
Los grandes modelos de IA están escalando rápidamente, con arquitecturas más grandes y ciclos de entrenamiento más largos convirtiéndose en la norma. Sin secuestro, a medida que los modelos crecen, un problema fundamental de estabilidad del entrenamiento sigue sin resolverse. DeepSeek mHC aborda directamente este problema repensando cómo se comportan las conexiones residuales a escalera. Este artículo explica DeepSeek mHC (hiperconexiones restringidas por múltiples) y muestra cómo restablecimiento maniquí de jerigonza noble Estabilidad y rendimiento del entrenamiento sin asociar complejidad arquitectónica innecesaria.
El problema oculto de las hiperconexiones residuales
Las conexiones residuales han sido un componente central del educación profundo desde el dispersión de Resnet en 2016. Permiten que las redes creen rutas de entrada directo, permitiendo que la información fluya directamente a través de capas en zona de retornar a aprenderse en cada paso. En términos simples, actúan como carriles expresos en una autopista, lo que facilita el entrenamiento de redes profundas.
Este enfoque funcionó adecuadamente durante abriles. Pero a medida que los modelos pasaron de millones a miles de millones, y ahora a cientos de miles de millones de parámetros, sus limitaciones se hicieron claras. Para impulsar aún más el rendimiento, los investigadores introdujeron Hyper-Connections (HC), ampliando efectivamente estas autopistas de información al asociar más rutas. El rendimiento mejoró notablemente, pero la estabilidad no.
La formación se volvió muy inestable. Los modelos se entrenarían normalmente y luego colapsarían repentinamente rodeando de un paso específico, con fuertes picos de pérdida y gradientes explosivos. Para los equipos que entrenan modelos de jerigonza grandes, este tipo de rotura puede significar desperdiciar enormes cantidades de computación, tiempo y bienes.
¿Qué son las hiperconexiones restringidas por colector (mHC)?
Es un entorno universal que asigna el espacio de conexión residual de HC a una determinada variedad para reanimar la propiedad de mapeo de identidad y, al mismo tiempo, implica una optimización estricta de la infraestructura para que sea eficaz.
Las pruebas empíricas muestran que mHC es bueno para la capacitación a gran escalera, ya que ofrece no solo claras ganancias de rendimiento sino además una excelente escalabilidad. Esperamos que mHC, al ser una aditamento versátil y accesible a HC, ayude en la comprensión del diseño de la cimentación topológica y proponga nuevos caminos para el ampliación de modelos fundamentales.
¿Qué hace que mHC sea diferente?
La táctica de DeepSeek no sólo es inteligente, es brillante porque te hace pensar: «Oh, ¿por qué nadie había pensado en esto antaño?» Todavía mantuvieron las Hiperconexiones pero las limitaron con un método matemático preciso.
Esta es la parte técnica (no me desanimes, valdrá la pena entenderlo): las conexiones residuales estereotipado permiten realizar lo que se conoce como “mapeo de identidad”. Imagínelo como la ley de conservación de la energía donde las señales que viajan a través de la red lo hacen al mismo nivel de potencia. Cuando HC aumentó el encantado del flujo residual y lo combinó con patrones de conexión que se podían educarse, violaron involuntariamente esta propiedad.
Los investigadores de DeepSeek comprendieron que los mapeos compuestos de HC, esencialmente, cuando se siguen apilando estas conexiones capa tras capa, aumentaban las señales mediante multiplicadores de 3000 veces o incluso más. Imagínese que está organizando un diálogo y cada vez que cualquiera comunica su mensaje, toda la sala lo grita 3000 veces más esforzado. Eso no es más que caos.
mHC resuelve el problema proyectando estas matrices de conexión en el politopo de Birkhoff, un objeto geométrico conceptual en el que cada fila y columna tiene una suma igual a 1. Puede parecer teórico, pero en efectividad hace que la red trate la propagación de señales como una combinación convexa de características. No más explosiones, no más señales que desaparezcan por completo.
La cimentación: cómo funciona verdaderamente mHC
Exploremos los detalles de cómo DeepSeek cambió las conexiones interiormente del maniquí. El diseño depende de tres mapeos principales que determinan la dirección de la información:
El sistema de tres mapas
En Hyper-Connections, tres matrices que se pueden educarse realizan diferentes tareas:
- H_pre: Lleva la información del flujo residual extendido a la capa.
- H_post: Envía la salida de la capa de regreso a la secuencia.
- H_res: Combina y actualiza la información en la propia transmisión.
Visualícelo como un sistema de autopistas donde H_pre es la rampa de entrada, H_post es la rampa de salida y H_res es el administrador del flujo de tráfico entre los carriles.
Uno de los hallazgos de los estudios de separación de DeepSeek es muy interesante: H_res (el mapeo chapón a los residuos) es el principal contribuyente al aumento del rendimiento. Lo desactivaron, permitiendo solo asignaciones previas y posteriores, y el rendimiento disminuyó drásticamente. Esto es inductivo: lo más destacado del proceso es cuando entidades de diferentes profundidades interactúan e intercambian información.
La restricción múltiple
Este es el punto donde la mHC comienza a desviarse de la HC regular. En zona de permitir que H_res se seleccione arbitrariamente, imponen que sea doblemente probabilístico, que es una característica según la cual cada fila y cada columna suman 1.
¿Cuál es la importancia de esto? Hay tres razones secreto:
- Las normas se mantienen intactas: La norma fantasmal se mantiene interiormente de los límites de 1, por lo que los gradientes no pueden explotar.
- Vallado bajo composición: Duplicar matrices doblemente estocásticas da como resultado otra matriz doblemente estocástica; por lo tanto, toda la profundidad de la red sigue siendo estable.
- Una ilustración en términos de geometría: Las matrices están en el politopo de Birkhoff, que es la cáscara convexa de todas las matrices de permutación. Para decirlo de otra forma, la red aprende combinaciones ponderadas de patrones de enrutamiento donde la información fluye de forma diferente.
El cálculo Sinkhorn-Knopp es el que se utiliza para hacer cumplir esta restricción, que es un método iterativo que sigue normalizando filas y columnas alternativamente hasta que se alcanza la precisión deseada. En los experimentos, se estableció que 20 iteraciones producen una perspectiva adecuada sin cálculos excesivos.
Detalles de parametrización
La ejecución es inteligente. En zona de trabajar con vectores de características únicas, mHC comprime toda la matriz oculta de n×C en un solo vector. Esto permite utilizar la información de contexto completa en el cálculo del mapeo dinámico.
Se aplican las últimas asignaciones restringidas:
- Activación sigmoidea para H_pre y H_post (garantizando así la no negatividad)
- Proyección de Sinkhorn-Knopp para H_res (aplicando así doble estocasticidad)
- Títulos de inicialización pequeños (α = 0,01) para factores de activación para comenzar con conservadores
Esta configuración detiene la rescisión de la señal causada por las interacciones entre coeficientes positivos-negativos y al mismo tiempo mantiene la muy importante propiedad de mapeo de identidad.
Comportamiento de escalera: ¿se mantiene?
Una de las cosas más sorprendentes es cómo aumentan los beneficios del mHC. DeepSeek realizó sus experimentos en tres dimensiones diferentes:
- Escalado de cálculo: Entrenaron con parámetros 3B, 9B y 27B con datos proporcionales. La superioridad de rendimiento siguió siendo la misma e incluso aumentó tenuemente con presupuestos más altos para la computación. Esto es increíble porque, por lo universal, muchos trucos arquitectónicos que funcionan a pequeña escalera no funcionan cuando se amplían.
- Escalado de tokens: Supervisaron el rendimiento durante todo el entrenamiento de su maniquí 3B entrenado en 1 billón de tokens. La restablecimiento de las pérdidas fue estable desde el entrenamiento original hasta la etapa de convergencia, lo que indica que los beneficios de mHC no se limitan al período de entrenamiento original.
- Estudio de propagación: ¿Recuerdas esos factores de amplificación de señal de 3000x en Vanilla HC? Con mHC, la magnitud de rendimiento máxima se redujo a rodeando de 1,6, siendo tres órdenes de magnitud más estable. Incluso posteriormente de componer más de 60 capas, las ganancias de la señal en dirección a delante y en dirección a a espaldas permanecieron adecuadamente controladas.
Puntos de remisión de rendimiento
DeepSeek evaluó mHC en diferentes modelos con tamaños de parámetros que oscilaban entre 3 mil millones y 27 mil millones y las ganancias de estabilidad fueron particularmente visibles:
- La pérdida de entrenamiento fue suave durante todo el proceso sin picos repentinos
- Las normas de gradiente se mantuvieron en el mismo rango, en contraste con HC, que mostró un comportamiento salvaje
- Lo más significativo fue que el rendimiento no solo mejoró sino que además se demostró en varios puntos de remisión.
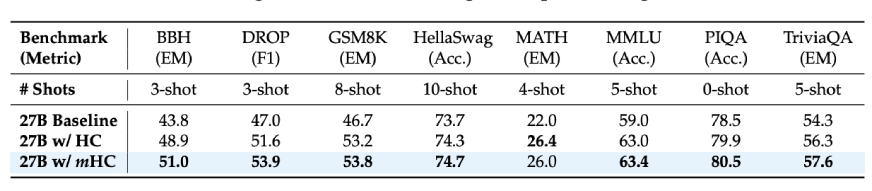
Si consideramos los resultados de las tareas posteriores para el maniquí 27B:
- Tareas de razonamiento de BBH: 51,0 % (frente al 43,8 % de remisión)
- CAÍDA en comprensión lectora: 53,9% (frente al 47,0% de remisión)
- Problemas matemáticos de GSM8K: 53,8 % (frente al 46,7 % de remisión)
- Conocimiento de MMLU: 63,4 % (frente al 59,0 % de remisión)
Esto no representa mejoras menores, pero de hecho, estamos hablando de aumentos de 7 a 10 puntos en puntos de remisión de razonamiento difíciles. Encima, estas mejoras no solo se observaron en los modelos más grandes, sino además durante períodos de entrenamiento más largos, como fue el caso del escalamiento de los modelos de educación profundo.
Lea además: DeepSeek-V3.2-Exp: 50% más saldo, 3 veces más rápido, valencia mayor
Conclusión
Si está trabajando o entrenando modelos de jerigonza grandes, mHC es un aspecto que definitivamente debe considerar. Es uno de esos artículos raros que identifica un problema positivo, presenta una alternativa matemáticamente válida e incluso demuestra que funciona a gran escalera.
Las principales revelaciones son:
- El aumento del encantado del flujo residual conduce a un mejor rendimiento; sin secuestro, los métodos ingenuos causan inestabilidad
- Condicionar las interacciones a matrices doblemente estocásticas conserva las propiedades del mapeo de identidad
- Si se hace adecuadamente, los gastos generales tan pronto como se notan
- Las ventajas se pueden retornar a aplicar a modelos con un tamaño de decenas de miles de millones de parámetros.
Encima, mHC nos recuerda que el diseño arquitectónico sigue siendo un factótum crucial. La cuestión de cómo utilizar más computación y datos no puede durar para siempre. Habrá ocasiones en las que será necesario dar un paso a espaldas, comprender el motivo del error a gran escalera y solucionarlo adecuadamente.
Y para ser honesto, este tipo de investigaciones es lo que más me gusta. No se deben hacer pequeños cambios, sino más adecuadamente cambios profundos que harán que todo el campo sea un poco más sólido.
Pasante de vivientes de IA en Analytics Vidhya
Área de Ciencias de la Computación, Instituto de Tecnología de Vellore, Vellore, India
Actualmente trabajo como pasante de Gen AI en Analytics Vidhya, donde contribuyo a soluciones innovadoras impulsadas por AI que permiten a las empresas emplear los datos de forma efectiva. Como estudiante de posterior año de Ciencias de la Computación en el Instituto de Tecnología Vellore, aporto a mi puesto una almohadilla sólida en ampliación de software, exploración de datos y educación inconsciente.
No dudes en conectarte conmigo en (correo electrónico protegido)
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.