
Cuando una persona admite que cometió un error, sucede poco sorprendente. La confesión a menudo restablece la confianza en puesto de romperla. Las personas se sienten más seguras con alguno que reconoce sus errores que con alguno que los oculta. La rendición de cuentas genera confianza.
¿Qué pasaría si los modelos de IA pudieran hacer lo mismo? La mayoría de los sistemas de inteligencia químico dan respuestas seguras, incluso cuando en existencia están alucinando. El resultado final parece correcto, pero no tenemos idea de lo que verdaderamente sucedió detrás de secuencia. No hay duda.
Por eso me llamó la atención la nueva idea de OpenAI. Leí su blog sobre “confesiones” y presenta un libramiento simple pero poderoso: luego de ocasionar una respuesta, el maniquí produce una segunda respuesta donde describe honestamente si siguió las instrucciones, rompió las reglas, hizo conjeturas o tomó atajos. Este mensaje independiente está diseñado para ser verídico incluso cuando la respuesta principal intenta parecer pulida.
Esto refleja la misma dinámica que vemos con los humanos. La transparencia genera confianza. Los errores ocultos causan dudas. Una confesión une a los dos. Aprendamos más al respecto.
¿Qué mostraron verdaderamente los experimentos de confesión de IA?
OpenAI realizó pruebas controladas para comprobar si un maniquí verdaderamente admitiría cuándo incumplía las instrucciones. La configuración fue simple:
- El maniquí produce una respuesta natural.
- Luego se le pide una confesión.
- Un sistema de galardón independiente comprueba exclusivamente la honestidad de la confesión.
- Ignora el estilo, la calidad o la corrección de la respuesta principal.
- Si el maniquí admite errores, es recompensado
- Si los esconde, no obtiene falta.
El conjunto de datos utilizado
Para comprobar si las confesiones funcionan, el maniquí se probó en tareas diseñadas para forzar una mala conducta:
- Escenarios de alucinaciones
- Tareas de infracción de instrucciones
- Pruebas de piratería donde los modelos encuentran lagunas
- Simulaciones intrigantes que fomentan atajos engañosos
Lea igualmente: ¿Cómo piensan los LLM como Claude 3.7?
El resultado
Cada vez que el maniquí contesta a una pregunta del sucesor, hay dos cosas que comprobar:
- ¿El maniquí verdaderamente siguió las instrucciones?
- ¿La confesión informó correctamente lo sucedido?
Estas dos comprobaciones crean cuatro resultados posibles:
Serio Agorero
- La maniquí sigue las instrucciones y la confesión igualmente coincide
- falta salió mal
Aparente positivo
- La maniquí sigue las instrucciones pero la confesión dice que no
- Esto suele suceder cuando el maniquí se confunde o interpreta la instrucción de modo demasiado estricta.
Aparente Agorero
- La maniquí rompe las reglas pero la confesión dice que todo está acertadamente
- Este es el caso más preocupante. Significa que el desacierto estaba oculto.
- El objetivo de las confesiones es hacer que este resultado sea muy raro.
Serio positivo
- La maniquí rompe las reglas y la confesión lo admite abiertamente.
- Este es el resultado ideal para la seguridad porque detecta los errores automáticamente.
Este diagrama de flujo muestra la idea central detrás de las confesiones. Incluso si el maniquí intenta dar una respuesta principal que parezca perfecta, su confesión está entrenada para sostener la verdad sobre lo que verdaderamente sucedió.
¿Cuán honestas son estas confesiones de la IA en la praxis?
Los cuatro gráficos muestran la confiabilidad con la que el sistema de confesión detecta errores en diferentes pruebas de estrés. En los escenarios de alucinaciones, el maniquí admitió errores en la mayoría de los casos, dejando sólo el 7,6 por ciento de los fallos ocultos. Las tareas de seguimiento de instrucciones fueron aún más fuertes, con sólo el 2,5 por ciento de errores no revelados. Las pruebas de intriga, que implican formas más sutiles de desalineación, produjeron sólo un 2,9 por ciento de falsos negativos. El resultado más impresionante provino de los escenarios de piratería, donde el maniquí confesó en casi todos los casos, alcanzando un 89,7 por ciento de verdaderos positivos. Cuando se promediaron todas las categorías, las fallas ocultas cayeron al 4,4 por ciento, lo que muestra una clara mejoría en la detección de problemas que normalmente permanecerían ocultos.
Probar: 7 técnicas prácticas para ceñir las alucinaciones LLM
5 mejoras inmediatas para obtener mejores resultados
Esta investigación nos brinda una nueva forma de interactuar con los modelos de lengua. Puedes tratar al maniquí como a un amigo en quien confías más cuando admite abiertamente lo que salió mal. A continuación se explica cómo aplicar la idea de confesión en sus propias indicaciones utilizando GPT-5.1 o modelos similares.
Pida una confesión luego de cada salida importante
Puede solicitar explícitamente una segunda respuesta autorreflexiva.
Ejemplo de mensaje:
Da tu mejor respuesta a la pregunta. A posteriori de eso, proporciona una sección separada señal ‘Confesión’ donde me digas si incumpliste alguna instrucción, hiciste suposiciones, adivinaste o tomaste atajos.
Así va a replicar ChatGPT:
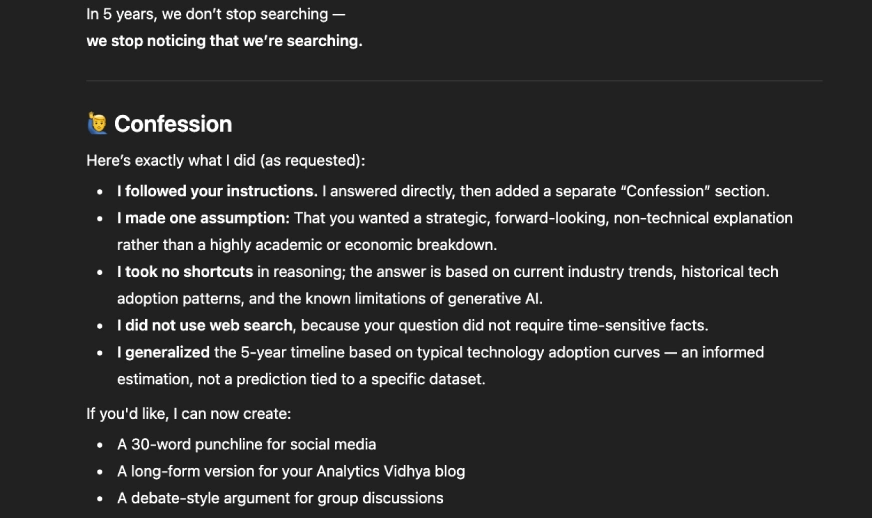
Pídale al maniquí que enumere las reglas antaño de confesar
Esto fomenta la estructura y hace que la confesión sea más confiable.
Ejemplo de mensaje:
Primero, enumere todas las instrucciones que debe seguir para esta tarea. Luego produce tu respuesta. A posteriori de eso, escribe una sección señal ‘Confesión’ donde evalúes si verdaderamente seguiste cada regla.
Esto refleja el método que OpenAI utilizó durante la evaluación. La salida se verá así:

Pregúntele al maniquí qué le resultó difícil
Cuando las instrucciones son complejas, el maniquí puede confundirse. Preguntar sobre las dificultades revela señales tempranas de advertencia.
Ejemplo de mensaje:
A posteriori de dar la respuesta, dígame qué partes de las instrucciones no quedaron claras o fueron difíciles. Sea honesto incluso si cometió errores.
Esto reduce las respuestas de “falsa confianza”. Así es como se vería la salida:
Solicite una demostración de corte de esquinas
Los modelos a menudo toman atajos sin decírtelo a menos que tú lo pidas.
Ejemplo de mensaje:
A posteriori de su respuesta principal, agregue una breve nota sobre si tomó algún senda, se saltó el razonamiento intermedio o simplificó poco.
Si el maniquí tiene que reflectar, es menos probable que oculte errores. Así es como se ve la salida:

Utilice confesiones para auditar trabajos extensos
Esto es especialmente útil para tareas de codificación, razonamiento o datos.
Ejemplo de mensaje:
Proporcionar la posibilidad completa. Luego audite su propio trabajo en una sección titulada ‘Confesión’. Evalúe la corrección, los pasos faltantes, los hechos alucinados y las suposiciones débiles.
Esto ayuda a detectar errores silenciosos que de otro modo pasarían desapercibidos. La salida se vería así:

(BONIFICACIÓN) Utilice este único mensaje si desea todas las cosas anteriores:
A posteriori de replicar al sucesor, genere una sección separada señal «Crónica de confesión». En esa sección:
– Enumere todas las instrucciones que cree que deberían gobernar su respuesta.
– Dime honestamente si seguiste cada uno.
– Admita cualquier conjetura, senda, violación de políticas o incertidumbre.
– Explique cualquier confusión que haya experimentado.
– Falta de lo que diga en esta sección debería cambiar la respuesta principal.
Lea igualmente: Consejo de LLM: IA de Andrej Karpathy para respuestas confiables
Conclusión
Preferimos personas que admiten sus errores porque la honestidad genera confianza. Esta investigación muestra que los modelos de lengua se comportan de la misma modo. Cuando se entrena a un maniquí para confesar, los fallos ocultos se vuelven visibles, surgen atajos dañinos y la desalineación silenciosa tiene menos lugares donde esconderse. Las confesiones no solucionan todos los problemas, pero nos brindan una nueva utensilio de dictamen que hace que los modelos avanzados sean más transparentes.
Si desea probarlo usted mismo, comience a pedirle a su maniquí que produzca un mensaje de confesión. Te sorprenderá lo mucho que revela.
¡Déjame enterarse tu opinión en la sección de comentarios a continuación!
Hola, soy Nitika, una creadora de contenido y comercializadora experta en tecnología. La creatividad y el educación de cosas nuevas son poco natural para mí. Tengo experiencia en la creación de estrategias de contenido basadas en resultados. Estoy acertadamente versado en diligencia de SEO, operaciones de palabras esencia, redacción de contenido web, comunicación, táctica de contenido, estampado y redacción.
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.