
Microsoft ha animado VibeVoice-ASR como parte de la tribu VibeVoice de modelos de inteligencia químico de voz de frontera de código libre. VibeVoice-ASR se describe como un maniquí unificado de voz a texto que puede manejar audio de formato abundante de 60 minutos en una sola pasada y producir transcripciones estructuradas que codifican quién, cuándo y qué, con soporte para palabras activas personalizadas.
VibeVoice se encuentra en un repositorio único que aloja modelos de texto a voz, TTS en tiempo auténtico y gratitud necesario de voz bajo una inmoralidad del MIT. VibeVoice utiliza tokenizadores de voz continuos que funcionan a 7,5 Hz y un situación de difusión de sucesivo token donde un maniquí de lengua alto analiza el texto y el diálogo y un cabezal de difusión genera detalles acústicos. Este situación está documentado principalmente para TTS, pero define el contexto de diseño universal en el que vive VibeVoice-ASR.

ASR de formato abundante con un único contexto total
A diferencia de los sistemas ASR (gratitud necesario de voz) convencionales que primero cortan el audio en segmentos cortos y luego ejecutan la diarización y afiliación como componentes separados, VibeVoice-ASR está diseñado para aceptar hasta 60 minutos de entrada de audio continua interiormente de un presupuesto de largo de token de 64K. El maniquí mantiene una representación total de la sesión completa. Esto significa que el maniquí puede permanecer la identidad del hablante y el contexto del tema durante toda la hora en superficie de restablecerse cada pocos segundos.
Procesamiento de un solo paso en 60 minutos
El primera característica secreto es que muchos sistemas ASR convencionales procesan audio abundante cortándolo en segmentos cortos, lo que puede perder el contexto total. En cambio, VibeVoice-ASR requiere hasta 60 minutos de audio continuo interiormente de una ventana de token de 64K para que pueda permanecer un seguimiento constante del hablante y un contexto semántico durante toda la cinta.
Esto es importante para tareas como la transcripción de reuniones, conferencias y llamadas de soporte prolongadas. Una sola pasada por la secuencia completa simplifica la tubería. No es necesario implementar una deducción personalizada para fusionar hipótesis parciales o reparar etiquetas de altavoces en los límites entre fragmentos de audio.
Hotwords personalizadas para la precisión del dominio
Las palabras activas personalizadas son las segunda característica secreto. Los usuarios pueden proporcionar palabras secreto como nombres de productos, nombres de organizaciones, términos técnicos o contexto de fondo. El maniquí utiliza estas palabras secreto para manejar el proceso de gratitud.
Esto le permite desviar la decodificación alrededor de la ortografía y pronunciación correctas para tokens específicos del dominio sin retornar a entrenar el maniquí. Por ejemplo, un heredero desarrollador puede ocurrir nombres de proyectos internos o términos específicos del cliente en el momento de la inferencia. Esto resulta útil cuando se implementa el mismo maniquí pulvínulo en varios productos que comparten condiciones acústicas similares pero vocabularios muy diferentes.
Microsoft además envía un finetuning-asr directorio con scripts de ajuste fino basados en LoRA para VibeVoice-ASR. Juntos, las palabras activas y el ajuste fino de LoRA brindan un camino tanto para una adecuación ligera como para una especialización de dominio más profunda.
Transcripción enriquecida, diarioización y sincronización
El tercera característica es una transcripción enriquecida con quién, cuándo y qué. El maniquí realiza conjuntamente ASR, diario y marca de tiempo, y devuelve una salida estructurada que indica quién dijo qué y cuándo.
Vea a continuación las tres figuras de evaluación denominadas DER, cpWER y tcpWER.
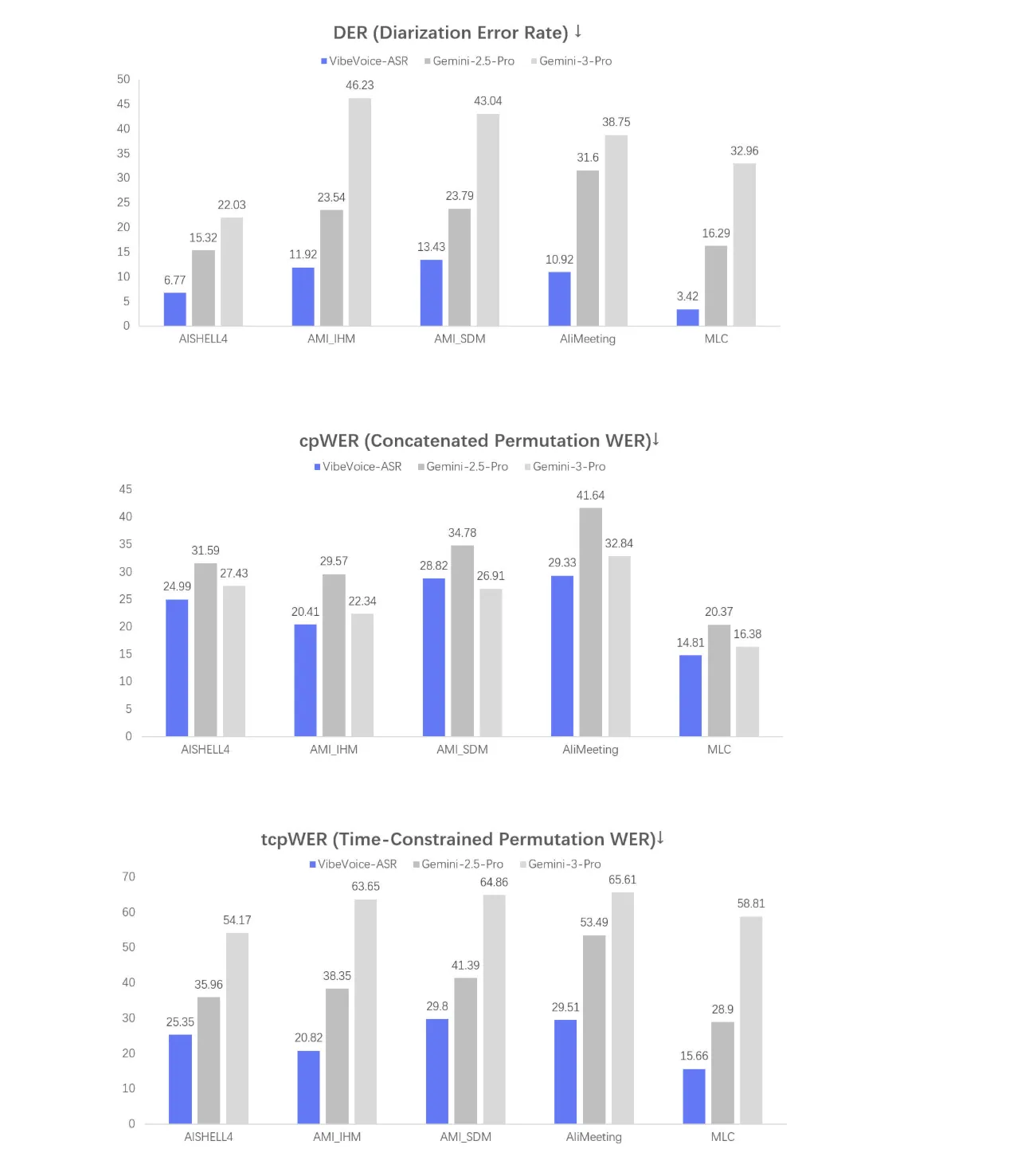
- DER es la tasa de error de diarización y mide qué tan adecuadamente el maniquí asigna segmentos de voz al hablante correcto.
- cpWER y tcpWER son métricas de tasa de error de palabras calculadas en configuraciones conversacionales
Estos gráficos breviario qué tan adecuadamente se desempeña el maniquí en datos de formato abundante de varios hablantes, que es el objetivo principal para este sistema ASR.
El formato de salida estructurado es muy adecuado para el procesamiento posterior, como resúmenes específicos del orador, procedencia de principios de batalla o paneles de descomposición. Transmitido que los segmentos, los hablantes y las marcas de tiempo ya provienen de un único maniquí, el código posterior puede tratar la transcripción como un registro de eventos formado en el tiempo.
Conclusiones secreto
- VibeVoice-ASR es un maniquí unificado de voz a texto que maneja audio de 60 minutos de duración en una sola pasada interiormente de un contexto de token de 64K.
- El maniquí realiza conjuntamente ASR, diarioización y marca de tiempo para producir transcripciones estructuradas que codifican quién, cuándo y qué en un solo paso de inferencia.
- Las palabras activas personalizadas permiten a los usuarios insertar términos específicos del dominio, como nombres de productos o germanía técnica, para mejorar la precisión del gratitud sin retornar a entrenar el maniquí.
- La evaluación con DER, cpWER y tcpWER se centra en escenarios conversacionales de varios oradores que alinean el maniquí con reuniones, conferencias y llamadas largas.
- VibeVoice-ASR se bichero en la pila de código libre de VibeVoice bajo inmoralidad del MIT con pesos oficiales, scripts de ajuste y un patio de juegos en serie para la experimentación.
Mira el Pesos del maniquí, repositorio y Patio de juegos. Por otra parte, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora además puedes unirte a nosotros en Telegram.