
El futuro de la inteligencia industrial está aquí y, para los desarrolladores, está en forma de nuevas herramientas que transforman la forma en que codificamos, creamos y solucionamos problemas. GLM-4.7 Flash, un maniquí de estilo espacioso de código rajado de Zhipu AI, es el zaguero gran participante, pero no simplemente otra interpretación. Este maniquí aporta un gran poder y una eficiencia asombrosa, por lo que la IA de última reproducción en el campo de la reproducción de código, el razonamiento de múltiples pasos y la reproducción de contenido contribuye al campo como nunca antiguamente. Deberíamos analizar más de cerca las razones por las que GLM-4.7 Flash cambia las reglas del pasatiempo.
Obra y progreso: inteligente, competente y potente
GLM-4.7 Flash tiene en su núcleo una avanzadilla Mezcla de expertos (MoE) Obra transformadora. Piensa en un equipo de profesionales especializados; Supongamos que no todos y cada uno de los expertos se dedican a todos los problemas, sino que sólo los más relevantes se dedican a una tarea particular. Así funcionan los modelos MoE. Aunque todo el maniquí GLM-4.7 contiene enormes y enormes (miles) 358 mil millones de parámetros, solo una subfracción: en torno a de 32 mil millones de parámetros están activos en cualquier consulta en particular.
La interpretación Flash GLM-4.7 es aún más simple con aproximadamente 30 mil millones de parámetros totales y miles de activos por solicitud. Este diseño lo hace muy competente, ya que puede proceder en hardware relativamente pequeño y aun así obtener a una enorme cantidad de conocimiento.
Realizable comunicación API para una integración perfecta
GLM-4.7 Flash es manejable para aparecer. Está habitable como Zhipu. Plataforma API Z.AI proporcionando una interfaz similar a OpenAI o Anthropic. El maniquí además es versátil para una amplia tonalidad de tareas, ya sea que se trate de llamadas REST directas o de un SDK.
Estos son algunos de los usos prácticos con Pitón:
1. Reproducción de texto creativo
¿Necesitas una chispa de creatividad? Puede hacer que el maniquí escriba un poema o una copia de marketing.
import requests
api_url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
user_message = {"role": "user", "content": "Write a short, optimistic poem about the future of technology."}
payload = {
"model": "glm-4.7-flash",
"messages": (user_message),
"max_tokens": 200,
"temperature": 0.8
}
response = requests.post(api_url, headers=headers, json=payload)
result = response.json()
print(result("choices")(0)("message")("content"))Producción:
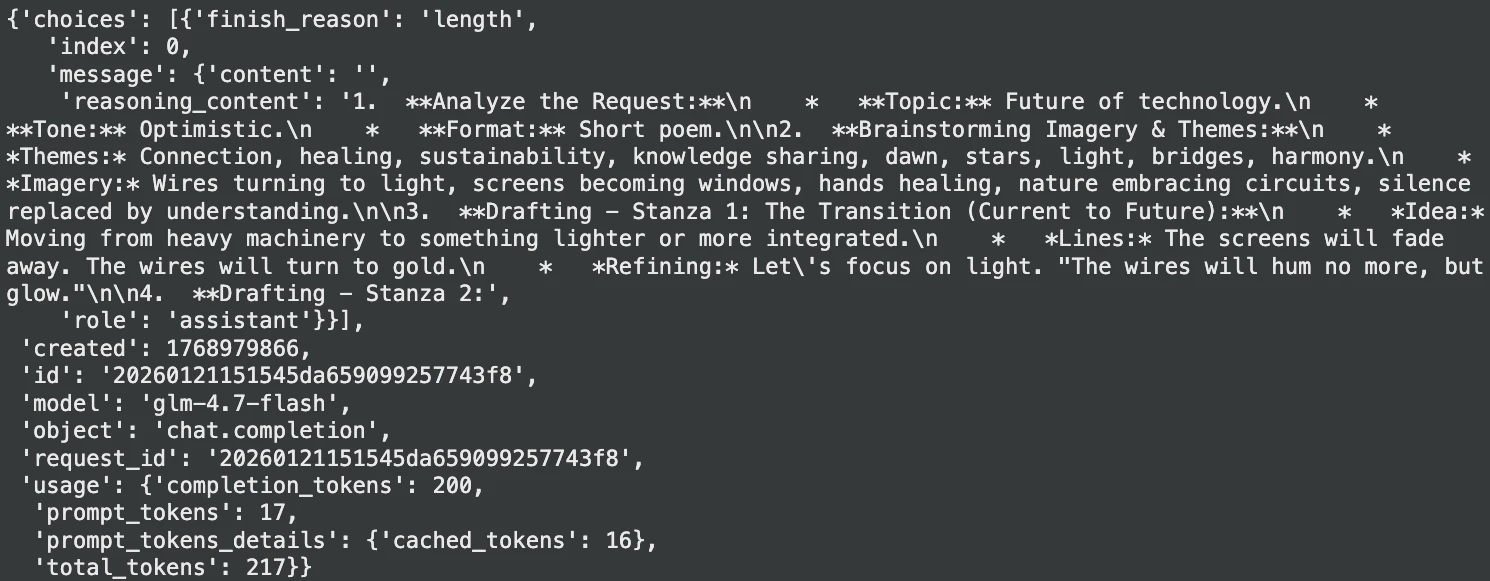
2. Epítome del documento
Tiene una gran ventana contextual que facilita la visualización de documentos extensos.
text_to_summarize = "Your extensive article or report goes here..."
prompt = f"Summarize the following text into three key bullet points:n{text_to_summarize}"
payload = {
"model": "glm-4.7-flash",
"messages": ({"role": "user", "content": prompt}),
"max_tokens": 500,
"temperature": 0.3
}
response = requests.post(api_url, json=payload, headers=headers)
summary = response.json()("choices")(0)("message")("content")
print("Summary:", summary)Producción:
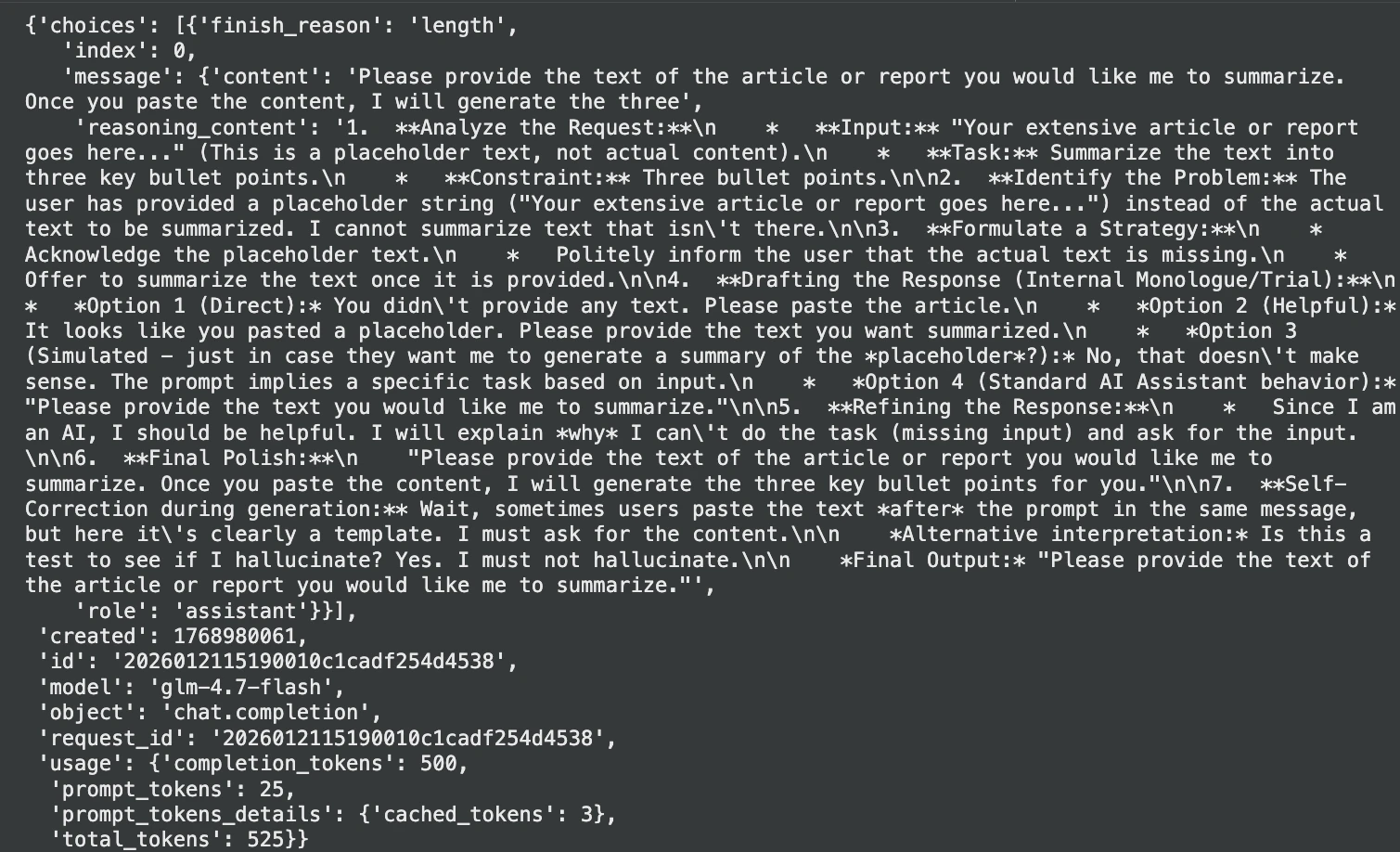
3. Afluencia de codificación avanzadilla
GLM-4.7 Flash es verdaderamente excelente en codificación. Puedes opinar: crear funciones, describir código complicado o incluso depurar.
code_task = (
"Write a Python function `find_duplicates(items)` that takes a list "
"and returns a list of elements that appear more than merienda."
)
payload = {
"model": "glm-4.7-flash",
"messages": ({"role": "user", "content": code_task}),
"temperature": 0.2,
"max_tokens": 300
}
response = requests.post(api_url, json=payload, headers=headers)
code_answer = response.json()("choices")(0)("message")("content")
print(code_answer)Producción:
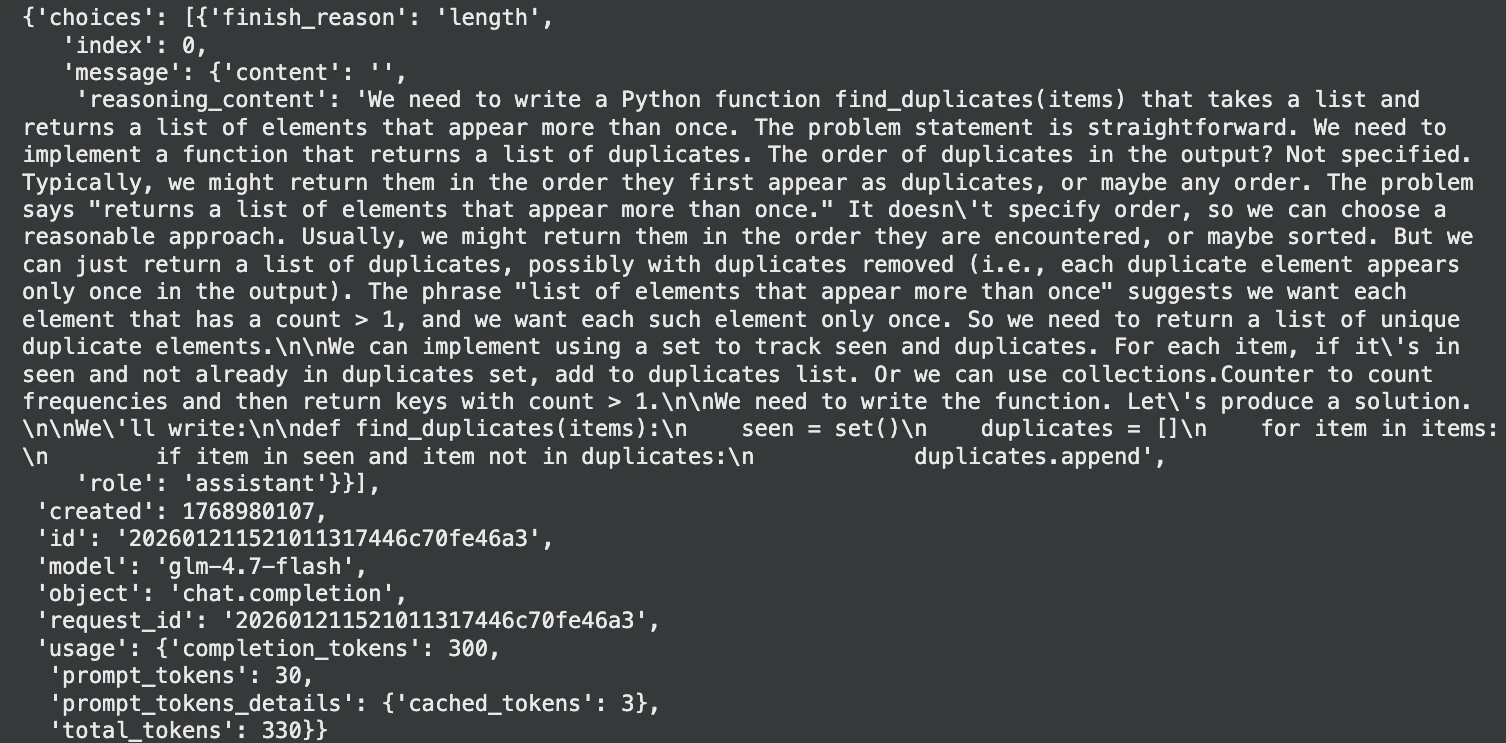
Mejoras esencia que importan
GLM-4.7 Flash no es una aggiornamento ordinaria, pero presenta muchas mejoras con respecto a sus otras versiones.
- Codificación mejorada y “Codificación Vibe”: Este maniquí se optimizó en grandes conjuntos de datos de código y, por lo tanto, su rendimiento en los puntos de narración de codificación fue competitivo con modelos propietarios más grandes. Encima, surge la principios de codificación Vibe, donde se considera el formato del código, el estilo e incluso la apariencia de la interfaz de favorecido para producir una apariencia más fluida y profesional.
- Razonamiento de varios pasos más sólido: Este es un aspecto distintivo ya que se potencia el razonamiento.
- Razonamiento entrelazado: El maniquí procesa las instrucciones y luego piensa (antiguamente de avanzar en objetar o designar a una utensilio) para que sea más apto para seguir las instrucciones complejas.
- Razonamiento preservado: Conserva su procedimiento de razonamiento durante varios turnos de una conversación, por lo que no olvidará el contexto en una tarea larga y compleja.
- Control de nivel de libramiento: Los desarrolladores pueden encargar la profundidad del razonamiento realizado por cada consulta del maniquí para conseguir un consistencia entre velocidad y precisión.
- Velocidad y rentabilidad: La interpretación Flash se centra en la velocidad y el costo. Zhipu AI es gratis para los desarrolladores y sus tasas de API son mucho más bajas que las de la mayoría de los competidores, lo que significa que se puede obtener a una IA potente para proyectos de cualquier tamaño.
Casos de uso: de la codificación agente a la IA empresarial
GLM-4.7 Flash tiene el potencial de muchas aplicaciones adecuado a su versatilidad.
- Codificación agente y automatización: Este muestra puede servir como un agente de software de IA, al que se le puede proporcionar un objetivo de parada nivel y producir una respuesta completa y de varias partes. Es lo mejor en creación rápida de prototipos y código repetitivo maquinal.
- Disección de contenido de formato holgado: Su enorme ventana contextual es ideal para resumir informes extensos, analizar archivos de registro o objetar preguntas que requieren documentación extensa.
- Soluciones empresariales: GLM-4.7 Flash utilizado como código rajado autohospedado y optimizado permite a las empresas utilizar datos internos para formar sus propios asistentes de inteligencia industrial de propiedad privada.
Rendimiento que dice mucho
GLM-4.7 Flash es una utensilio de parada rendimiento, probada mediante pruebas comparativas. Ha obtenido los mejores resultados en los difíciles modelos de codificación como SWE-Bench y LiveCodeBench utilizando programas de código rajado.
GLM-4.7 obtuvo una puntuación del 73,8 por ciento en una prueba en SWE-Bench, que implica la resolución de problemas reales de GitHub. Todavía fue superior en matemáticas y razonamiento, obteniendo una puntuación del 95,7 por ciento en el examen de matemáticas AI (AIME) y mejorando en un 12 por ciento con respecto a su predecesor en el difícil punto de narración de razonamiento HLE. Estas cifras muestran que el GLM-4.7 Flash no sólo compite con otros modelos de su tipo, sino que suele ser más astuto que ellos.
Por qué GLM-4.7 Flash es tan importante
Este maniquí es importante por varias razones:
- Parada rendimiento a bajo costo: Ofrece características que pueden competir con los modelos propietarios de tonalidad más adhesión a una pequeña fracción del costo. Esto permite que la IA avanzadilla esté habitable para desarrolladores personales y nuevas empresas, así como para grandes empresas.
- Código rajado y flexible: GLM-4.7 Flash es gratis, lo que significa que ofrece control ilimitado. Puede personalizarlo para dominios específicos, implementarlo localmente para respaldar la privacidad de los datos y evitar la dependencia de un proveedor.
- Centrado en el desarrollador por diseño: El maniquí es manejable de integrar en los flujos de trabajo de los desarrolladores y admite una API compatible con OpenAI con soporte de herramientas integradas..
- Resolución de problemas de principio a fin: GLM-4.7 Flash es capaz de ayudar a resolver tareas más grandes y complicadas en una secuencia. Esto libera a los desarrolladores para concentrarse en el enfoque de parada nivel y la novedad, en lado de perder de panorámica los detalles de la implementación.
Conclusión
GLM-4.7 Flash es un gran brinco en dirección a lo esforzado, útil y habitable AI. Puede personalizarlo para dominios específicos, implementarlo localmente para proteger la privacidad de los datos y evitar la dependencia de un proveedor. GLM-4.7 Flash ofrece los medios para crear más, en menos tiempo, ya sea que esté creando la próxima gran aplicación, automatizando procesos complejos o simplemente necesite un socio de codificación más inteligente. Ha llegado la era del desarrollador totalmente capacitado y los esquemas de código rajado como GLM-4.7 Flash están en primera hilera.
Preguntas frecuentes
R. GLM-4.7 Flash es un maniquí de estilo voluble y de código rajado diseñado para desarrolladores, que ofrece un sólido rendimiento en codificación, razonamiento y reproducción de texto con adhesión eficiencia.
R. Es un diseño de maniquí en el que existen muchos submodelos especializados (“expertos”), pero solo unos pocos se activan para una tarea determinada, lo que hace que el maniquí sea muy competente.
R. La serie GLM-4.7 admite una ventana de contexto de hasta 200.000 tokens, lo que le permite procesar grandes cantidades de texto a la vez.
Harsh Mishra es un ingeniero de IA/ML que pasa más tiempo hablando con modelos de estilo grandes que con humanos reales. Apasionado por GenAI, PNL y hacer que las máquinas sean más inteligentes (para que no lo reemplacen todavía). Cuando no optimiza modelos, probablemente esté optimizando su consumo de café. 🚀☕
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.