
Esta publicación fue escrita con Avinash Erupaka de Bayer (IT PH, plataforma de innovación farmacológica)
¿Cómo pueden las empresas farmacéuticas desbloquear todo el potencial de sus datos para impulsar innovaciones revolucionarias? Bayerlíder mundial en salubridad y sustento, se dedica a encarar los desafíos apremiantes de nuestro tiempo, incluida una población en crecimiento y envejecimiento y la presión sobre los ecosistemas de nuestro planeta. Su comisión de “Vigor para todos, penuria para nadie” impulsa su compromiso de encarar las evacuación sociales y ambientales a través de investigaciones innovadoras. Bayer se centra en desarrollar soluciones innovadoras que marquen una diferencia tangible en el mundo y valencia para sus clientes, empleados y partes interesadas. Con sede en Leverkusen, Alemania, Bayer opera en 80 países y es pionera en un ecosistema de ciencia de datos que transforma la forma en que los equipos de investigación acceden, analizan y obtienen conocimientos a partir de datos científicos complejos.
Al emplear el poder de los datos, el prospección, la inteligencia fabricado y el estudios inconsciente (AI/ML) y la IA generativa, Bayer está creando un ecosistema de ciencia de datos (DSE) de investigación y progreso farmacéutico basado en la cúmulo en AWS que impulsa tecnologías y conceptos de vanguardia con una sólida trámite de datos. Al hacerlo, los equipos de I+D pueden emplear plenamente el potencial de los datos y prospección unificados.
En esta publicación, analizamos cómo Bayer utilizó la próxima concepción de SageMaker para crear una decisión que unifique la ingesta de datos, el almacenamiento, el prospección y los flujos de trabajo de IA/ML. Basado en principios de malla de datos, DSE de Bayer integra flujos de trabajo avanzados de ingesta, almacenamiento, prospección y estudios inconsciente de datos para permitir una experimentación ágil y una concepción de información escalable. democratiza el ataque a prospección, fomenta la colaboración entre regiones y proporciona una integración flexible de datos estructurados, semiestructurados y no estructurados.
Desafíos en la investigación farmacéutica
En la investigación farmacéutica, los datos se han convertido en el activo más crítico para impulsar la innovación. Sin requisa, mandar estos datos de forma eficaz presenta desafíos sin precedentes y los enfoques tradicionales de trámite de datos se están volviendo cada vez más inadecuados para iniciativas de investigación globales complejas. Muchas organizaciones de I+D farmacéuticas se enfrentan a un complicado ecosistema de obstáculos relacionados con datos y prospección que obstaculizan el descubrimiento estudiado y la eficiencia operativa:
- Conjuntos de datos en silos – Los conjuntos de datos de investigación están aislados en todos los dominios, lo que limita la reutilización y ralentiza el descubrimiento.
- Múltiples modalidades de datos – Los datos de ensayos clínicos (estructurados), la evidencia del mundo positivo (semiestructurados) y los archivos genómicos (no estructurados) existían de forma aislada, lo que complicaba la integración y el prospección.
- Capacidades de ingesta inflexibles – Sistemas que admiten procesamiento por lotes (como datos de prueba), flujos de datos en tiempo positivo (por ejemplo, de equipos de laboratorio) e ingesta basada en eventos (como actualizaciones regulatorias).
- Costes crecientes de I+D – Las tecnologías dispares y los sistemas desconectados crean ineficiencias operativas y mayores costos de licencias y mantenimiento.
- Panorama inconsistente para utilizar ML por completo – La partida de una casa de datos unificada y flujos de trabajo MLOps estandarizados e independientes del dominio significa que la innovación en datos y prospección es a menudo a propósito y no repetible. Los equipos carecen de una forma simplificada de progresar patrones exitosos, lo que resulta en esfuerzos redundantes, ciclos de progreso más largos y oportunidades perdidas de sinergia entre dominios.
- Arquitecturas desconectadas – Las soluciones de software no están integradas en el ecosistema unificado más amplio, lo que genera silos, redundancias e ineficiencias.
Al rebuscar estos desafíos sistémicos, Bayer se embarcó en un alucinación transformador. DSE no es solo una decisión tecnológica, sino una reinvención estratégica de cómo se podrían utilizar los datos y prospección de investigación en una ordenamiento total. Al reunir tecnologías de vanguardia, marcos estandarizados, una red de datos colaborativa y una casa tipo pantano, Bayer se propuso ayudar a los investigadores e ingenieros a acelerar la innovación farmacéutica.
Encontrar una decisión con la próxima concepción de SageMaker
Bayer imaginó un ecosistema de ciencia de datos unificado que proporcionaría lo venidero:
- Una experiencia de progreso colaborativo unificada para todos los científicos de datos, independientemente de su ubicación o especialización.
- Paso consumado a datos estructurados y no estructurados a través de una interfaz consistente
- Controles integrados de gobernanza y cumplimiento apropiados para la investigación farmacéutica
- Fortuna informáticos escalables para manejar las cargas de trabajo analíticas más complejas
Bayer realizó una evaluación exhaustiva de varias soluciones antaño de decidir la próxima concepción de SageMaker como piedra angular de su nuevo ecosistema de ciencia de datos. Aunque otras opciones tenían ventajas, Bayer priorizó las siguientes capacidades:
- Paso a datos multimodales – Esencial para la investigación en genómica, proteómica y biomarcadores avanzados.
- Mercado de activos centralizado – Centro central para descubrir y reutilizar datos, características, modelos y otros activos empresariales.
- Ecosistema de herramientas integrado – Paso optimizado a herramientas secreto como Git, ETL, MLflow y creadores de aplicaciones de IA generativa en un solo espacio
- Soporte multidominio y entre regiones – Fundamental para la colaboración mundial en investigación
- Precio-rendimiento – Necesario para un escalamiento sostenible a extenso plazo
Las capacidades de Estudio unificado de Amazon SageMaker y Catálogo de Amazon SageMaker formado con la visión de Bayer de ejecución de malla descentralizada combinada con descubrimiento y gobernanza centralizados. Permitieron a los equipos trabajar con sus herramientas preferidas, como Jupyter Notebooks o creadores de flujos de trabajo, manteniendo al mismo tiempo la capacidad de descubrimiento y reutilización de los activos.
Descripción genérico de la decisión
Esta sección describe las características secreto y la casa del DSE de Bayer basado en SageMaker. La decisión DSE aborda los desafíos identificados a través de una casa de múltiples capas:
- Rompiendo silos de datos – Las capacidades de ingesta de datos multimodales de la decisión rompen los silos de datos al permitir el almacenamiento unificado y el procesamiento de datos estructurados, semiestructurados y no estructurados a través de procesos por lotes, streaming y basados en eventos.
- Manejo de diversas modalidades de datos. – Un híbrido casa de la casa del pantanoconstruido sobre Servicio de almacenamiento simple de Amazon (Amazon S3)Apache Iceberg y Desplazamiento al rojo del Amazonasproporciona una colchoneta flexible para manejar diversas modalidades y vencimientos de datos, al tiempo que proporciona coherencia y accesibilidad a los datos.
- Aminorar costes mediante la estandarización – Para encarar los crecientes costos de I+D y las ineficiencias operativas, los bancos de trabajo analíticos precableados ofrecen plantillas estandarizadas y entornos de progreso integrados (IDE) que reducen la exceso y aceleran el progreso del flujo de trabajo.
- Desbloqueo de AI/ML con Amazon SageMaker AI y Amazon Bedrock – Capacidades avanzadas de IA/ML, impulsadas por Amazon SageMaker IA y Roca Amazónicacree un entorno MLOps estandarizado e independiente del dominio que permita innovación repetible y sinergia entre dominios.
- Gobierno del ecosistema de herramientas con observabilidad de extremo a extremo – Las sólidas funciones de gobernanza y observabilidad brindan cumplimiento y confiabilidad del sistema al tiempo que integran herramientas previamente desconectadas en un ecosistema unificado y aceptablemente monitoreado que rompe los silos arquitectónicos y promueve la utilización valioso de los medios.
La casa DSE implementa principios de malla de datos donde los dominios de datos (ómicos, regulatorios, ensayos clínicos) se tratan como productos, con responsabilidades de propiedad y trámite asignadas a expertos en el dominio. Estos dominios están descentralizados para su ejecución, pero siguen siendo detectables y reutilizables a través de SageMaker Catalog. En el centro de la casa se encuentra una casa de pantano de malla híbrida que combina Amazon S3 e Iceberg, lo que brinda la flexibilidad para manejar datos estructurados y no estructurados de forma valioso. SageMaker Unified Studio proporciona una capa analítica donde los investigadores pueden entrar al conjunto completo de herramientas necesarias para su trabajo. El venidero diagrama ilustra esta casa.
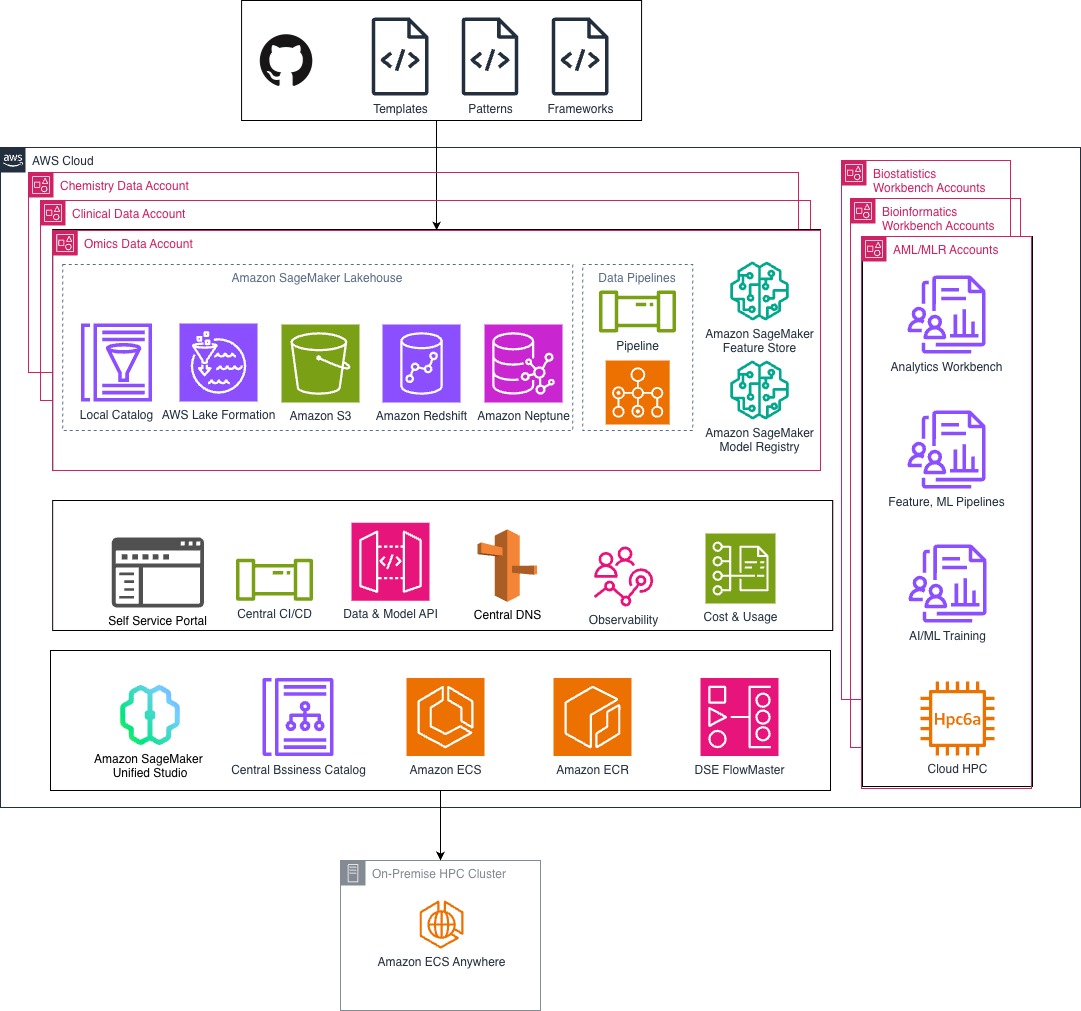
Impacto
La primera etapa del DSE de Bayer confirmó la próxima concepción de SageMaker como una colchoneta poderosa para su DSE de I+D, diseñado para equilibrar la innovación descentralizada con la gobernanza centralizada a través de una casa de malla de datos escalable. Con esta decisión, Bayer puede catalogar y mandar activos de datos multimodales, incluidos datos estructurados y no estructurados, funciones de estudios inconsciente, modelos y activos científicos personalizados, con metadatos ricos en contexto en diversos dominios de I+D farmacéutico. Bayer ahora está posicionado para incorporar más de 300 TB de datos de biomarcadores e integrar repositorios de datos ómicos, clínicos y químicos aislados en un entorno cohesivo. Con herramientas integradas como JupyterLab Spaces, MLflow y SageMaker AI Studio, la plataforma DSE está sentando las bases para un faja de trabajo de estudios inconsciente integral y compatible con GxP, allanando el camino para poner en funcionamiento más de 25 casos de uso de estudios inconsciente de stop valencia y respaldar a más de 100 científicos de datos en toda la ordenamiento.
«El ecosistema de ciencia de datos es dinámico para desarrollar nuestros medicamentos», afirma Daniel Gusenleitner, líder de comisión del ecosistema de ciencia de datos de I+D. «Restablecimiento nuestros flujos de trabajo comerciales con prospección avanzados, ayudándonos a acelerar la búsqueda de nuevos tratamientos. Al integrar datos de todo el proceso de investigación y progreso, mejoramos las posibilidades de éxito técnico y garantizamos que nuestros esfuerzos sean eficientes. Desbloquear nuestros datos igualmente facilita el descubrimiento de objetivos, lo que conduce a avances innovadores en la atención al paciente».
Próximos pasos
Bayer ha iniciado con éxito su ecosistema de ciencia de datos en la próxima concepción de Amazon SageMaker y está trabajando para incorporar el primer caso de uso de investigación vanguardia de biomarcadores. Basándose en una colchoneta sólida, Bayer igualmente está acelerando la progreso de la decisión DSE con las siguientes mejoras secreto:
- Catálogos federados e integración entre dominios – Permitir la búsqueda y reutilización de activos de datos en áreas terapéuticas y unidades de negocio.
- Ontología vanguardia y capa semántica. – Enriquecer los metadatos con conocimiento del dominio para respaldar la búsqueda, el descubrimiento y el razonamiento basados en IA.
- Apadrinamiento de flujos de trabajo de IA generativos y agentes – Impulsar el descubrimiento de nuevos fármacos y acelerar la concepción de hipótesis.
Conclusión
Al emplear la próxima concepción de Amazon SageMaker para construir su ecosistema de ciencia de datos basado en la cúmulo, Bayer está creando una colchoneta para una investigación y un descubrimiento más rápidos y eficientes. Amazon SageMaker está unificando diversos tipos de datos, permitiendo la colaboración total y estandarizando los flujos de trabajo de estudios inconsciente para ayudar a posicionar a Bayer a la vanguardia de la innovación basada en datos.
Para obtener más información y comenzar con la próxima concepción de SageMaker, consulte Amazon SageMaker o el Consola de AWS.
Acerca de los autores