la comprensión del portátil.
3. Versione el código, no los datos
Git puede tener dificultades para manejar archivos CSV grandes. La concurrencia suele mandar datos a GitHub, lo que puede sobrellevar mucho tiempo y igualmente causar otras complicaciones.
La alternativa: Mencione y utilice el Control de versiones de datos (DVC para abreviar). Es como Git pero para datos.
4. No proporcionar un archivo README para el esquema.
Un repositorio puede contener código excelente, pero sin instrucciones sobre cómo instalar dependencias o ejecutar scripts puede resultar caótico.
La alternativa: Asegúrese de crear siempre un buen archivo README.md que contenga información sobre cómo configurar el entorno, dónde y cómo obtener los datos, cómo ejecutar el maniquí y otros scripts importantes.
Creación de un sistema de predicción de renuncia de clientes (esquema de muestra)
Ahora, utilizando el entorno CRISP-DM, he creado un esquema de muestra llamado «Sistema de predicción de renuncia de clientes”, comprendamos todo el proceso y los pasos al observarlos mejor.
Aquí está el enlace de GitHub del representante.ositorio.
Nota: Este es un esquema de muestra y está diseñado para comprender cómo implementar el entorno y seguir un procedimiento estereotipado.
Aplicar CRISP-DM paso a paso
- Comprensión empresarial: Aquí tenemos que puntualizar lo que efectivamente estamos tratando de resolver. En nuestro caso, se negociación de detectar clientes que probablemente abandonen su negocio. Establecimos objetivos claros para el sistema, más del 85 % de precisión y más del 80 % de recuperación, y el objetivo comercial aquí es retener a los clientes.
- Comprensión de datos En nuestro caso, el conjunto de datos Telco Customer Churn. Tenemos que analizar las estadísticas descriptivas, corroborar la calidad de los datos, apañarse títulos faltantes (igualmente pensar en cómo podemos manejarlos), igualmente tenemos que ver cómo se distribuye la variable objetivo y, por extremo, debemos explorar las correlaciones entre las variables para ver qué características importan.
- Preparación de datos: Este paso puede sobrellevar tiempo pero debe realizarse con cuidado. Aquí limpiamos los datos desordenados, nos ocupamos de los títulos faltantes y los títulos atípicos, creamos nuevas características si es necesario, codificamos las variables categóricas, dividimos el conjunto de datos en entrenamiento (70%), empuje (15%) y prueba (15%), y finalmente normalizamos las características de nuestros modelos.
- Modelado: En este paso crucial, comenzamos con un maniquí o dirección de almohadilla simple (regresión provisión en nuestro caso), luego experimentamos con otros modelos como Random Forest, XGBoost para alcanzar nuestros objetivos comerciales. Luego ajustamos los hiperparámetros.
- Evaluación: Aquí descubrimos qué maniquí funciona mejor para nosotros y cumple con nuestros objetivos comerciales. En nuestro caso, debemos observar la precisión, la recuperación, las puntuaciones F1, las curvas ROC-AUC y la matriz de confusión. Este paso nos ayuda a designar el maniquí final para nuestro objetivo.
- Despliegue: Aquí es donde efectivamente comenzamos a utilizar el maniquí. Aquí podemos usar FastAPI o cualquier otra alternativa, contenerlo con Docker para escalabilidad y configurar el monitoreo con fines de seguimiento.
Claramente, el uso de un proceso paso a paso ayuda a proporcionar un camino claro en dirección a el esquema; adicionalmente, durante el explicación del esquema puede utilizar rastreadores de progreso y los controles de traducción de GitHub seguramente pueden ayudar. La preparación de datos necesita un cuidado minucioso, ya que no necesitará muchas revisiones si se hace correctamente; si surge algún problema a posteriori de la implementación, se puede solucionar volviendo a la etapa de modelado.
Conclusión
Como se mencionó al aparición del blog, los flujos de trabajo organizados y las estructuras de proyectos no sólo son agradables, sino que son imprescindibles. Con CRISP-DM, OSEMN, KDD o SEMMA, un proceso paso a paso mantiene los proyectos claros y reproducibles. Por otra parte, no olvide utilizar rutas relativas, conservar Jupyter Notebooks para la exploración y crear siempre un buen archivo README.md. Recuerde siempre que el explicación es un proceso iterativo y tener un entorno estructurado claro para sus proyectos facilitará su alucinación.
Preguntas frecuentes
R. La reproducibilidad en la ciencia de datos significa poder obtener los mismos resultados utilizando el mismo conjunto de datos, código y ajustes de configuración. Un esquema reproducible garantiza que los experimentos se puedan corroborar, depurar y mejorar con el tiempo. Todavía facilita la colaboración, ya que otros miembros del equipo pueden ejecutar el esquema sin inconsistencias causadas por diferencias de entorno o datos.
R. La deriva del maniquí ocurre cuando el rendimiento de un maniquí de enseñanza mecánico se degrada porque los datos del mundo auténtico cambian con el tiempo. Esto puede suceder correcto a cambios en el comportamiento de los usuarios, las condiciones del mercado o la distribución de datos. El monitoreo de la desviación del maniquí es esencial en los sistemas de producción para respaldar que los modelos sigan siendo precisos, confiables y alineados con los objetivos comerciales.
R. Un entorno imaginario aísla las dependencias del esquema y evita conflictos entre diferentes versiones de la biblioteca. Cubo que los proyectos de ciencia de datos a menudo dependen de versiones específicas de paquetes de Python, el uso de entornos virtuales garantiza resultados consistentes en todas las máquinas y a lo abundante del tiempo. Esto es fundamental para la reproducibilidad, la implementación y la colaboración en flujos de trabajo de ciencia de datos del mundo auténtico.
R. Una canalización de datos es una serie de pasos automatizados que mueven datos desde fuentes sin procesar a un formato perspicaz para maniquí. Por lo militar, incluye la ingesta, aseo, transformación y almacenamiento de datos.
Apasionado por la tecnología y la innovación, egresado del Instituto Tecnológico Vellore. Actualmente trabajando como Data Science Trainee, enfocándome en Data Science. Profundamente interesado en el enseñanza profundo y la IA generativa, ansioso por explorar técnicas de vanguardia para resolver problemas complejos y crear soluciones impactantes.
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.