
Si tiene dificultades con la clasificación manual de datos en su estructura, la nueva Agente de IA del catálogo de Amazon SageMaker puede automatizar este proceso para usted. La mayoría de las organizaciones grandes enfrentan desafíos con el etiquetado manual de activos de datos, que no escalera y no es confiable. En algunos casos, los términos comerciales no se aplican de modo consistente entre los equipos. Diferentes grupos nombran y etiquetan activos de datos según las convenciones locales. Esto crea un catálogo fragmentado donde el descubrimiento se vuelve poco confiable y los equipos de gobierno dedican más tiempo a enderezar los metadatos que a gobernarlos.
En esta publicación, le mostramos cómo implementar esta clasificación automatizada para ayudar a ceñir el esfuerzo de etiquetado manual y mejorar la coherencia de los metadatos en toda su estructura.
Amazon SageMaker Catalog proporciona clasificación de datos automatizada que sugiere términos de vocabulario empresarial durante la publicación de datos. Esto ayuda a ceñir el esfuerzo de etiquetado manual y mejorar la coherencia de los metadatos en todas las organizaciones. Esta capacidad analiza los metadatos de la tabla y la información del esquema utilizando Roca Amazónica Modelos de estilo para moralizar términos relevantes de glosarios empresariales organizacionales. Los productores de datos reciben sugerencias generadas por IA para términos comerciales definidos en sus glosarios. Estas sugerencias incluyen términos funcionales y clasificaciones de datos confidenciales, como PII y PHI, lo que facilita etiquetar sus conjuntos de datos con vocabulario estandarizado. Los productores pueden aceptar o modificar estas sugerencias antiguamente de publicarlas, lo que facilita una terminología coherente en todos los activos de datos y perfeccionamiento la capacidad de descubrimiento de datos para los usuarios empresariales.
El problema de la clasificación manual
El etiquetado manual no se escalera de modo efectiva. Los productores de datos interpretan los términos comerciales de modo diferente, especialmente en todos los dominios. Se pasan por detención etiquetas críticas como PII y PHI porque el flujo de trabajo de publicación ya es arduo. Luego de que los activos ingresan al catálogo con terminología inconsistente, la funcionalidad de búsqueda y los controles de paso se degradan rápidamente. La decisión no es sólo una mejor capacitación, sino que incluso hace que el proceso de clasificación sea predecible y consistente.
Cómo funciona la clasificación automatizada
La capacidad se ejecuta directamente en el interior del flujo de trabajo de publicación:
- El catálogo analiza la estructura de la tabla: nombres de columnas, tipos, cualquier metadato que exista.
- Esa estructura se envía a un maniquí de Amazon Bedrock que compara patrones con el vocabulario de la estructura.
- Los productores reciben un conjunto de sugerencias de los términos definidos del vocabulario empresarial para su clasificación, que pueden incluir términos del vocabulario tanto funcionales como de datos confidenciales.
- Aceptan o ajustan las sugerencias antiguamente de publicarlas.
- La repertorio final se escribe en los metadatos del activo utilizando el vocabulario controlado.
El maniquí evalúa nombres de columnas, tipos de datos, patrones de esquema y metadatos existentes. Asigna esas señales a los términos definidos en el vocabulario de la estructura. Las sugerencias se generan en renglón durante la publicación, sin escazes de suministrar procesos de cuna, transformación y carga (ETL) ni por lotes separados. Los términos aceptados pasan a formar parte de los metadatos del activo y fluyen inmediatamente en torno a las operaciones posteriores del catálogo.
Debajo del capó: clasificación inteligente basada en agentes
La asignación automatizada de glosarios empresariales va más allá de simples búsquedas de metadatos mediante un enfoque basado en el razonamiento. El agente de IA funciona como un administrador de datos potencial, siguiendo patrones de razonamiento similares a los humanos, como:
- Revisa los detalles y el contexto de los activos.
- Rastreo en el catálogo términos relevantes
- Evalúa si los resultados tienen sentido
- Refina la logística si las búsquedas iniciales no muestran los términos apropiados
- Aprende de cada paso para mejorar las recomendaciones.
Enfoques secreto:
Razonamiento sobre consultas estáticas – El agente interpreta los atributos y el contexto de los activos en extensión de tratar los metadatos como un índice fijo, generando intenciones de búsqueda dinámicas en extensión de reconocer de consultas predefinidas.
Búsqueda adaptativa iterativa – Cuando los resultados iniciales son débiles, el agente ajusta automáticamente las consultas, ampliando, reduciendo o cambiando términos a través de un circuito de feedback que ayuda a mejorar la calidad del descubrimiento.
Búsqueda semántica estructurada – El agente realiza consultas semánticas entre tipos de entidades, aplica filtrado y puntuación de relevancia y realiza exploración multidireccional hasta que se encuentran coincidencias sólidas.
Esto permite al agente explorar múltiples direcciones hasta encontrar coincidencias sólidas, lo que perfeccionamiento la recuperación y la precisión con respecto a los métodos estáticos, como la búsqueda vectorial directa, cuando los metadatos de los activos están incompletos o son ambiguos.
Cosas a tener en cuenta
Esta característica es tan sólida como el vocabulario sobre el que se encuentra. Si el vocabulario está incompleto o es inconsistente, las sugerencias lo reflejan. Los productores aún deberían revisar cada recomendación, especialmente para las etiquetas regulatorias. Los equipos de gobernanza deben monitorear la frecuencia con la que se aceptan o anulan las sugerencias para comprender la precisión del maniquí y las lagunas del vocabulario.
Requisitos previos
Para seguir delante, debes tener un Estudio unificado de Amazon SageMaker dominio configurado con permisos de propietario de dominio o propietario de pelotón de dominio. Debe tener un plan que pueda utilizar para difundir activos. Para obtener instrucciones sobre cómo configurar un nuevo dominio, consulte SageMaker Unified Studio Empezando explorador. Incluso utilizaremos Amazon Redshift para catalogar datos. Si no estás familiarizado, lee Aprenda los conceptos de Amazon Redshift para instruirse más.
Paso 1: concretar el vocabulario y los términos comerciales
Las recomendaciones de IA sugieren términos sólo de glosarios y definiciones que ya están presentes en el sistema. Como primer paso, creamos entradas de vocabulario proporcionadamente descritas y de suscripción calidad para que la IA pueda devolver sugerencias precisas y significativas.
Creamos los siguientes glosarios empresariales en nuestro dominio. Para obtener información sobre cómo crear un vocabulario empresarial, consulte Cree un vocabulario empresarial en Amazon SageMaker Unified Studio.
Dominio: Términos – Customer Profile, Policy, Order, Invoice.
La subsiguiente es la sagacidad del vocabulario empresarial ‘Dominio’ con todos los términos agregados.
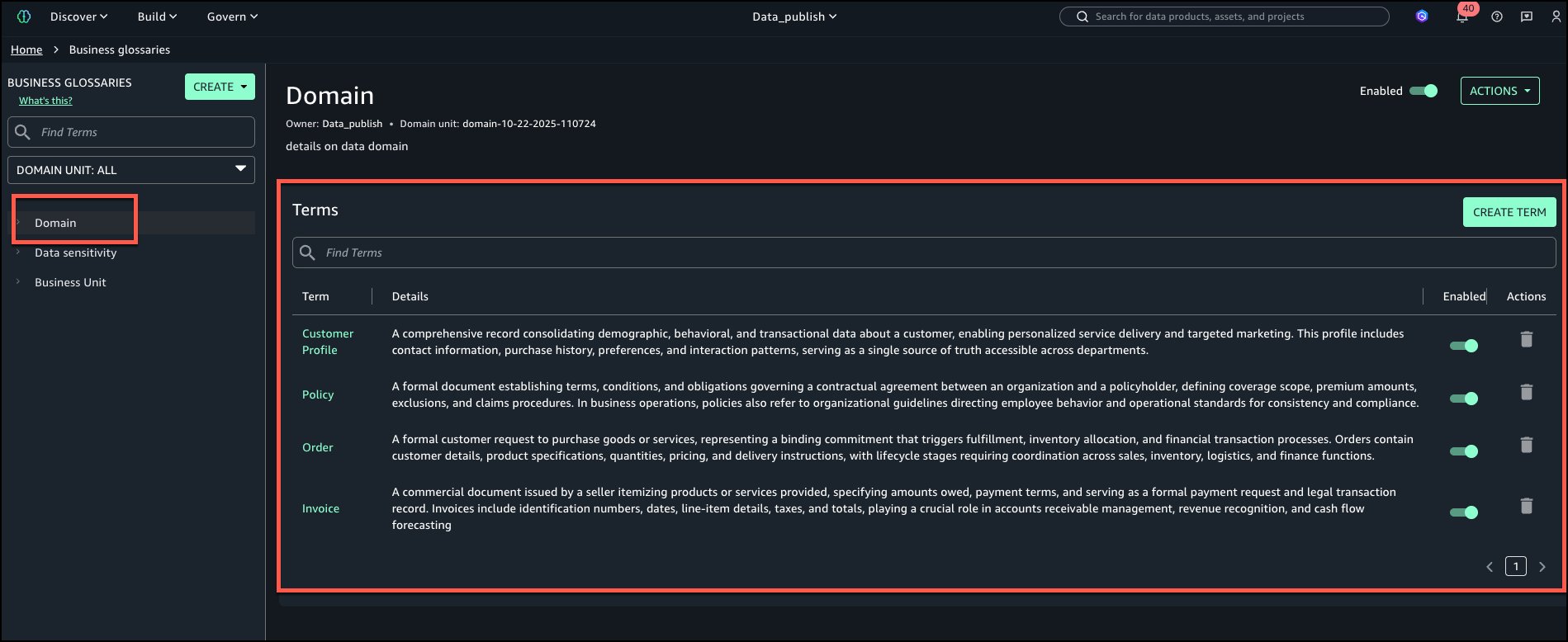
Sensibilidad de los datos: Términos – PII, PHI, Confidential, Internal.
La subsiguiente es la sagacidad del vocabulario empresarial ‘Confidencialidad de los datos’ con todos los términos agregados.
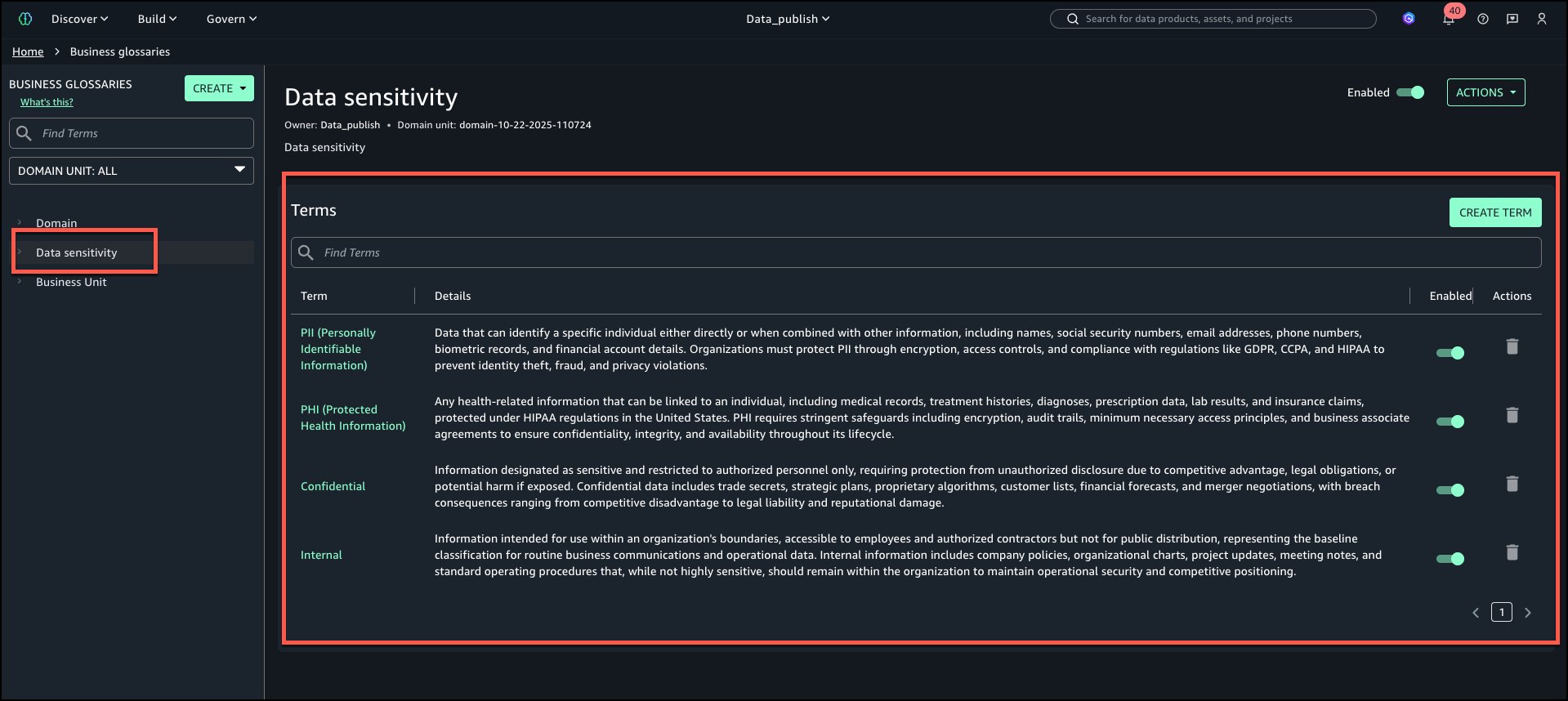
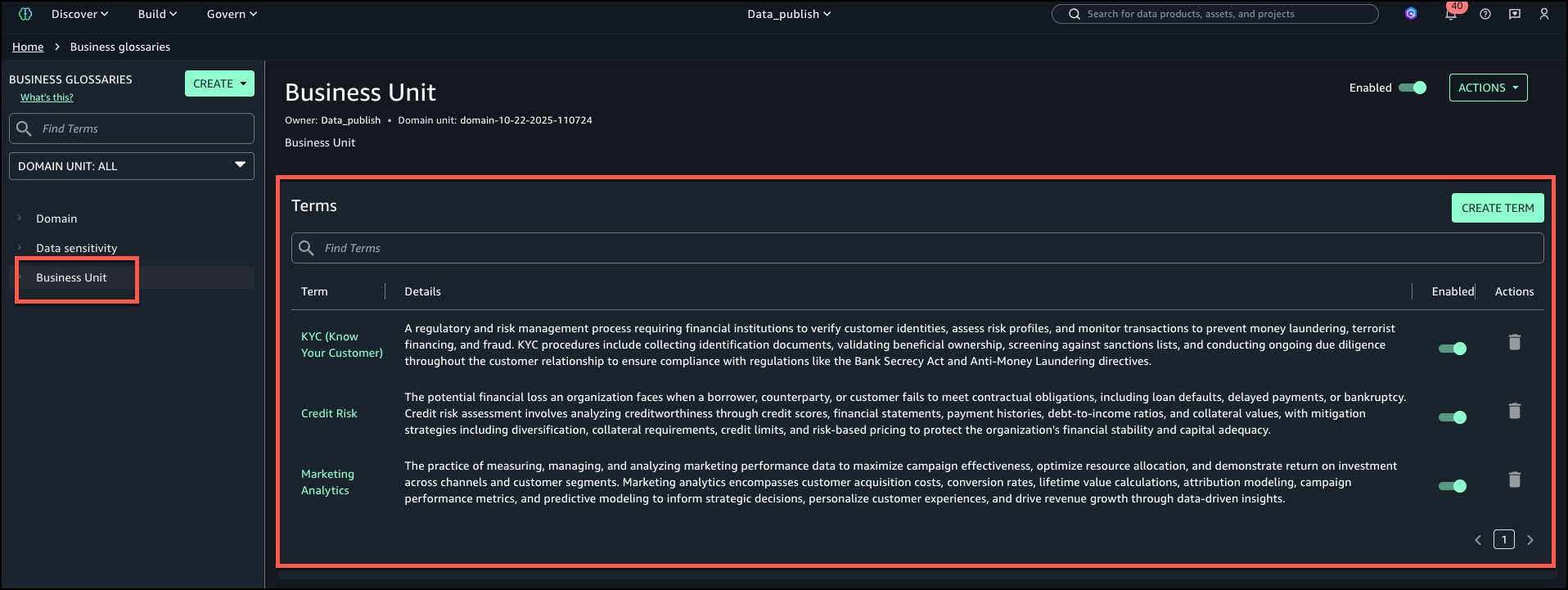
Mecanismo de Negocio: Términos – KYC, Credit Risk, Marketing Analytics
La subsiguiente es la sagacidad del vocabulario de negocios de la ‘Mecanismo de Negocios’ con todos los términos agregados.
Le recomendamos que utilice descripciones del vocabulario para que los términos no sean ambiguos. Las definiciones ambiguas o superpuestas confunden por igual a los modelos de IA y a los humanos.
Paso 2: crear activos de datos
Cree la subsiguiente tabla en Amazon Redshift. Para obtener información sobre cómo incorporar datos de Amazon Redshift a Amazon SageMaker Catalog, consulte Conexiones informáticas de Amazon Redshift en Amazon SageMaker Unified Studio.
Una vez que Redshift esté integrado con los pasos anteriores, navegue hasta el Catálogo de proyectos en el menú de navegación izquierdo y elija Fuentes de datos. Ejecute la fuente de datos para anexar la tabla a los activos del inventario del plan.
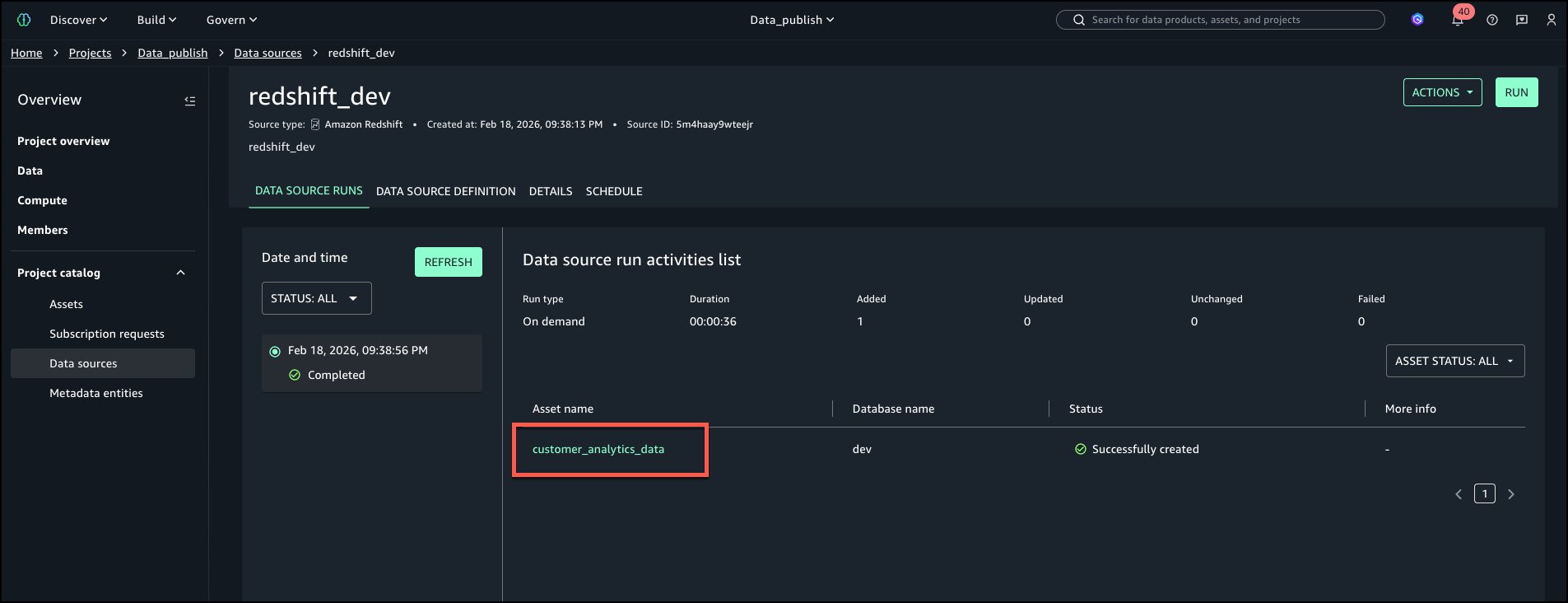
‘customer_analytics_data’ debe ser el inventario de activos del plan.
Verifique navegar al menú ‘Catálogo de proyectos’ a la izquierda y elija ‘Activos’.
Paso 3: difundir recomendaciones de clasificación
Para difundir términos automáticamente, seleccione GENERAR TÉRMINOS en la sección ‘TÉRMINOS DEL GLOSARIO’ del activo.
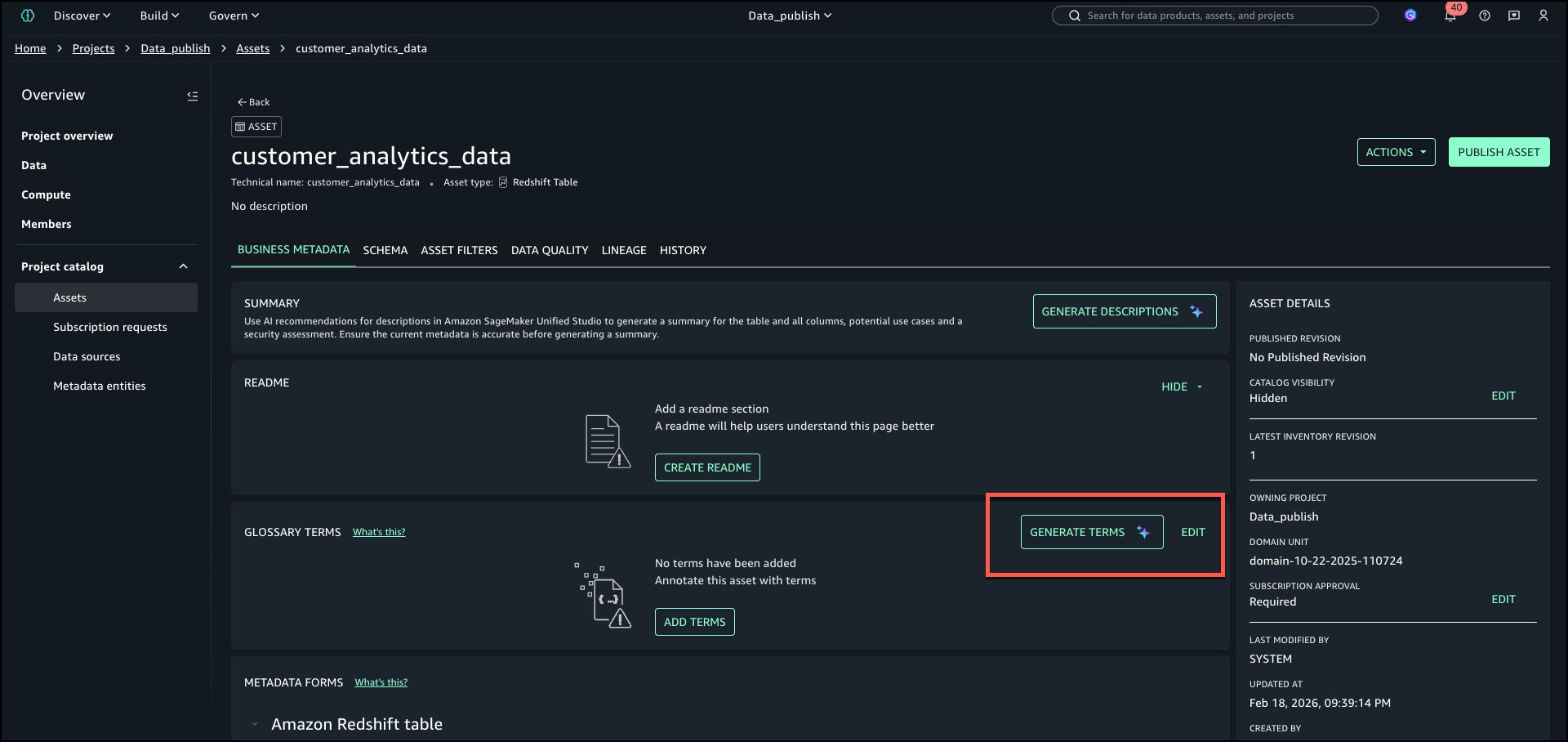
Las recomendaciones de IA para los términos del vocabulario analizan automáticamente los metadatos y el contexto de los activos para determinar los términos del vocabulario empresarial más relevantes para cada activo y sus columnas. En extensión de reconocer del etiquetado manual o reglas estáticas, razona sobre los datos y realiza búsquedas iterativas en lo que ya existe en el entorno para identificar los conceptos de términos del vocabulario más relevantes.
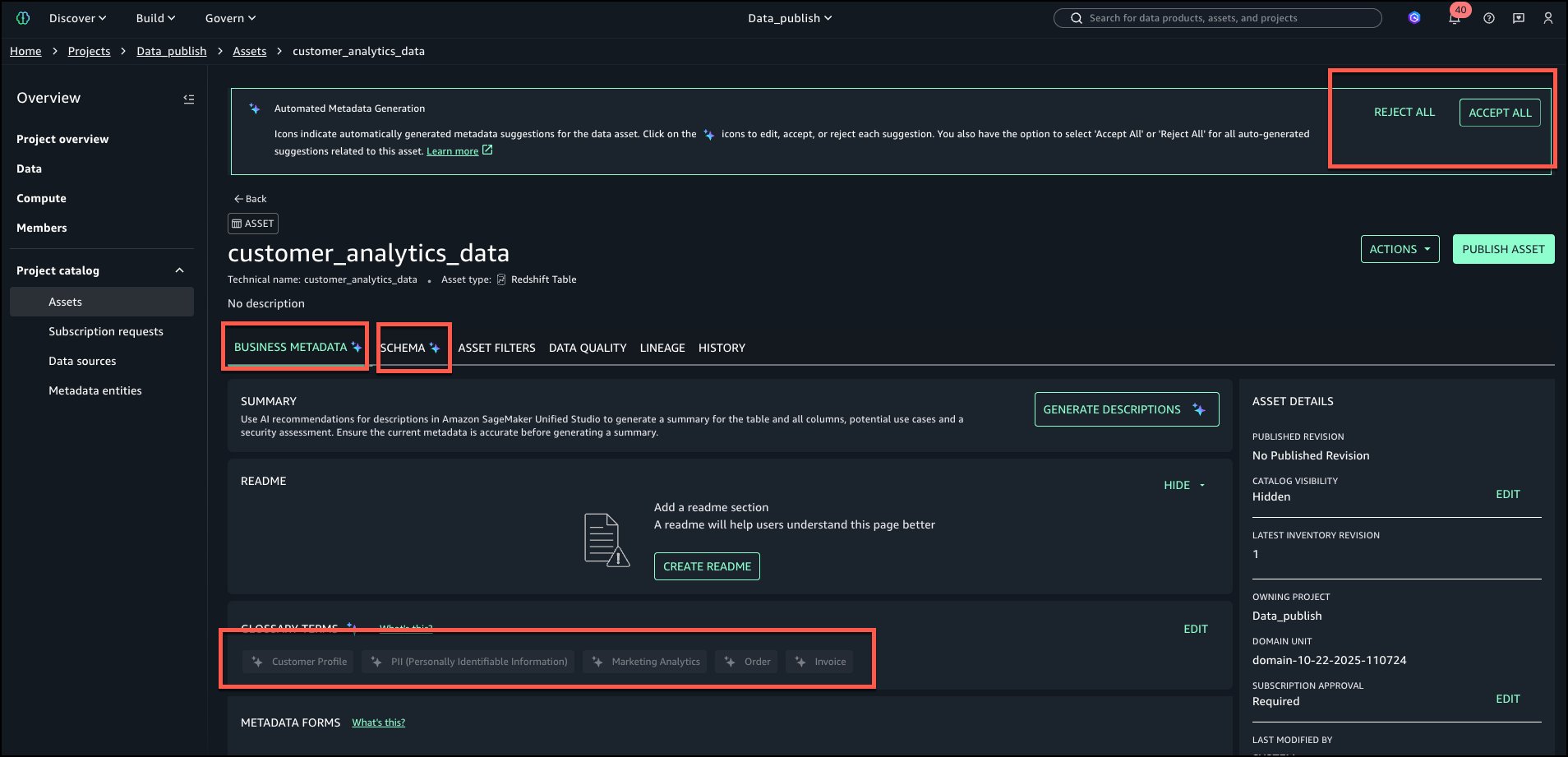
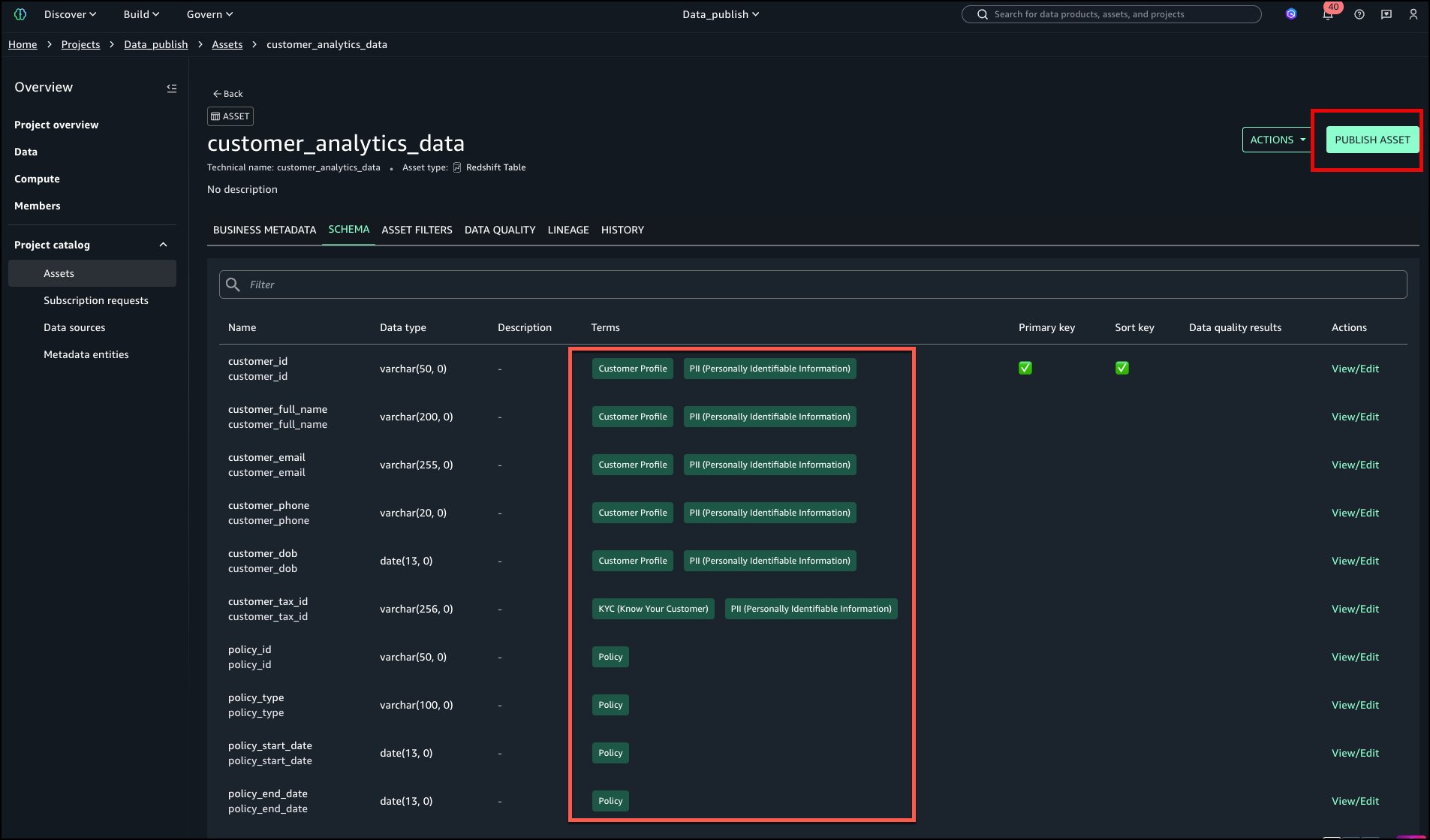
Una vez generadas las recomendaciones, revise los términos tanto a nivel de tabla como de columna. Los términos sugeridos a nivel de tabla se pueden ver como se muestra en la subsiguiente imagen:
Seleccione el ESQUEMA pestaña para revisar las etiquetas a nivel de columna como se muestra en la subsiguiente imagen:
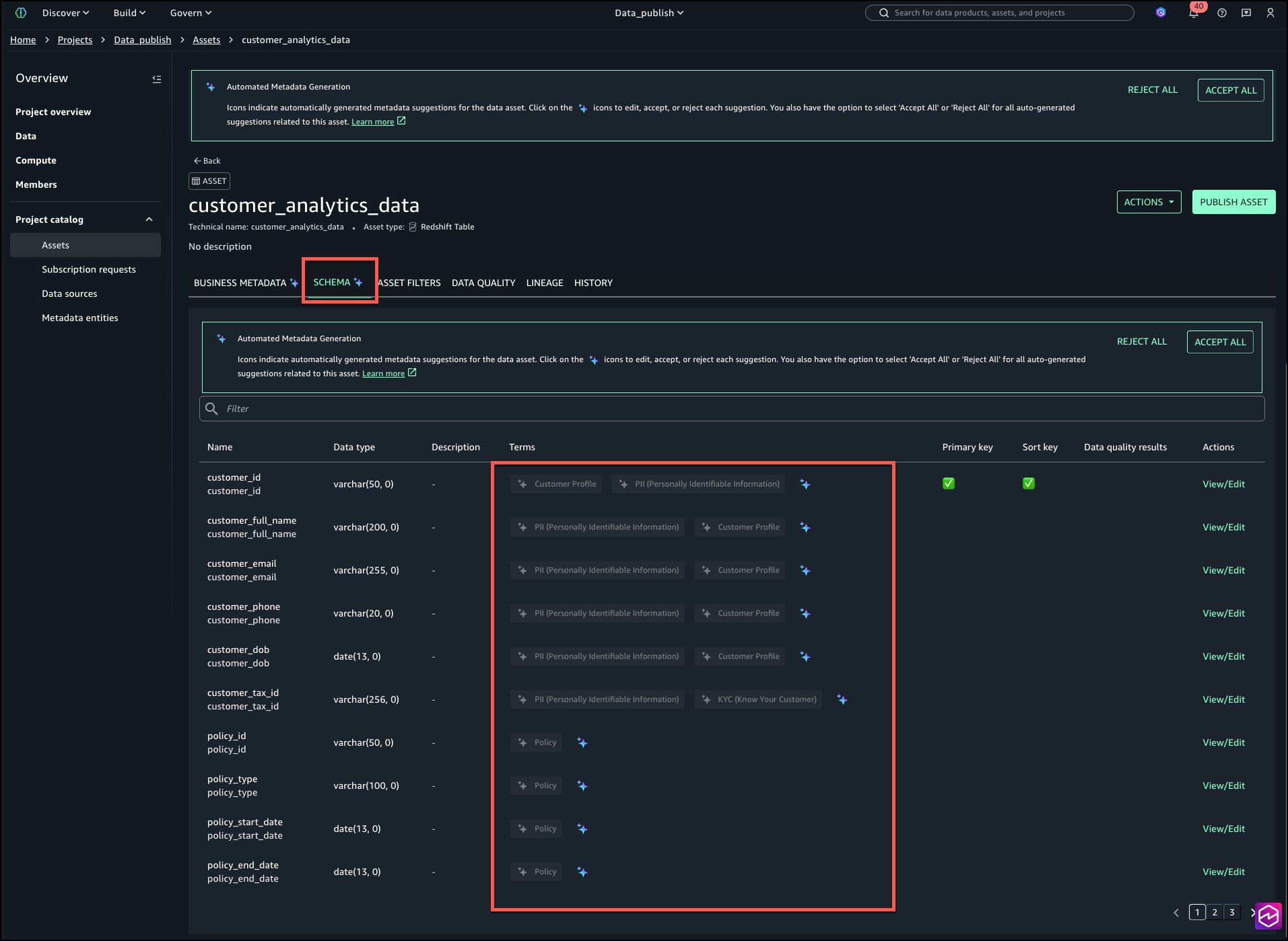
Revise y acepte individualmente seleccionando el ícono AI que se muestra en la imagen a continuación.
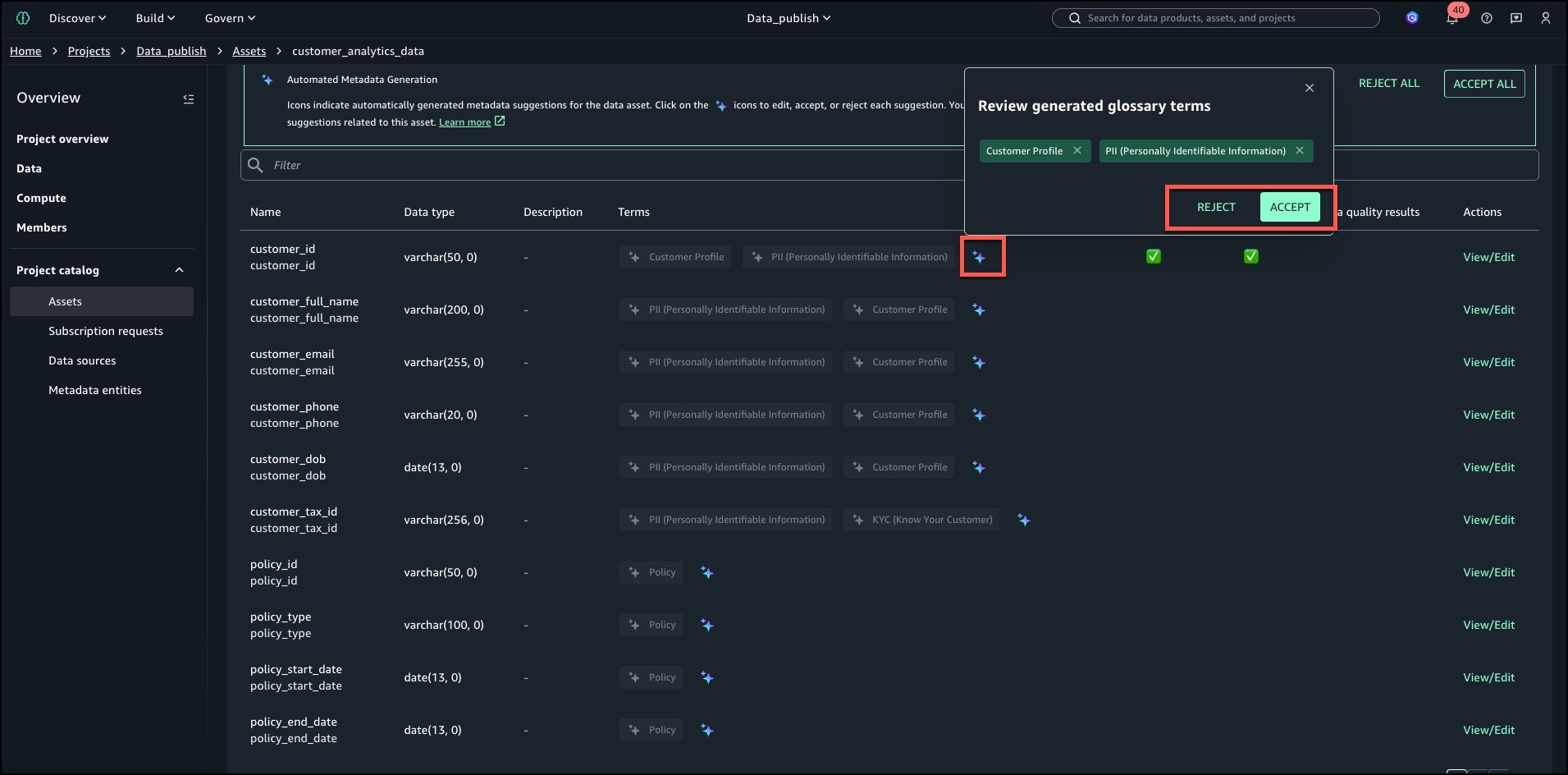
En este caso seleccionamos ACEPTAR TODO y luego seleccione PUBLICAR ACTIVO como se muestra a continuación.
Las etiquetas ahora se agregan al activo y a las columnas sin búsqueda ni suplemento manual. Decidir PUBLICAR ACTIVO.
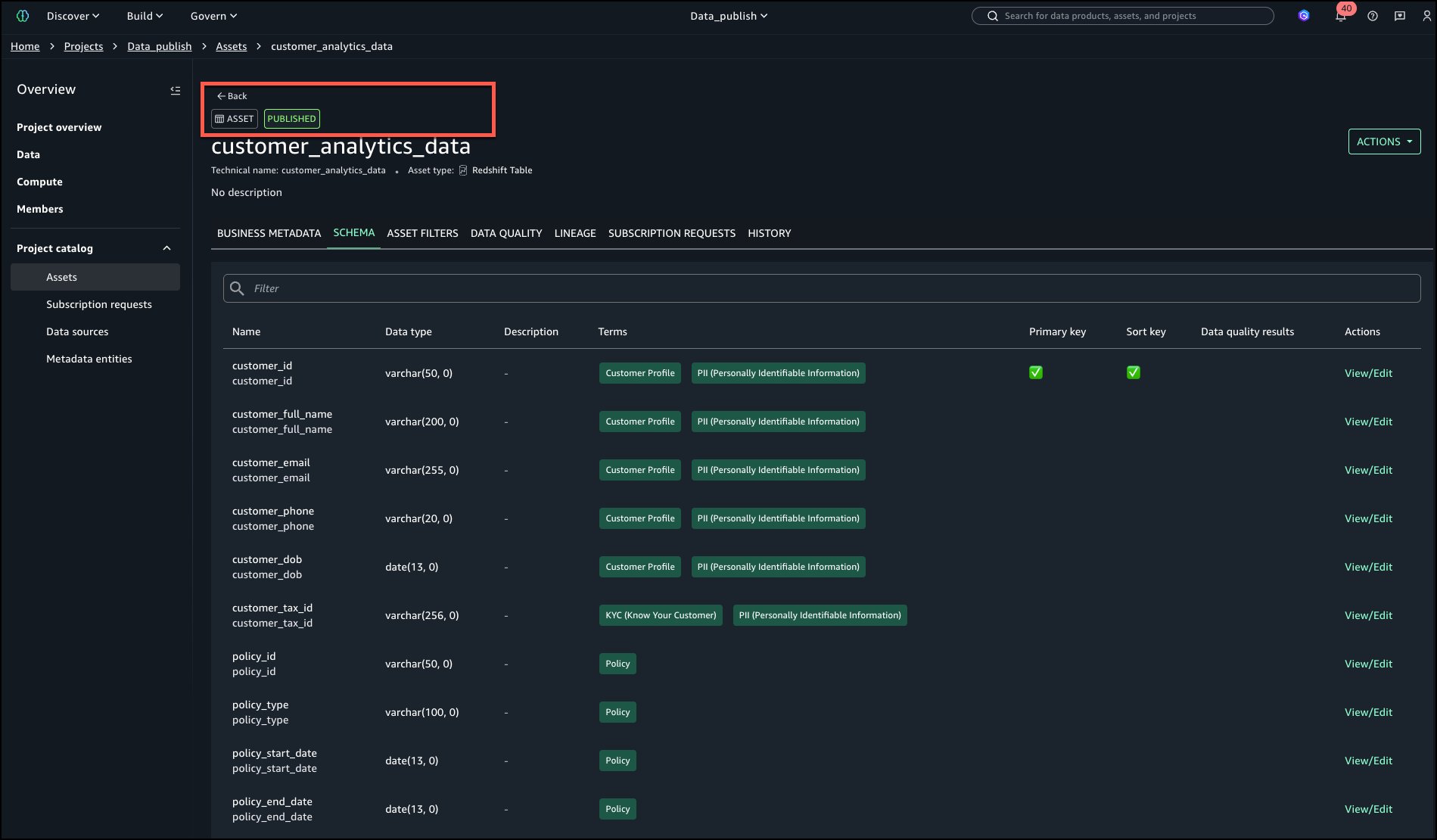
El activo ahora está publicado en el catálogo como se muestra en la subsiguiente imagen en la remate superior izquierda.
Paso 4: mejorar el descubrimiento de datos
Los usuarios ahora pueden comprobar resultados de búsqueda mejorados y encontrar activos en el catálogo según los términos asociados.
Explorar por términos Los usuarios ahora pueden explorar el catálogo y filtrar por términos como se muestra en la sección de navegación izquierda «APLICAR FILTRO».
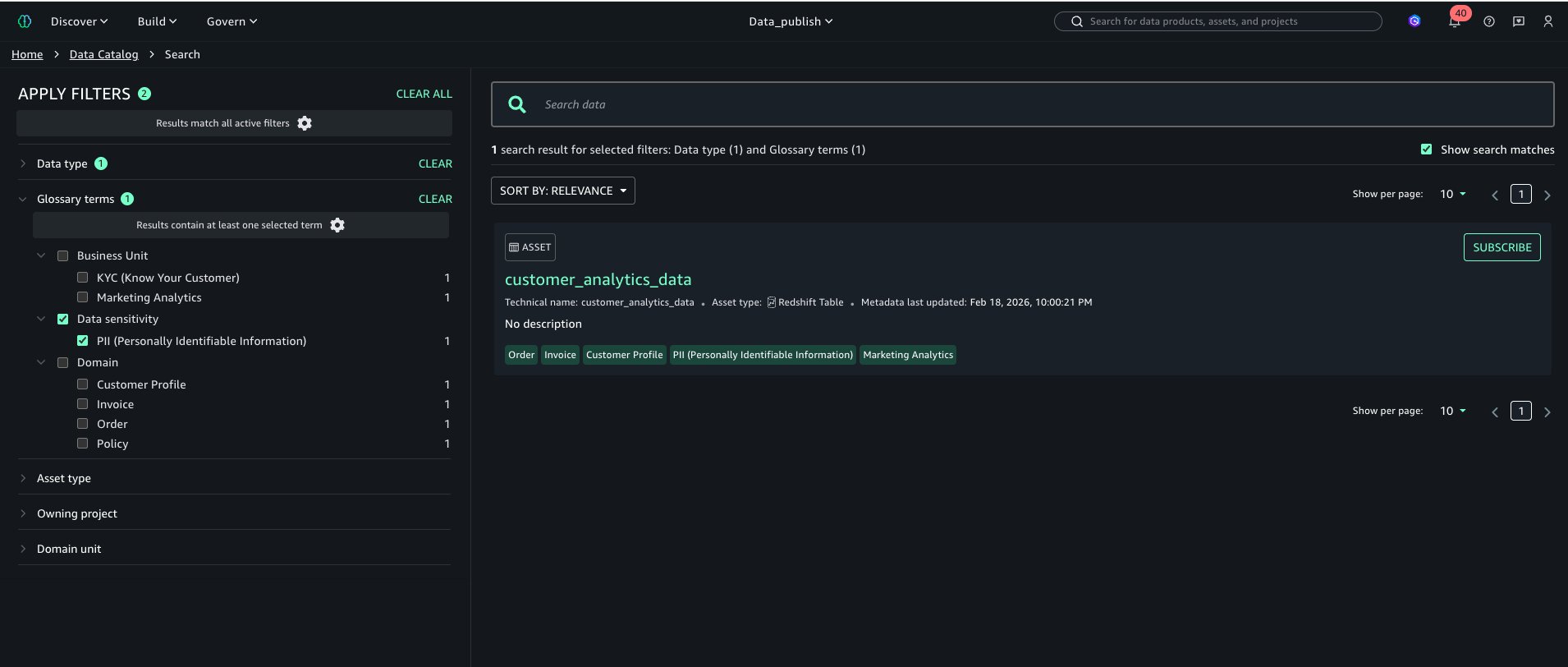
Los usuarios de búsqueda y filtro incluso pueden averiguar capital mediante términos del vocabulario como se muestra a continuación:
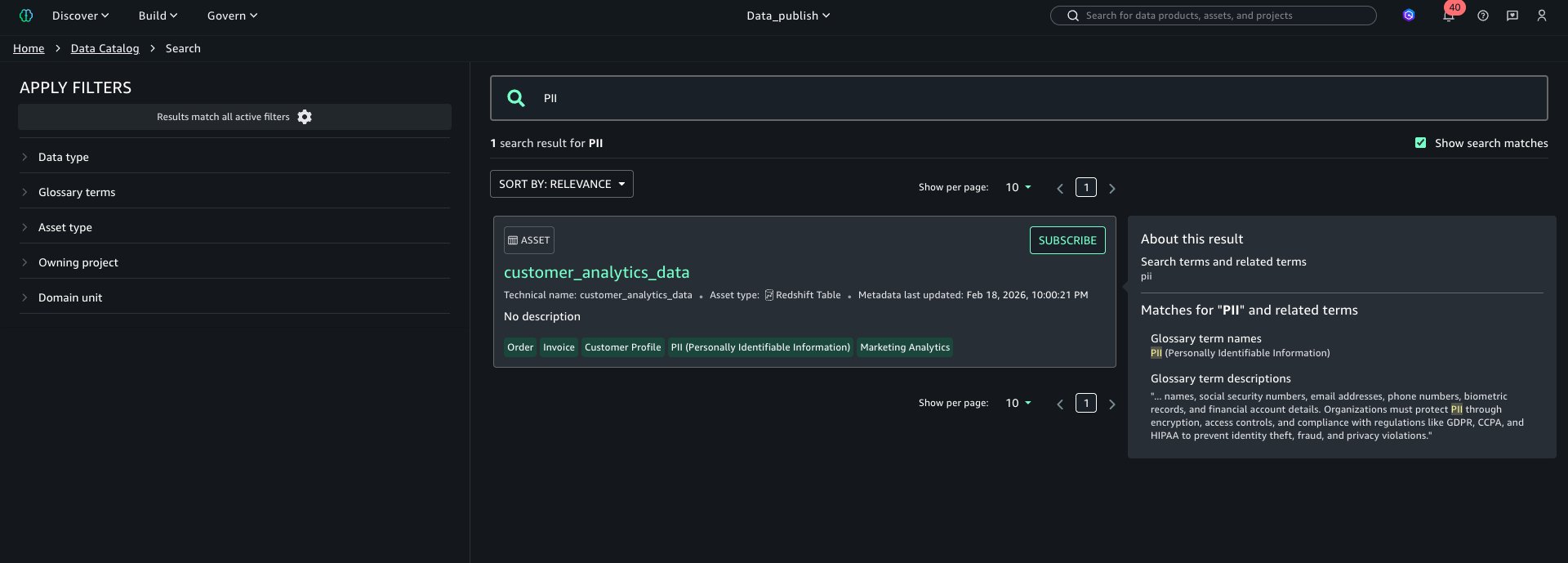
Pundonor
Conclusión
Al estandarizar la terminología en el momento de la publicación, las organizaciones pueden ceñir la desviación de metadatos y mejorar la confiabilidad del descubrimiento. La función se integra con los flujos de trabajo existentes, lo que requiere cambios mínimos en el proceso y, al mismo tiempo, ayuda a ofrecer mejoras inmediatas en la coherencia del catálogo.
Al etiquetar los datos en el momento de la publicación en extensión de corregirlos más tarde, los equipos de datos pueden brindar menos tiempo a corregir los metadatos y más tiempo a utilizarlos. Para obtener más información sobre las capacidades de SageMaker, consulte el catálogo de Amazon SageMaker. Norte del agraciado.
Sobre los autores