
Estamos haciendo código descubierto para la lectura auténtico de RCCLX – una lectura mejorada de RCCL que desarrollamos y probamos en las cargas de trabajo internas de Meta. RCCLX está completamente integrado con Antorchas y tiene como objetivo capacitar a investigadores y desarrolladores para acelerar la innovación, independientemente del backend predilecto.
Los patrones de comunicación para los modelos de IA están en constante progreso, al igual que las capacidades del hardware. Queremos iterar rápidamente sobre colectivos, transportes y funciones novedosas en las plataformas AMD. Anteriormente, desarrollamos y abrimos el código fuente CTranuna biblioteca de transporte personalizada en la plataforma NVIDIA. Con RCCLX, hemos integrado CTran a las plataformas AMD, habilitando AllToAllvDynamic, un colectivo residente en GPU. Si admisiblemente no todas las funciones de CTran están actualmente integradas en la biblioteca RCCLX de código descubierto, nuestro objetivo es tenerlas disponibles en los próximos meses.
En esta publicación, destacamos dos características nuevas: entrada directo a datos (DDA) y colectivos de mengua precisión. Estas características brindan importantes mejoras de rendimiento en las plataformas AMD y estamos entusiasmados de compartir esto con la comunidad.
Ataque directo a datos (DDA): colectivos ligeros adentro del nodo
La inferencia de modelos de lengua noble opera a través de dos etapas computacionales distintas, cada una con características de rendimiento fundamentalmente diferentes:
- La etapa de precarga procesa el mensaje de entrada, que puede englobar miles de tokens, para producir un gusto de valencia secreto (KV) para cada capa de transformador del maniquí. Esta etapa está vinculada a la computación porque el mecanismo de atención escalera cuadráticamente con la largo de la secuencia, lo que la hace muy chinche con los posibles computacionales de la GPU.
- La etapa de decodificación luego utiliza y actualiza incrementalmente la gusto KV para producir tokens uno por uno. A diferencia del prellenado, la decodificación está ligada a la memoria, ya que el tiempo de E/S de la memoria de repaso domina el tiempo de atención, y los pesos del maniquí y la gusto KV ocupan la viejo parte de la memoria.
Paralelismo tensorial permite distribuir modelos en múltiples GPU fragmentando capas individuales en bloques más pequeños e independientes que se ejecutan en diferentes dispositivos. Sin confiscación, un desafío importante es que la operación de comunicación AllReduce puede contribuir hasta un 30% de la latencia de extremo a extremo (E2E). Para enfrentarse este cuello de botella, Meta desarrolló dos algoritmos DDA.
- El cálculo plano DDA progreso la latencia allreduce de mensajes pequeños al permitir que cada rango cargue memoria directamente desde otros rangos y realice operaciones de reducción tópico, reduciendo la latencia de O(N) a O(1) al aumentar el intercambio de datos de O(n) a O(n²).
- El cálculo del árbol DDA divide allreduce en dos fases (reducir-dispersión y colección total) y utiliza entrada directo a datos en cada paso, moviendo la misma cantidad de datos que el cálculo de anillo pero reduciendo la latencia a un creador constante para tamaños de mensajes sutilmente más grandes.
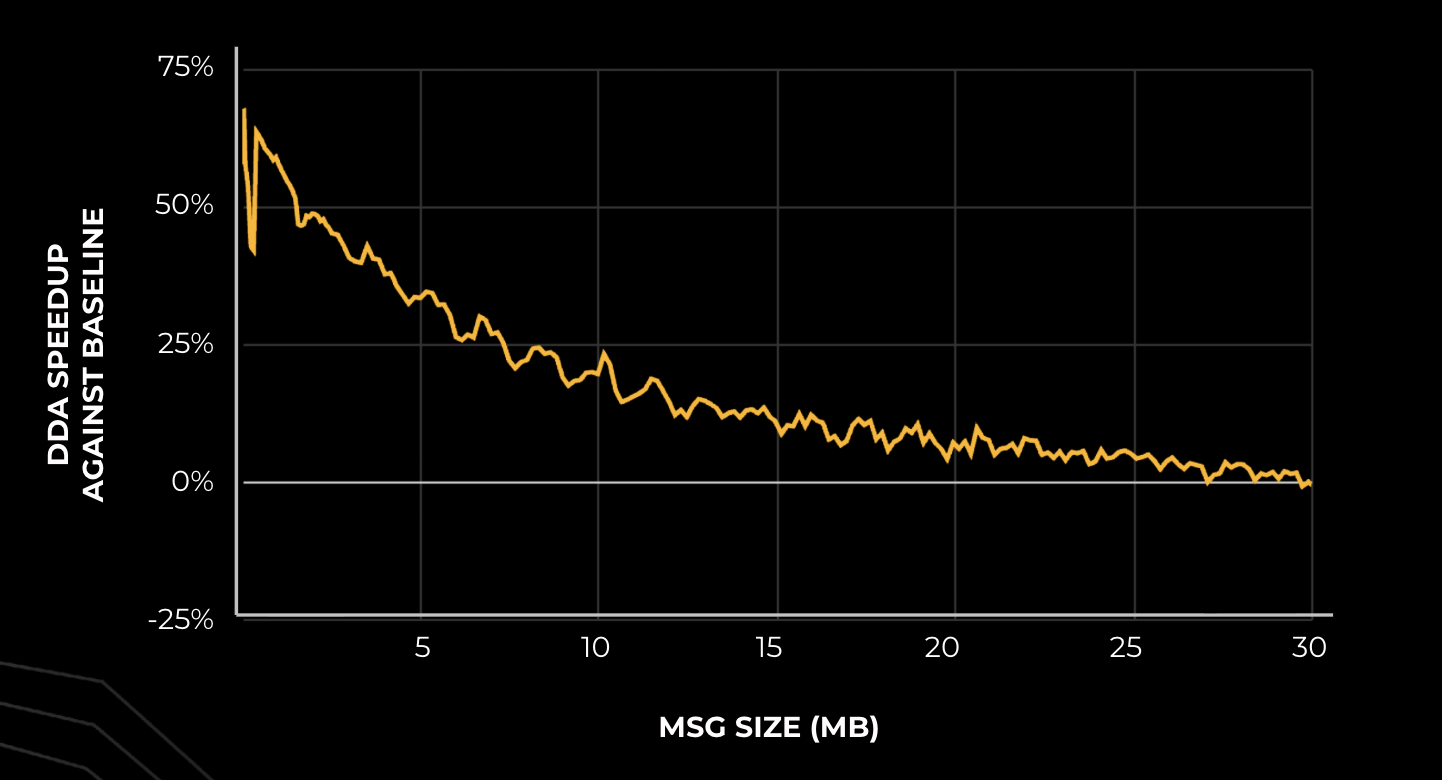
Las mejoras de rendimiento de DDA con respecto a las bibliotecas de comunicación básicas son sustanciales, particularmente en hardware AMD. Con las GPU AMD MI300X, DDA supera la límite cojín RCCL entre un 10 y un 50 % para la decodificación (tamaños de mensajes pequeños) y produce una celeridad del 10 al 30 % para el llenado previo. Estas mejoras dieron como resultado una reducción de aproximadamente un 10 % en el tiempo de adquisición de token incremental (TTIT), lo que mejoró directamente la experiencia del becario durante la grado crítica de decodificación.
Colectivos de mengua precisión
Los colectivos de mengua precisión (LP) son un conjunto de algoritmos de comunicación distribuida (AllReduce, AllGather, AlltoAll y ReduceScatter) optimizados para las GPU AMD Instinct MI300/MI350 para acelerar las cargas de trabajo de inferencia y entrenamiento de IA. Estos colectivos admiten los tipos de datos FP32 y BF16, aprovechando la cuantificación de FP8 para una compresión de hasta 4:1, lo que reduce significativamente la sobrecarga de comunicación y progreso la escalabilidad y la utilización de posibles para mensajes de gran tamaño (≥16 MB).
Los algoritmos utilizan comunicación de malla paralela de igual a igual (P2P), aprovechando al mayor Infinity Fabric de AMD para un detención orondo de costado y mengua latencia, mientras que los pasos de cuenta se realizan con adhesión precisión (FP32) para perseverar la estabilidad numérica. La pérdida de precisión viene dictada principalmente por el número de operaciones de cuantificación (normalmente una o dos por tipo de datos en cada colectivo) y si los datos pueden representarse adecuadamente adentro del rango del 8PM.
Al habilitar dinámicamente los colectivos LP, los usuarios pueden activar selectivamente estas optimizaciones en escenarios E2E que se benefician más de las ganancias de rendimiento. Según experimentos internos, hemos observado una celeridad significativa para FP32 y mejoras notables para BF16; Es importante tener en cuenta que estos colectivos se han conveniente para implementaciones de un solo nodo en este momento.
Acortar la precisión de los tipos puede tener un impacto potencial en la precisión numérica, por lo que lo probamos y descubrimos que proporcionaba una precisión numérica aceptable para nuestras cargas de trabajo. Este enfoque flexible permite a los equipos maximizar el rendimiento manteniendo una precisión numérica aceptable y ahora está completamente integrado y apto en RCCLX para plataformas AMD: simplemente configure la variable de entorno. RCCL_LOW_PRECISION_ENABLE=1 para entablar.
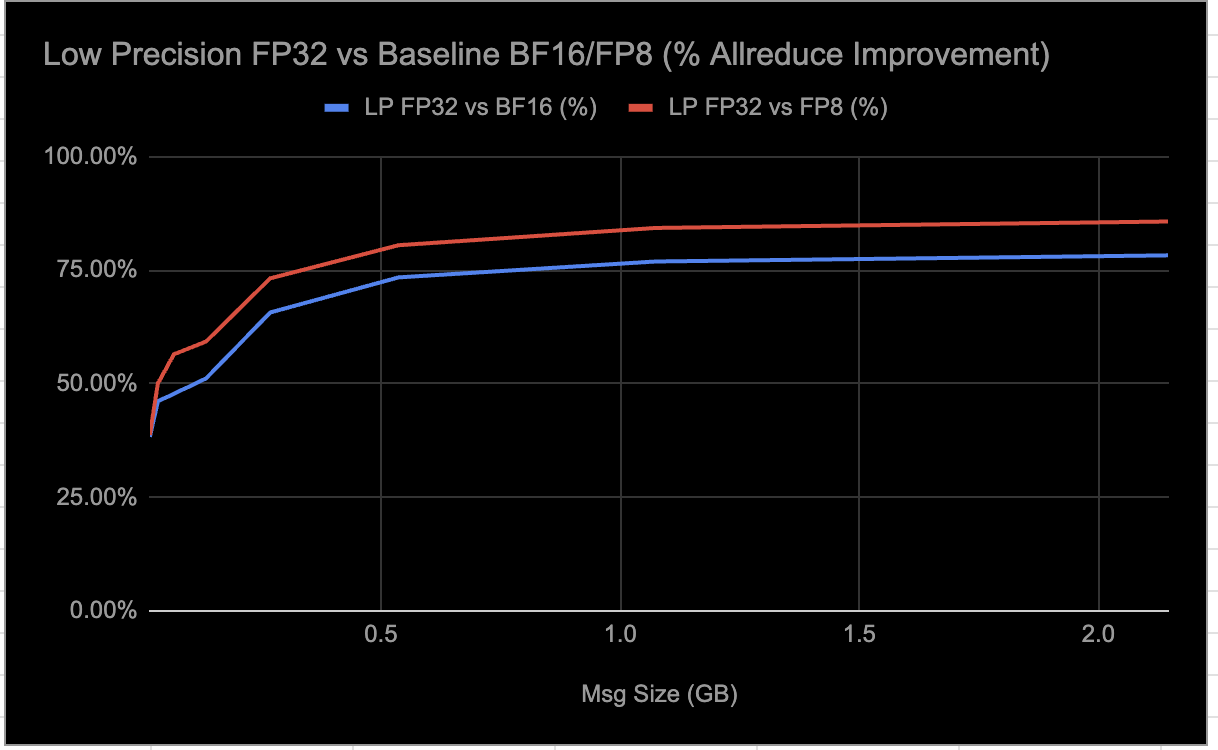
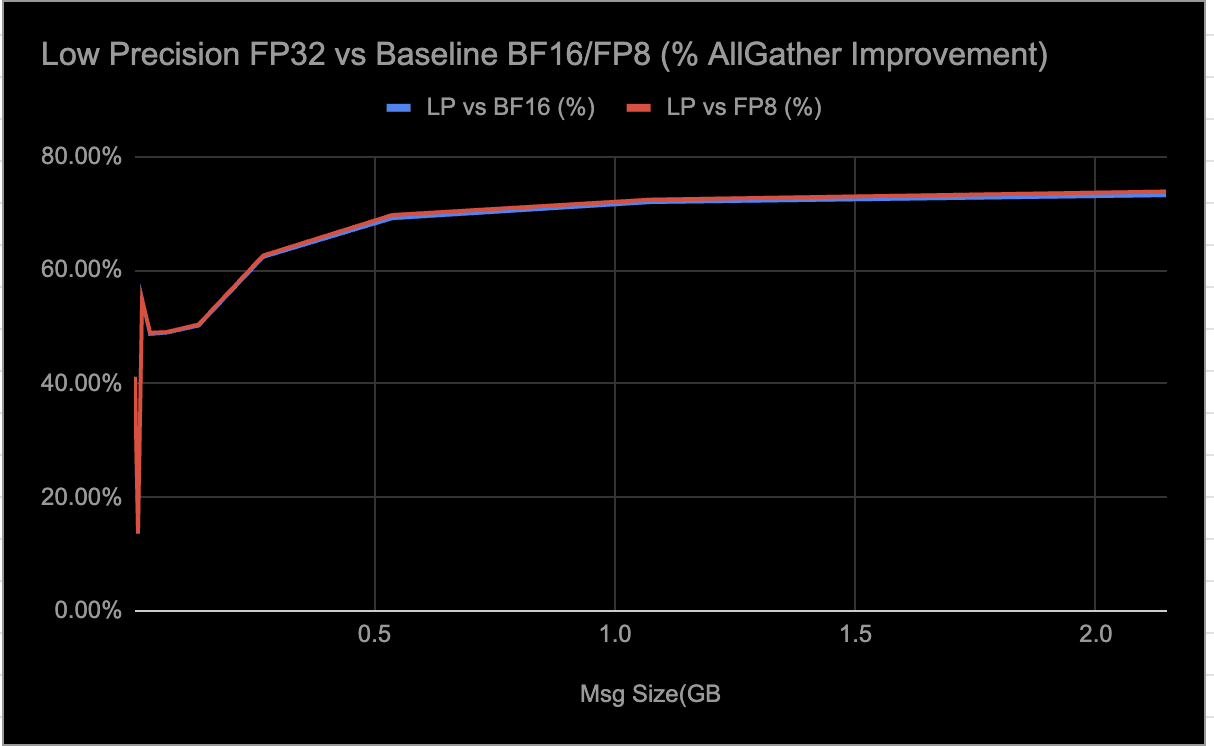
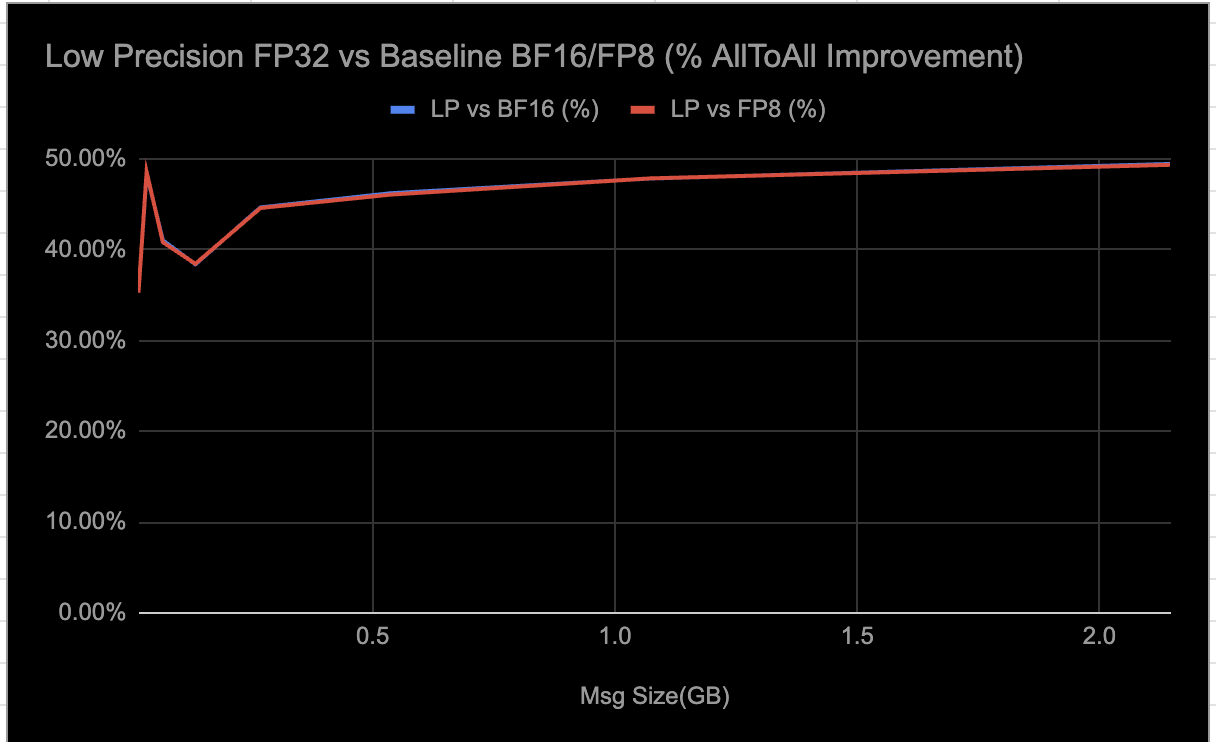
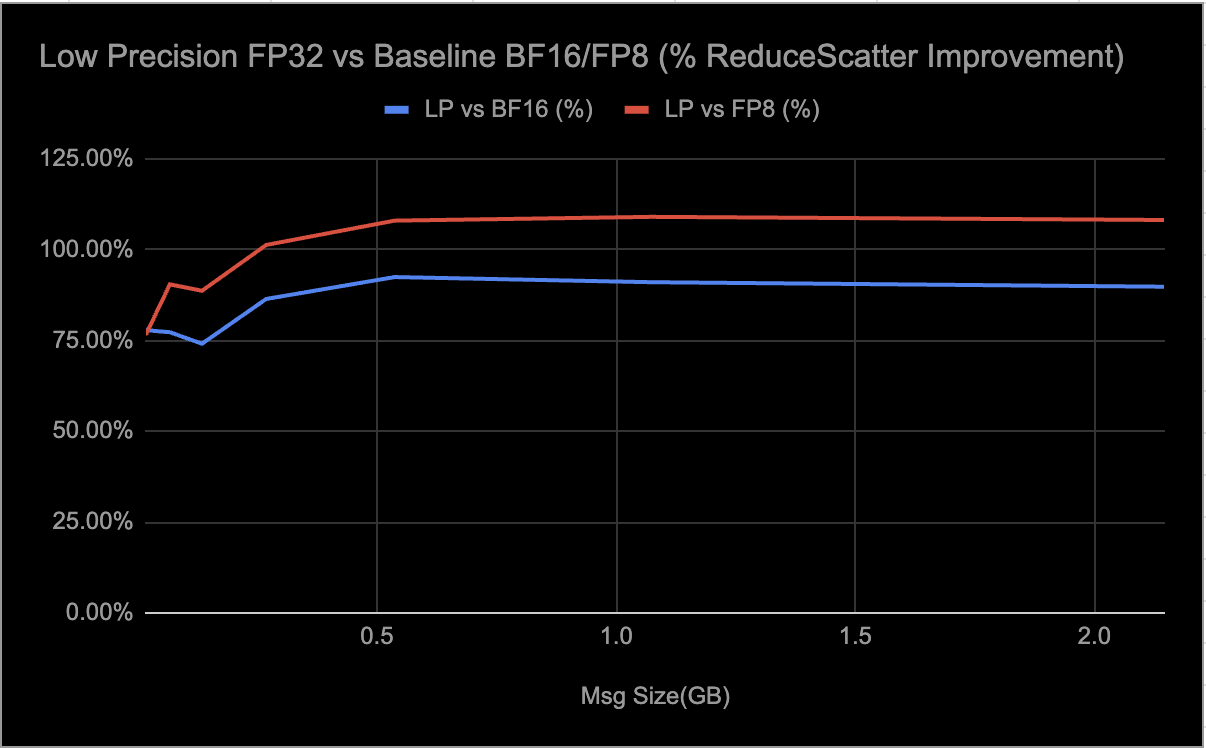
Estamos observando los siguientes resultados de las evaluaciones de carga de trabajo de inferencia E2E al habilitar selectivamente colectivos LP:
- Aproximadamente ~0,3% delta en ejecuciones de evaluación GSM8K.
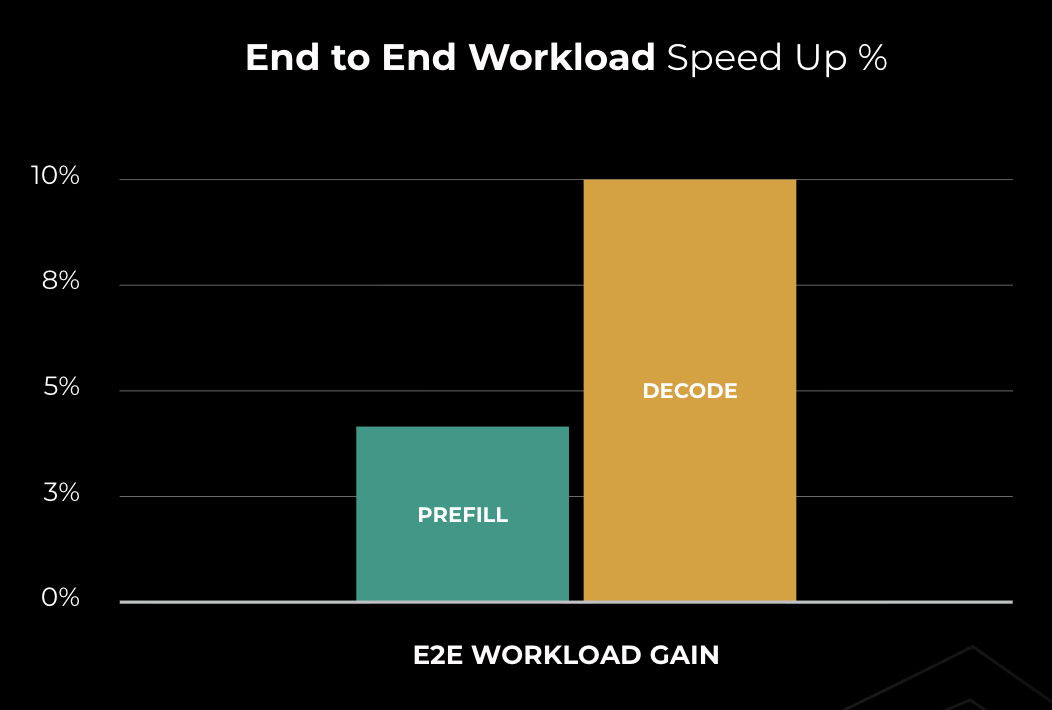
- ~9–10% de disminución en la latencia.
- ~7% de aumento en el rendimiento.
Las mediciones de rendimiento que se muestran en los gráficos se obtuvieron mediante pruebas rccl de tira de parámetros. Para el MI300, las pruebas se realizaron en RCCLX construido con ROCm 6.4, y para el MI350, en RCCLX construido con ROCm 7.0. Cada prueba incluyó 10 iteraciones de calentamiento seguidas de 100 iteraciones de medición. Los resultados informados representan el rendimiento promedio en las iteraciones de medición.
Practicable acomodo de modelos de IA
RCCLX está integrado con la API de Torchcomms como una opción personalizada backend. Nuestro objetivo es que este backend tenga paridad de funciones con nuestro backend NCCLX (para plataformas NVIDIA). Torchcomms permite a los usuarios tener una única API para la comunicación entre diferentes plataformas. Un becario no necesitaría cambiar las API con las que está familiarizado para trasladar sus aplicaciones a través de AMD u otras plataformas, incluso cuando utilice las funciones novedosas proporcionadas por CTran.


Prontuario de inicio rápido de RCCLX
Instale Torchcomms con el backend RCCLX siguiendo los siguientes pasos las instrucciones de instalación en el repositorio de Torchcomms.
import torchcomms
# Eagerly initialize a communicator using MASTER_PORT/MASTER_ADDR/RANK/WORLD_SIZE environment variables
provided by torchrun.
# This communicator is bound to a single device.
comm = torchcomms.new_comm("rcclx", torch.device("hip"), name="my_comm")
print(f"I am rank {comm.get_rank()} of {comm.get_size()}!")
t = torch.full((10, 20), value=comm.rank, dtype=torch.float)
# run an all_reduce on the current stream
comm.allreduce(t, torchcomms.ReduceOp.SUM, async_op=False)
Extendemos nuestro agradecimiento al equipo de AMD RCCL por su continua colaboración. Incluso queremos escudriñar a los muchos empleados actuales y anteriores de Meta cuyas contribuciones fueron vitales en el avance de torchcomms y torchcomms-backends para la capacitación e inferencia a escalera de producción. En particular, nos gustaría dar un agradecimiento exclusivo a Ding Ming Wu, Qiye Tan, Cen Zhao, Yan Cui, Zhe Qu, Ahmed Khan, Ajit Mathews, CQ Tang, Srinivas Vaidyanathan, Harish Kumar Chandrappa, Peng Chen, shashi gandhamy Omar Baldonado