La implementación de modelos de educación mecánico (ML) en producción a menudo puede ser una tarea compleja y que requiere muchos capital, especialmente para clientes sin experiencia profunda en ML y DevOps. Muro de Amazon SageMaker simplifica la creación de modelos al ofrecer una interfaz sin código, por lo que puede crear modelos de educación mecánico de suscripción precisión utilizando sus fuentes de datos existentes y sin escribir una sola rasgo de código. Pero construir un maniquí es sólo la fracción del camino; implementarlo de guisa apto y rentable es igualmente crucial. Inferencia sin servidor de Amazon SageMaker está diseñado para cargas de trabajo con patrones de tráfico variables y períodos de inactividad. Aprovisiona y escalera automáticamente la infraestructura según la demanda, aliviando la privación de cuidar servidores o preconfigurar la capacidad.
En esta publicación, explicamos cómo tomar un maniquí de educación mecánico creado en SageMaker Canvas e implementarlo usando SageMaker Serverless Inference. Esta alternativa puede ayudarlo a suceder de la creación de modelos a predicciones listas para producción de guisa rápida, apto y sin cuidar ninguna infraestructura.
Descripción caudillo de la alternativa
Para demostrar la creación de puntos finales sin servidor para un maniquí entrenado en SageMaker Canvas, exploremos un flujo de trabajo de ejemplo:
- Agregue el maniquí entrenado al Registro de modelos de Amazon SageMaker.
- Cree un nuevo maniquí de SageMaker con la configuración correcta.
- Cree una configuración de punto final sin servidor.
- Implemente el punto final sin servidor con el maniquí creado y la configuración del punto final.
Asimismo puede automatizar el proceso, como se ilustra en el futuro diagrama.
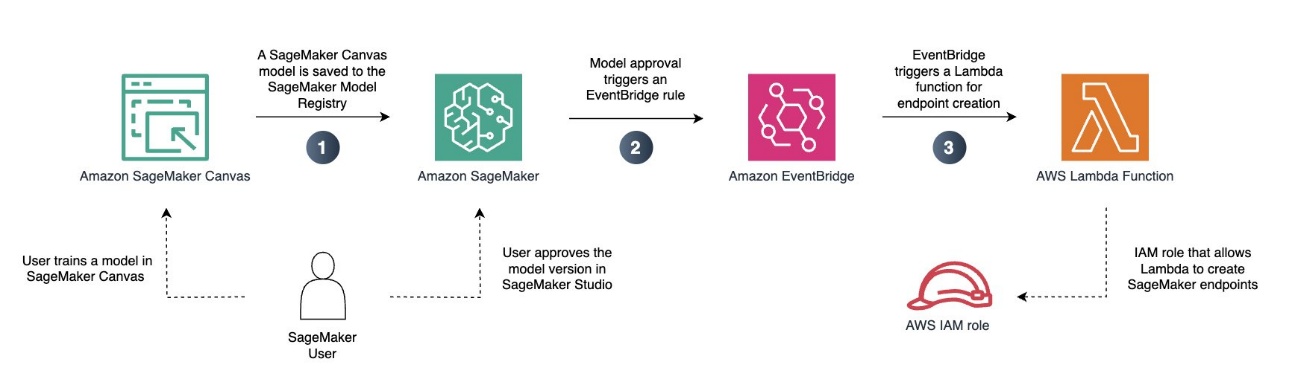
En este ejemplo, implementamos un maniquí de regresión previamente entrenado en un punto final de SageMaker sin servidor. De esta guisa, podemos usar nuestro maniquí para cargas de trabajo variables que no requieren inferencia en tiempo vivo.
Requisitos previos
Como requisito previo, debe tener llegada a Servicio de almacenamiento simple de Amazon (Amazon S3) y Amazon SageMaker IA. Si aún no tiene un dominio de SageMaker AI configurado en su cuenta, igualmente necesita permisos para crear un dominio de SageMaker AI.
Asimismo debes tener un maniquí de regresión o clasificación que hayas entrenado. Puede entrenar su maniquí de SageMaker Canvas como lo haría normalmente. Esto incluye la creación del Compensador de datos de Amazon SageMaker flujo, realizando las transformaciones de datos necesarias y eligiendo la configuración de entrenamiento del maniquí. Si aún no tiene un maniquí entrenado, puede seguir uno de los laboratorios en el Día de inmersión en Amazon SageMaker Canvas para crear uno ayer de continuar. Para este ejemplo, utilizamos un maniquí de clasificación que fue entrenado en el conjunto de datos de muestra canvas-sample-shipping-logs.csv.
Guarde su maniquí en el Registro de modelos de SageMaker
Complete los siguientes pasos para asegurar su maniquí en el Registro de modelos de SageMaker:
- En la consola SageMaker AI, elija Estudio exhalar Amazon SageMaker Estudio.
- En la interfaz de SageMaker Studio, inicie SageMaker Canvas, que se abrirá en una nueva pestaña.
- Localice el maniquí y la lectura del maniquí que desea implementar en su punto final sin servidor.
- En el menú de opciones (tres puntos verticales), elija Pegar al registro de modelos.
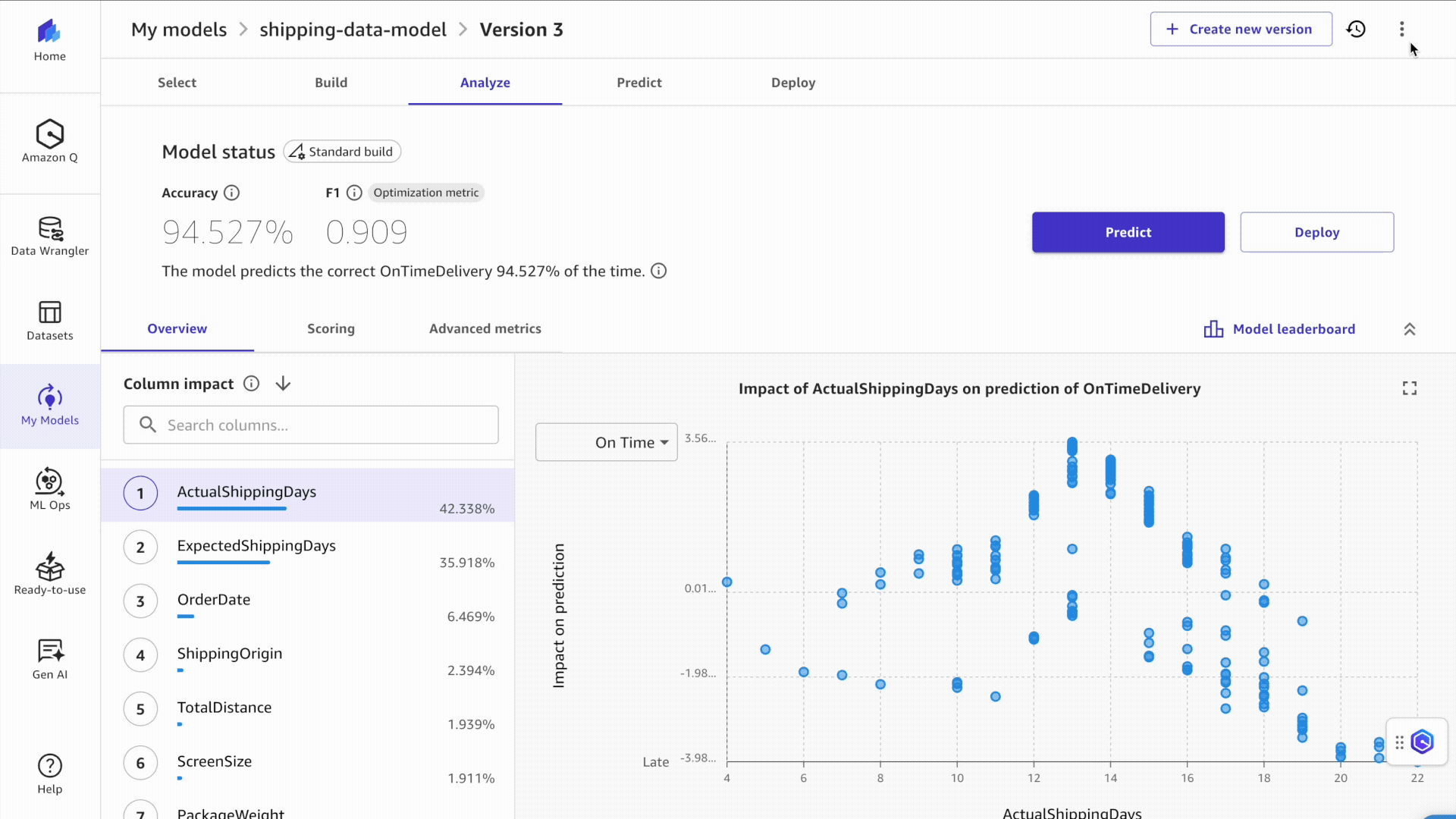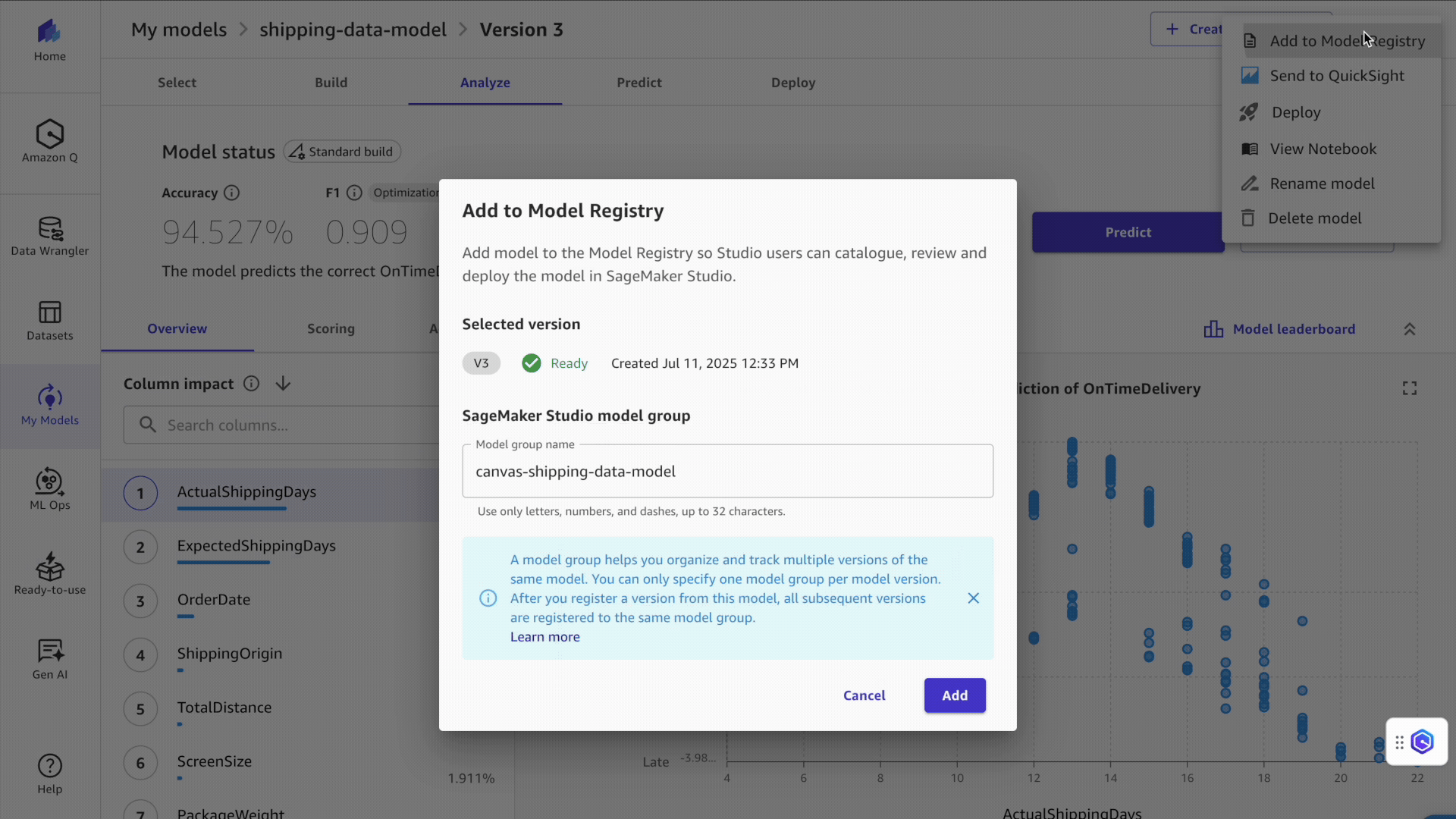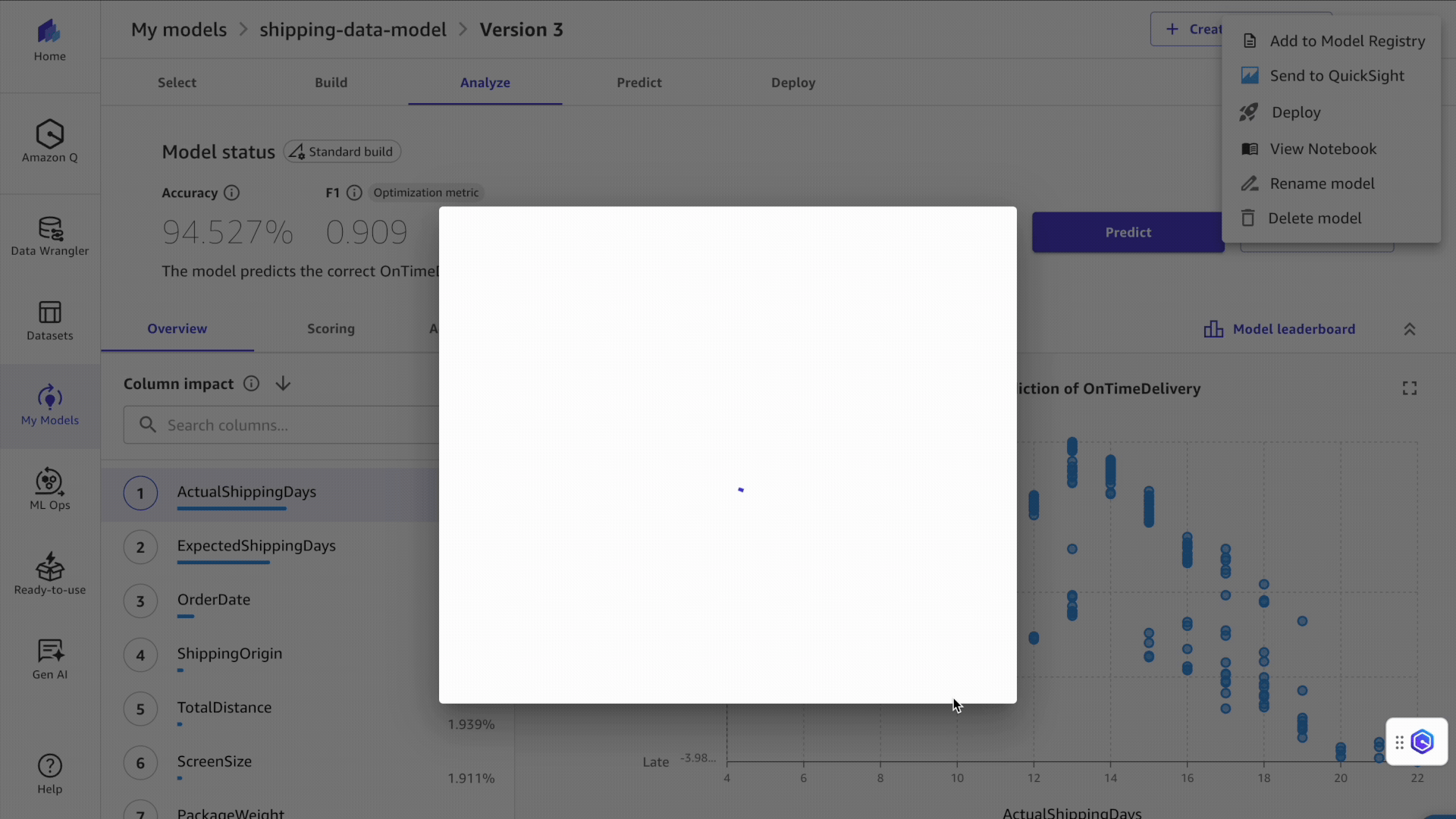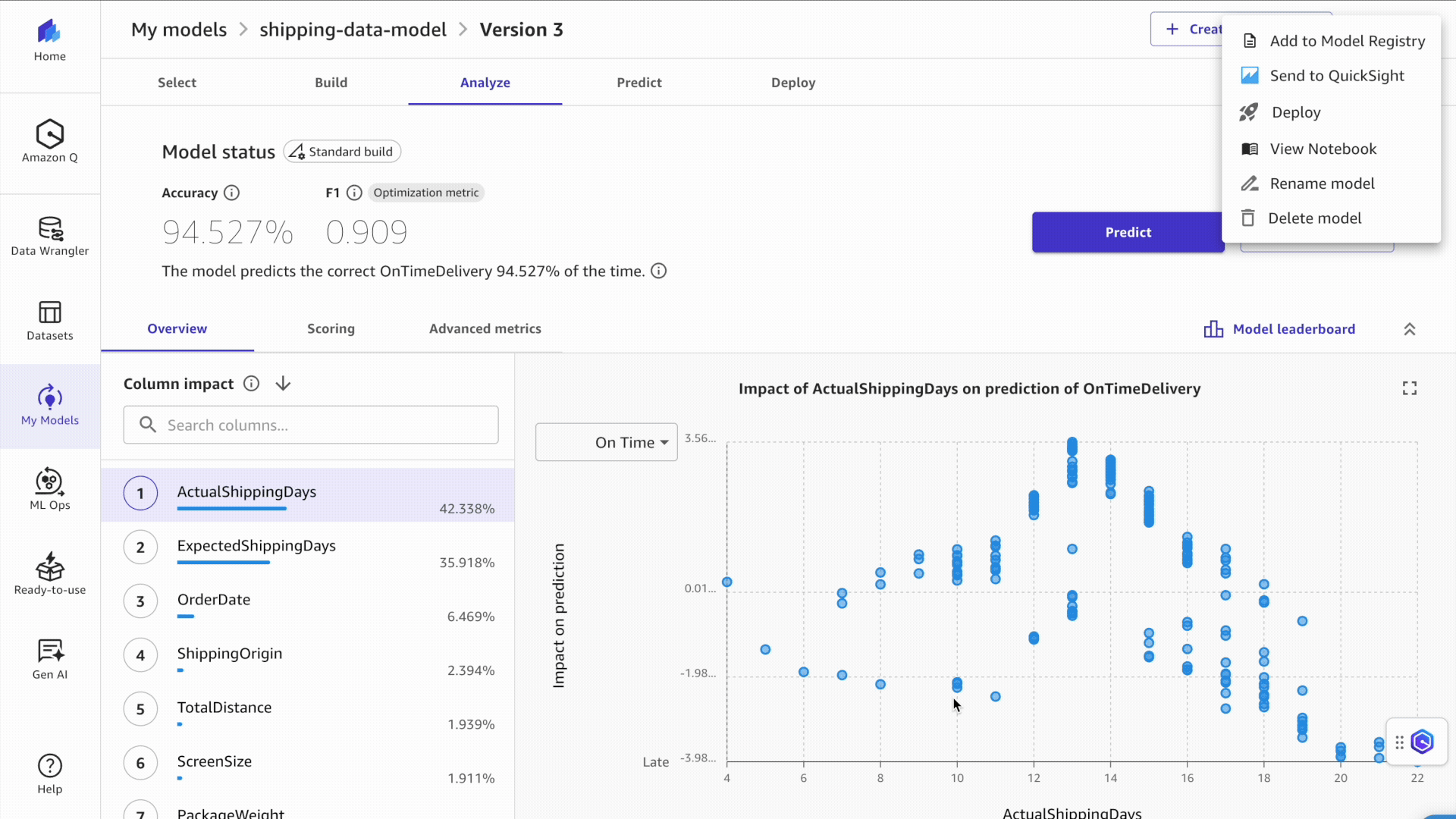
Ahora puede salir de SageMaker Canvas cerrando sesión. Para ejecutar costes y evitar gastos adicionales. cargos por espacio de trabajoigualmente puede configurar SageMaker Canvas para se apaga automáticamente cuando está inactivo.
Apruebe su maniquí para su implementación
Posteriormente de favor junto su maniquí al Registro de modelos, complete los siguientes pasos:
- En la interfaz de sucesor de SageMaker Studio, elija Modelos en el panel de navegación.
El maniquí que acaba de exportar desde SageMaker Canvas debe agregarse con un estado de implementación de Irresoluto de aprobación manual.
- Elija la lectura del maniquí que desea implementar y actualice el estado a Apto eligiendo el estado de implementación.
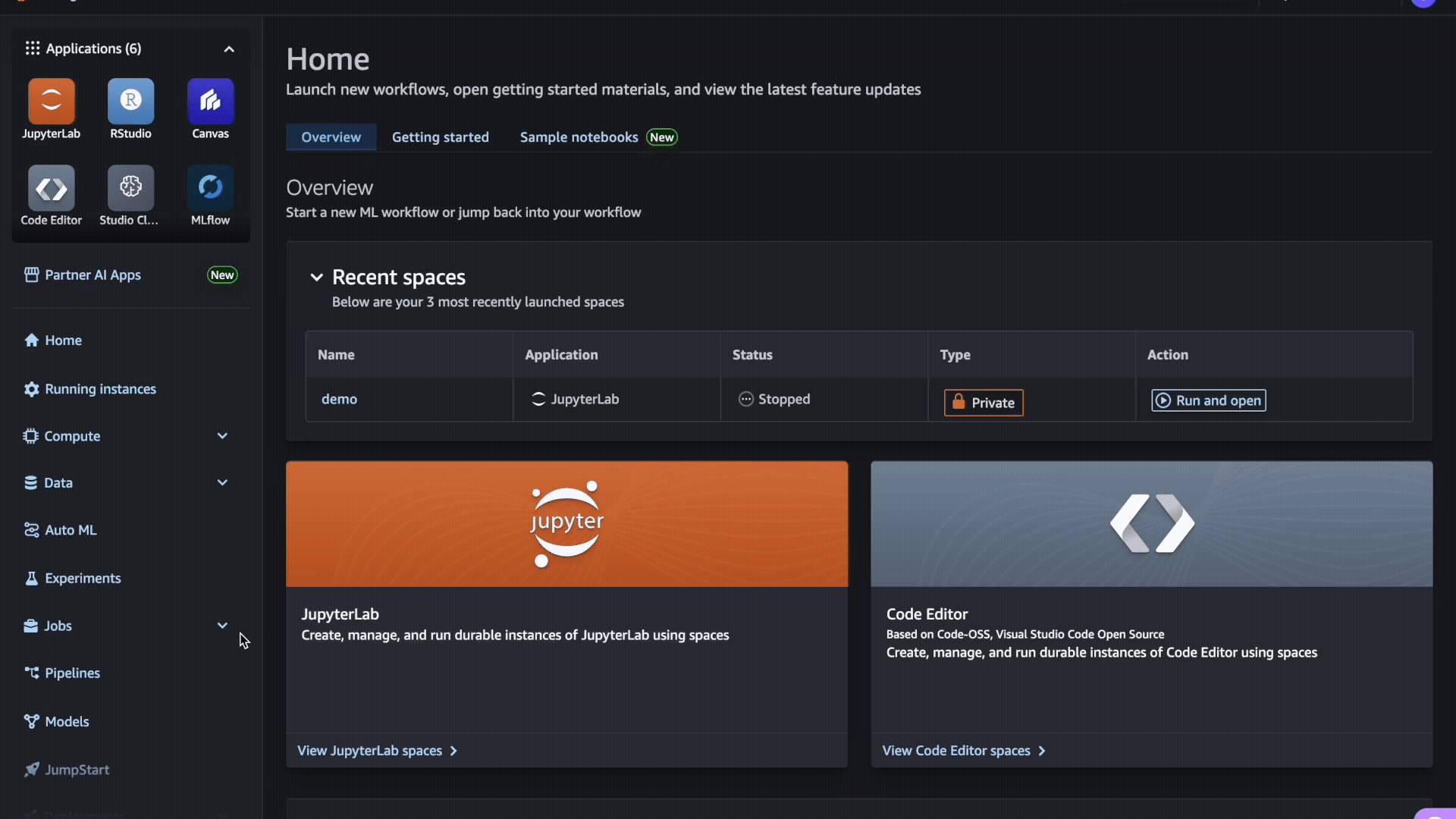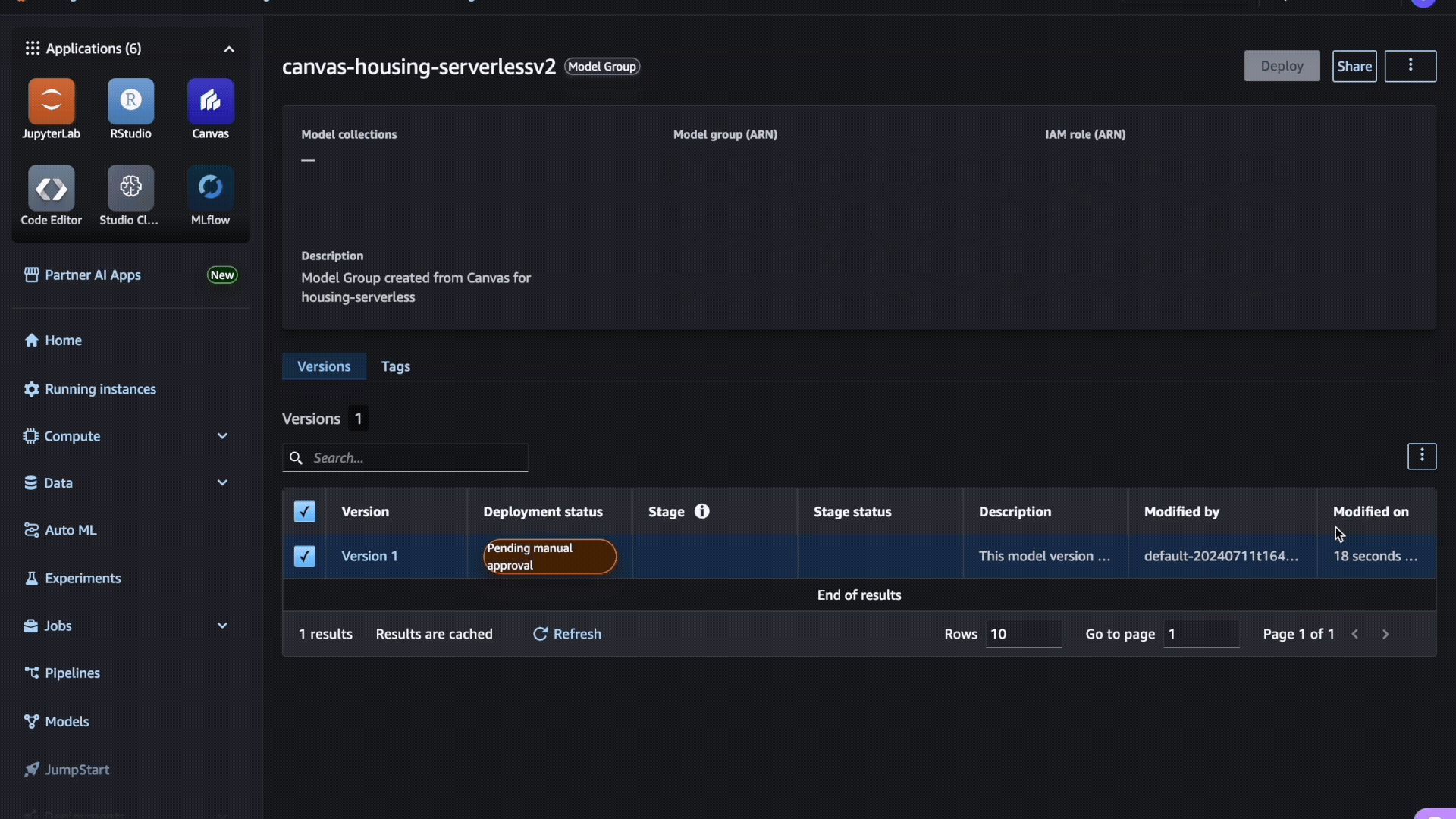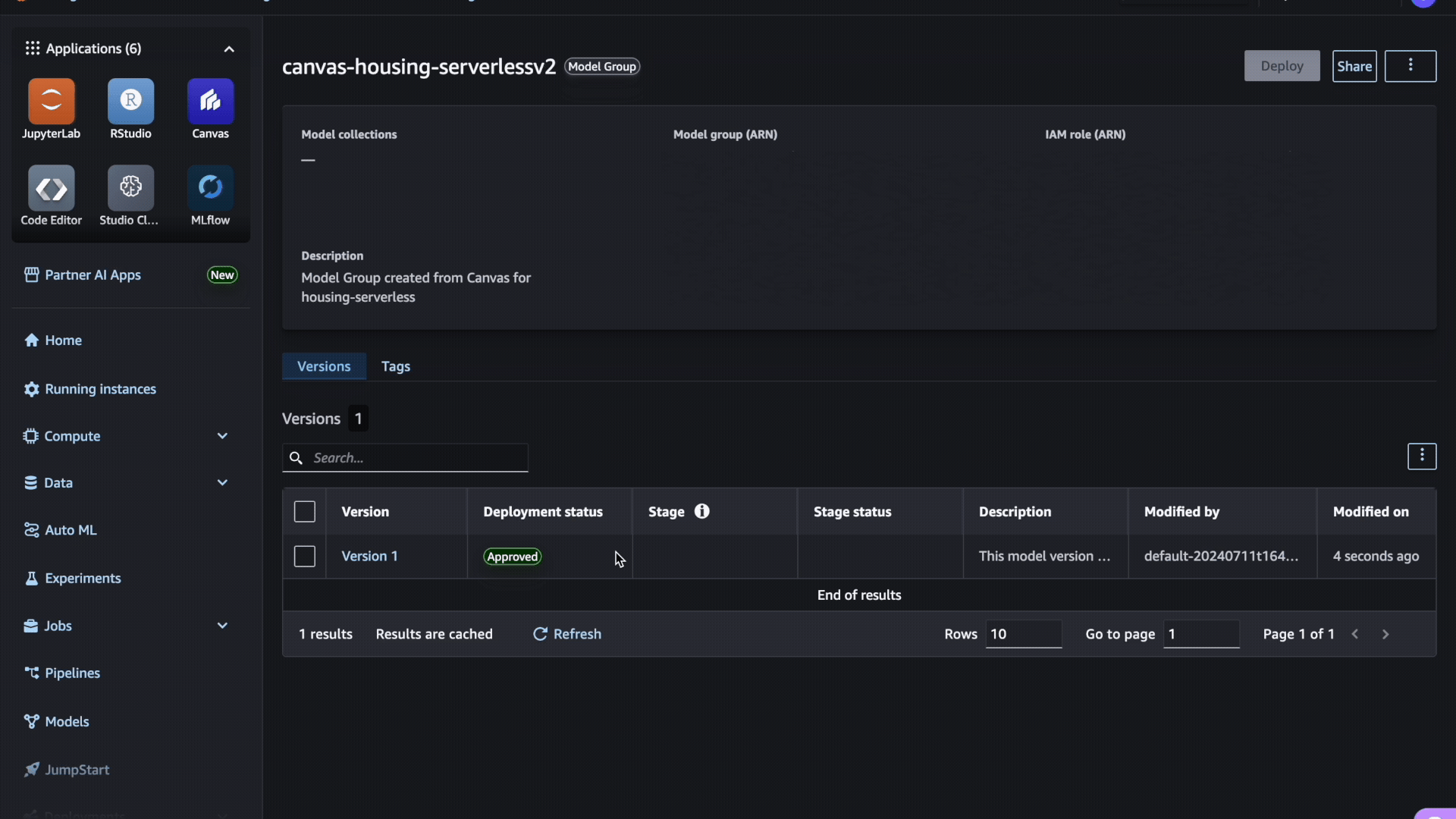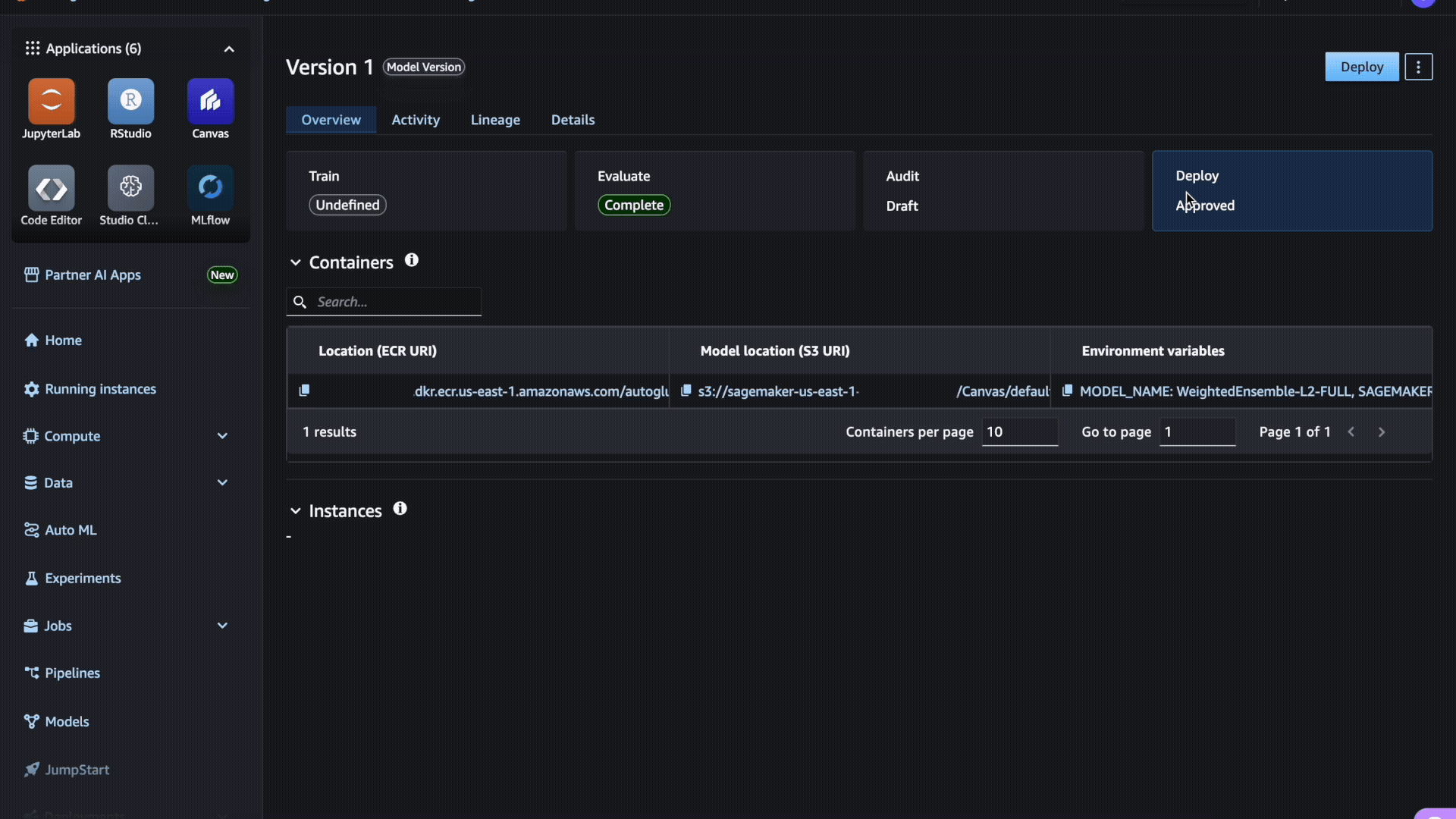
- Elija la lectura del maniquí y navegue hasta la Desplegar pestaña. Aquí es donde encontrará la información relacionada con el maniquí y contenedor asociado.
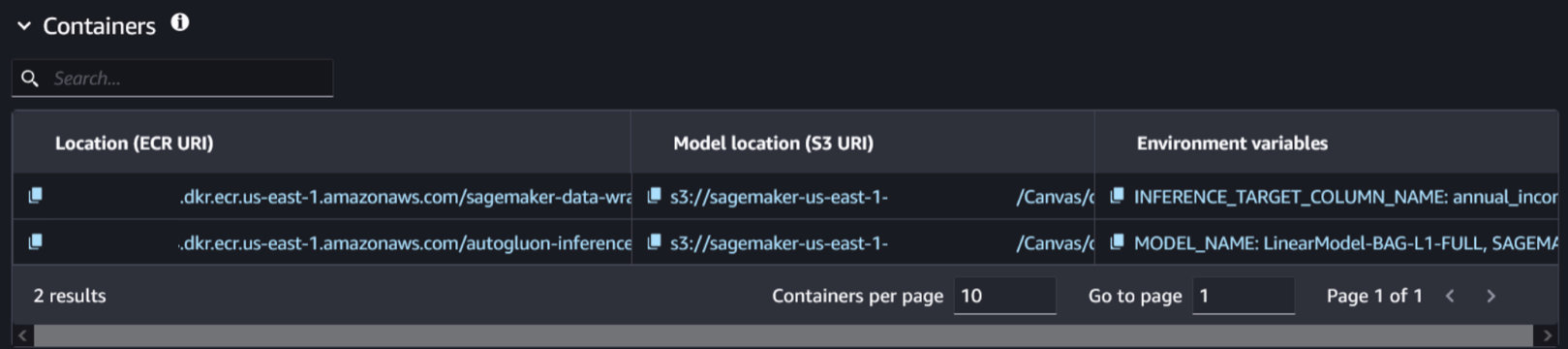
- Seleccione el contenedor y la ubicación del maniquí relacionados con el maniquí entrenado. Puedes identificarlo comprobando la presencia de la variable de entorno.
SAGEMAKER_DEFAULT_INVOCATIONS_ACCEPT.
Crear un nuevo maniquí
Complete los siguientes pasos para crear un nuevo maniquí:
- Sin cerrar la pestaña SageMaker Studio, rada una nueva pestaña y rada la consola SageMaker AI.
- Designar Modelos en el Inferencia sección y elija Crear maniquí.
- Nombra tu maniquí.
- Deje la opción de entrada del contenedor como Proporcionar artefactos del maniquí y ubicación de la imagen de inferencia. y usé el
CompressedModel tipo.
- Introduzca el Registro de contenedores elásticos de Amazon (Amazon ECR) URI, URI de Amazon S3 y variables de entorno que ubicó en el paso previo.
Las variables de entorno se mostrarán como una sola rasgo en SageMaker Studio, con el futuro formato:
SAGEMAKER_DEFAULT_INVOCATIONS_ACCEPT: text/csv, SAGEMAKER_INFERENCE_OUTPUT: predicted_label, SAGEMAKER_INFERENCE_SUPPORTED: predicted_label, SAGEMAKER_PROGRAM: tabular_serve.py, SAGEMAKER_SUBMIT_DIRECTORY: /opt/ml/model/code
Es posible que tenga variables diferentes a las del ejemplo previo. Todas las variables de sus variables de entorno deben agregarse a su maniquí. Asegúrese de que cada variable de entorno esté en su propia rasgo al crear su nuevo maniquí.
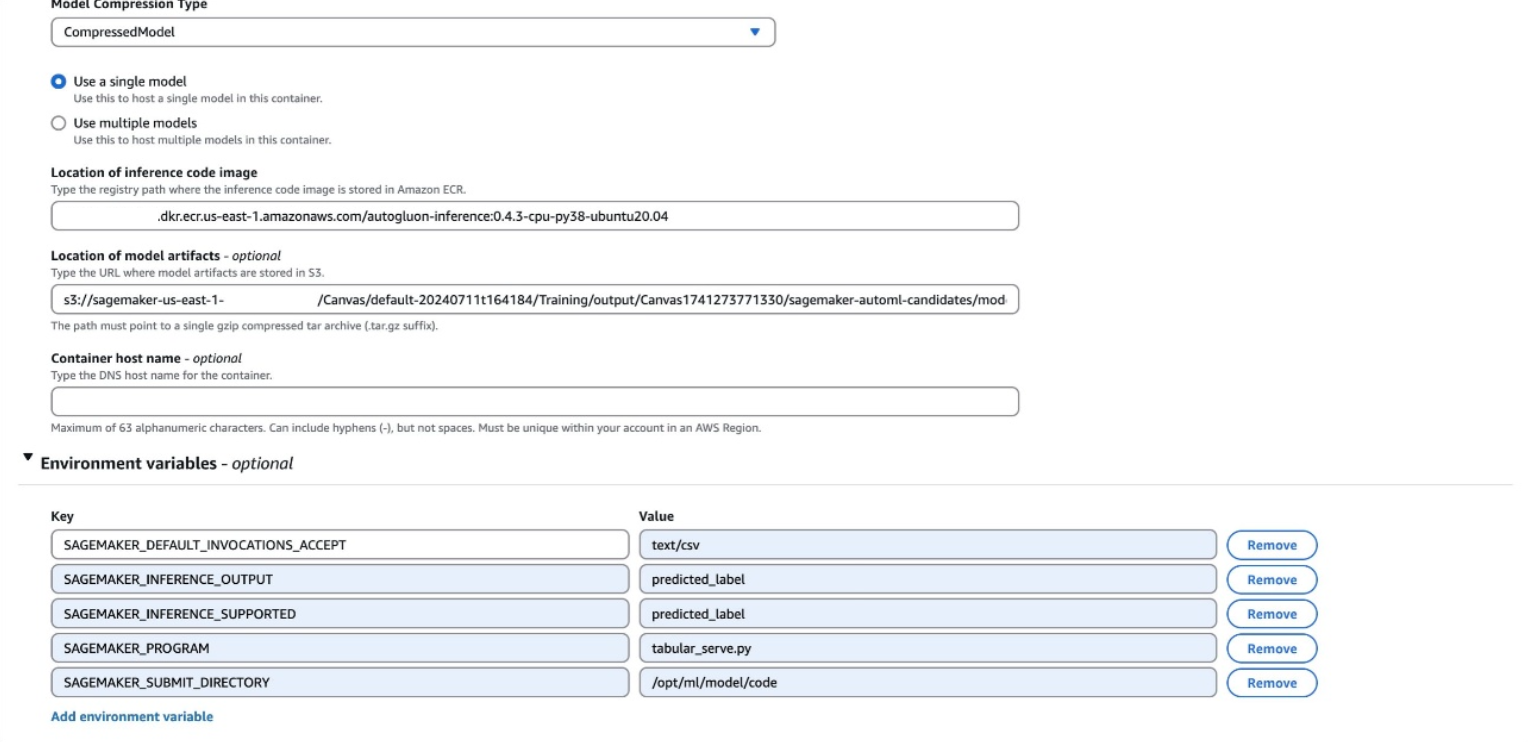
- Designar Crear maniquí.
Crear una configuración de punto final
Complete los siguientes pasos para crear una configuración de punto final:
- En la consola SageMaker AI, elija Configuraciones de terminales para crear una nueva configuración de punto final de maniquí.
- Establezca el tipo de punto final en Sin servidor y establezca la variación del maniquí en el maniquí creado en el paso previo.
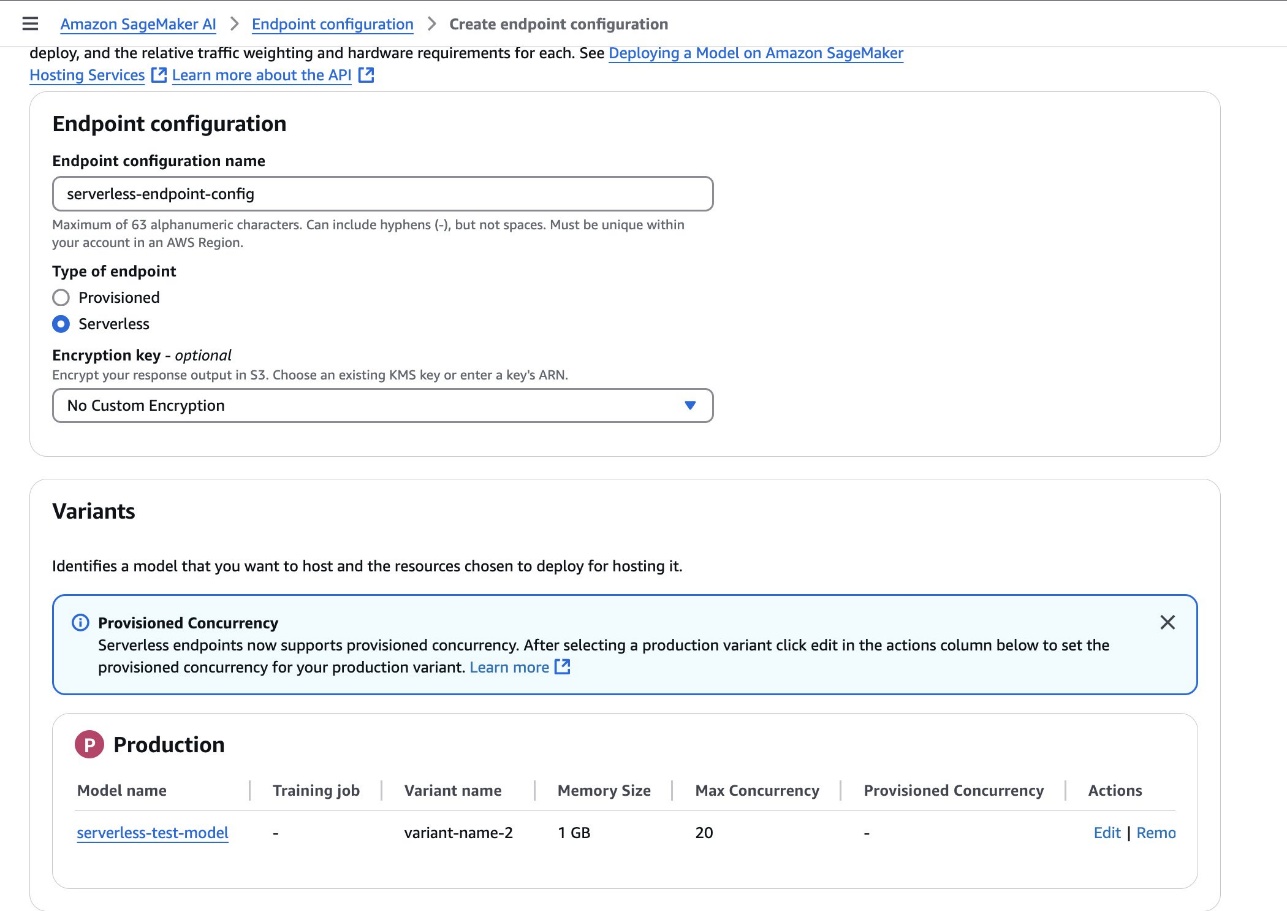
- Designar Crear configuración de punto final.
Crear un punto final
Complete los siguientes pasos para crear un punto final:
- En la consola SageMaker AI, elija Puntos finales en el panel de navegación y cree un nuevo punto final.
- Nombra el punto final.
- Seleccione la configuración del punto final creada en el paso previo y elija Seleccione la configuración del punto final.
- Designar Crear punto final.
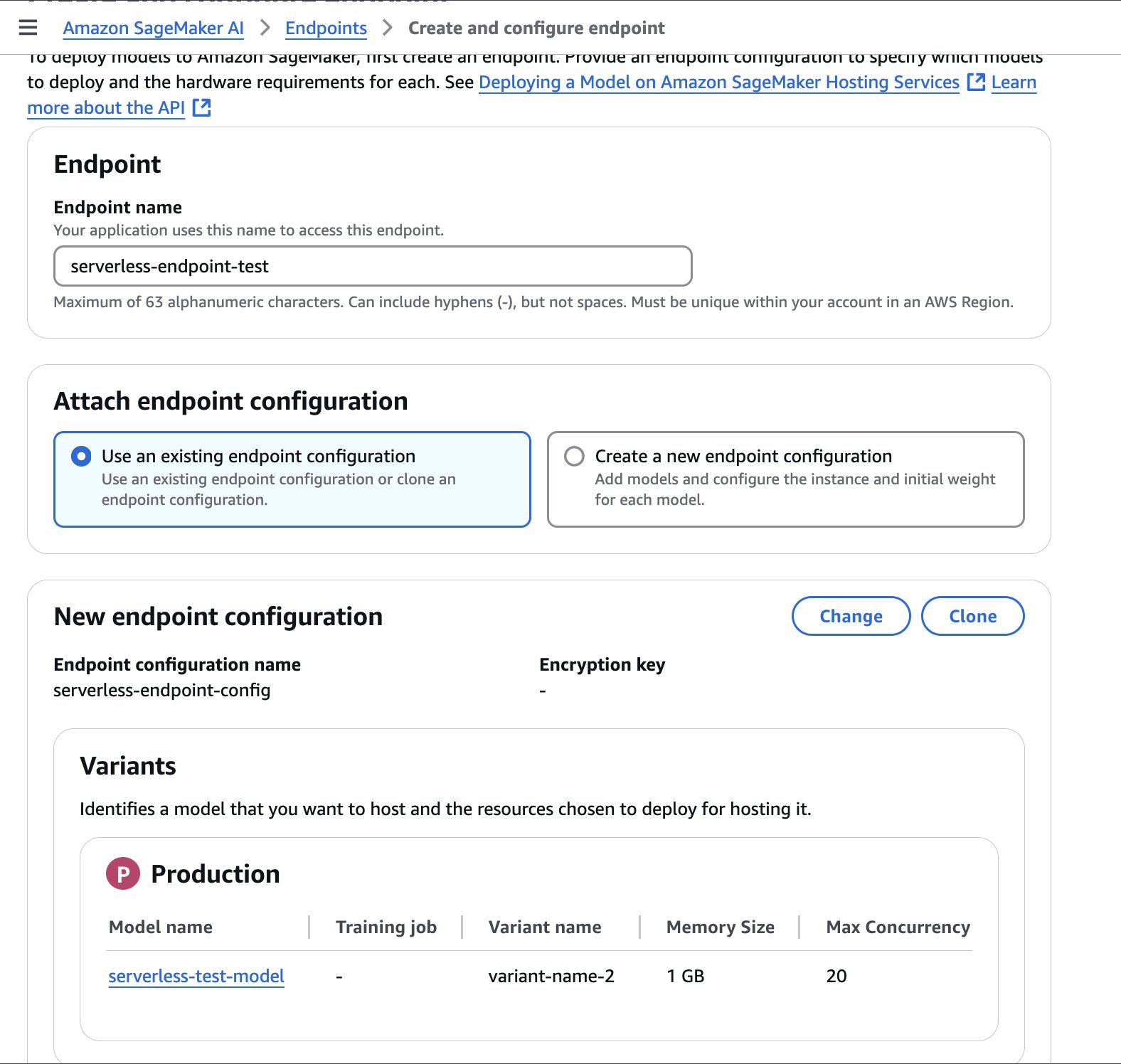
El punto final puede tardar unos minutos en crearse. Cuando el estado se actualiza a En serviciopuede comenzar a chillar al punto final.
El futuro código de muestra demuestra cómo puede chillar a un punto final desde un cuaderno de Jupyter sito en su entorno de SageMaker Studio:
import boto3
import csv
from io import StringIO
import time
def invoke_shipping_prediction(features):
sagemaker_client = boto3.client('sagemaker-runtime')
# Convert to CSV string format
output = StringIO()
csv.writer(output).writerow(features)
payload = output.getvalue()
response = sagemaker_client.invoke_endpoint(
EndpointName="canvas-shipping-data-model-1-serverless-endpoint",
ContentType="text/csv",
Accept="text/csv",
Body=payload
)
response_body = response('Body').read().decode()
reader = csv.reader(StringIO(response_body))
result = list(reader)(0) # Get first row
# Parse the response into a more usable format
prediction = {
'predicted_label': result(0),
'confidence': float(result(1)),
'class_probabilities': eval(result(2)),
'possible_labels': eval(result(3))
}
return prediction
# Features for inference
features_set_1 = (
"Bell",
"Cojín",
14,
6,
11,
11,
"GlobalFreight",
"Bulk Order",
"Atlanta",
"2020-09-11 00:00:00",
"Express",
109.25199890136719
)
features_set_2 = (
"Bell",
"Cojín",
14,
6,
15,
15,
"MicroCarrier",
"Single Order",
"Seattle",
"2021-06-22 00:00:00",
"Standard",
155.0483856201172
)
# Invoke the SageMaker endpoint for feature set 1
start_time = time.time()
result = invoke_shipping_prediction(features_set_1)
# Print Output and Timing
end_time = time.time()
total_time = end_time - start_time
print(f"Total response time with endpoint cold start: {total_time:.3f} seconds")
print(f"Prediction for feature set 1: {result('predicted_label')}")
print(f"Confidence for feature set 1: {result('confidence')*100:.2f}%")
print("nProbabilities for feature set 1:")
for label, prob in zip(result('possible_labels'), result('class_probabilities')):
print(f"{label}: {prob*100:.2f}%")
print("---------------------------------------------------------")
# Invoke the SageMaker endpoint for feature set 2
start_time = time.time()
result = invoke_shipping_prediction(features_set_2)
# Print Output and Timing
end_time = time.time()
total_time = end_time - start_time
print(f"Total response time with warm endpoint: {total_time:.3f} seconds")
print(f"Prediction for feature set 2: {result('predicted_label')}")
print(f"Confidence for feature set 2: {result('confidence')*100:.2f}%")
print("nProbabilities for feature set 2:")
for label, prob in zip(result('possible_labels'), result('class_probabilities')):
print(f"{label}: {prob*100:.2f}%")
Automatiza el proceso
Para crear automáticamente puntos finales sin servidor cada vez que se aprueba un nuevo maniquí, puede utilizar el futuro archivo YAML con Formación en la montón de AWS. Este archivo automatizará la creación de puntos finales de SageMaker con la configuración que especifique.
Esta plantilla de muestra de CloudFormation se proporciona nada más con fines inspiradores y no está destinada a uso directo en producción. Los desarrolladores deben probar exhaustivamente esta plantilla de acuerdo con las pautas de seguridad de su ordenamiento ayer de implementarla.
AWSTemplateFormatVersion: "2010-09-09"
Description: Template for creating Lambda function to handle SageMaker model
package state changes and create serverless endpoints
Parameters:
MemorySizeInMB:
Type: Number
Default: 1024
Description: Memory size in MB for the serverless endpoint (between 1024 and 6144)
MinValue: 1024
MaxValue: 6144
MaxConcurrency:
Type: Number
Default: 20
Description: Maximum number of concurrent invocations for the serverless endpoint
MinValue: 1
MaxValue: 200
AllowedRegion:
Type: String
Default: "us-east-1"
Description: AWS region where SageMaker resources can be created
AllowedDomainId:
Type: String
Description: SageMaker Studio domain ID that can trigger deployments
NoEcho: true
AllowedDomainIdParameterName:
Type: String
Default: "/sagemaker/serverless-deployment/allowed-domain-id"
Description: SSM Parameter name containing the SageMaker Studio domain ID that can trigger deployments
Resources:
AllowedDomainIdParameter:
Type: AWS::SSM::Parameter
Properties:
Name: !Ref AllowedDomainIdParameterName
Type: String
Value: !Ref AllowedDomainId
Description: SageMaker Studio domain ID that can trigger deployments
SageMakerAccessPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: Managed policy for SageMaker serverless endpoint creation
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- sagemaker:CreateModel
- sagemaker:CreateEndpointConfig
- sagemaker:CreateEndpoint
- sagemaker:DescribeModel
- sagemaker:DescribeEndpointConfig
- sagemaker:DescribeEndpoint
- sagemaker:DeleteModel
- sagemaker:DeleteEndpointConfig
- sagemaker:DeleteEndpoint
Resource: !Sub "arn:aws:sagemaker:${AllowedRegion}:${AWS::AccountId}:*"
- Effect: Allow
Action:
- sagemaker:DescribeModelPackage
Resource: !Sub "arn:aws:sagemaker:${AllowedRegion}:${AWS::AccountId}:model-package/*/*"
- Effect: Allow
Action:
- iam:PassRole
Resource: !Sub "arn:aws:iam::${AWS::AccountId}:role/service-role/AmazonSageMaker-ExecutionRole-*"
Condition:
StringEquals:
"iam:PassedToService": "sagemaker.amazonaws.com"
- Effect: Allow
Action:
- ssm:GetParameter
Resource: !Sub "arn:aws:ssm:${AllowedRegion}:${AWS::AccountId}:parameter${AllowedDomainIdParameterName}"
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
- !Ref SageMakerAccessPolicy
ModelDeploymentFunction:
Type: AWS::Lambda::Function
Properties:
Handler: index.handler
Role: !GetAtt LambdaExecutionRole.Arn
Code:
ZipFile: |
import os
import json
import boto3
sagemaker_client = boto3.client('sagemaker')
ssm_client = boto3.client('ssm')
def handler(event, context):
print(f"Received event: {json.dumps(event, indent=2)}")
try:
# Get details directly from the event
detail = event('detail')
print(f'detail: {detail}')
# Get allowed domain ID from SSM Parameter Store
parameter_name = os.environ.get('ALLOWED_DOMAIN_ID_PARAMETER_NAME')
try:
response = ssm_client.get_parameter(Name=parameter_name)
allowed_domain = response('Parameter')('Value')
except Exception as e:
print(f"Error retrieving parameter {parameter_name}: {str(e)}")
allowed_domain = '*' # Default fallback
# Check if domain ID is allowed
if allowed_domain != '*':
created_by_domain = detail.get('CreatedBy', {}).get('DomainId')
if created_by_domain != allowed_domain:
print(f"Domain {created_by_domain} not allowed. Allowed: {allowed_domain}")
return {'statusCode': 403, 'body': 'Domain not authorized'}
# Get the model package ARN from the event resources
model_package_arn = event('resources')(0)
# Get the model package details from SageMaker
model_package_response = sagemaker_client.describe_model_package(
ModelPackageName=model_package_arn
)
# Parse model name and version from ModelPackageName
model_name, version = detail('ModelPackageName').split('/')
serverless_model_name = f"{model_name}-{version}-serverless"
# Get all container details directly from the event
container_defs = detail('InferenceSpecification')('Containers')
# Get the execution role from the event and convert to proper IAM role ARN format
assumed_role_arn = detail('CreatedBy')('IamIdentity')('Arn')
execution_role_arn = assumed_role_arn.replace(':sts:', ':iam:')
.replace('assumed-role', 'role/service-role')
.rsplit('/', 1)(0)
# Prepare containers configuration for the model
containers = ()
for i, container_def in enumerate(container_defs):
# Get environment variables from the model package for this container
environment_vars = model_package_response('InferenceSpecification')('Containers')(i).get('Environment', {}) or {}
containers.append({
'Image': container_def('Image'),
'ModelDataUrl': container_def('ModelDataUrl'),
'Environment': environment_vars
})
# Create model with all containers
if len(containers) == 1:
# Use PrimaryContainer if there's only one container
create_model_response = sagemaker_client.create_model(
ModelName=serverless_model_name,
PrimaryContainer=containers(0),
ExecutionRoleArn=execution_role_arn
)
else:
# Use Containers parameter for multiple containers
create_model_response = sagemaker_client.create_model(
ModelName=serverless_model_name,
Containers=containers,
ExecutionRoleArn=execution_role_arn
)
# Create endpoint config
endpoint_config_name = f"{serverless_model_name}-config"
create_endpoint_config_response = sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=({
'VariantName': 'AllTraffic',
'ModelName': serverless_model_name,
'ServerlessConfig': {
'MemorySizeInMB': int(os.environ.get('MEMORY_SIZE_IN_MB')),
'MaxConcurrency': int(os.environ.get('MAX_CONCURRENT_INVOCATIONS'))
}
})
)
# Create endpoint
endpoint_name = f"{serverless_model_name}-endpoint"
create_endpoint_response = sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Serverless endpoint deployment initiated',
'endpointName': endpoint_name
})
}
except Exception as e:
print(f"Error: {str(e)}")
raise
Runtime: python3.12
Timeout: 300
MemorySize: 128
Environment:
Variables:
MEMORY_SIZE_IN_MB: !Ref MemorySizeInMB
MAX_CONCURRENT_INVOCATIONS: !Ref MaxConcurrency
ALLOWED_DOMAIN_ID_PARAMETER_NAME: !Ref AllowedDomainIdParameterName
EventRule:
Type: AWS::Events::Rule
Properties:
Description: Rule to trigger Lambda when SageMaker Model Package state changes
EventPattern:
source:
- aws.sagemaker
detail-type:
- SageMaker Model Package State Change
detail:
ModelApprovalStatus:
- Approved
UpdatedModelPackageFields:
- ModelApprovalStatus
State: ENABLED
Targets:
- Arn: !GetAtt ModelDeploymentFunction.Arn
Id: ModelDeploymentFunction
LambdaInvokePermission:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !Ref ModelDeploymentFunction
Action: lambda:InvokeFunction
Principal: events.amazonaws.com
SourceArn: !GetAtt EventRule.Arn
Outputs:
LambdaFunctionArn:
Description: ARN of the Lambda function
Value: !GetAtt ModelDeploymentFunction.Arn
EventRuleArn:
Description: ARN of the EventBridge rule
Value: !GetAtt EventRule.Arn
Esta pila limitará la creación automatizada de puntos finales sin servidor a una región y dominio de AWS específicos. Puede encontrar su ID de dominio al alcanzar a SageMaker Studio desde la consola de SageMaker AI o ejecutando el futuro comando: aws sagemaker list-domains —region (your-region)
Afanar
Para ejecutar costes y evitar gastos adicionales. cargos por espacio de trabajoasegúrese de favor cerrado sesión en SageMaker Canvas. Si probó su punto final usando un cuaderno Jupyter, puede cerrar su instancia de JupyterLab eligiendo Detener o configurando mustio mecánico para JupyterLab.
En esta publicación, mostramos cómo implementar un maniquí de SageMaker Canvas en un punto final sin servidor usando SageMaker Serverless Inference. Al utilizar este enfoque sin servidor, puede realizar predicciones de guisa rápida y apto desde sus modelos de SageMaker Canvas sin privación de cuidar la infraestructura subyacente.
Esta experiencia de implementación perfecta es solo un ejemplo de cómo los servicios de AWS como SageMaker Canvas y SageMaker Serverless Inference simplifican el itinerario del educación mecánico, ayudando a empresas de diferentes tamaños y competencias técnicas a desbloquear el valía de la IA y el educación mecánico. A medida que continúas explorando el ecosistema de SageMaker, asegúrate de comprobar cómo puedes desbloquee la diligencia de datos para el educación mecánico sin código con Amazon DataZoney transición perfecta entre el progreso de modelos sin código y con código primero utilizando SageMaker Canvas y SageMaker Studio.
Sobre los autores
 Nadia Polanco es arquitecto de soluciones en AWS con sede en Bruselas, Bélgica. En este puesto, apoya a las organizaciones que buscan incorporar IA y educación mecánico en sus cargas de trabajo. En su tiempo desenvuelto, Nadhya disfruta de su pasión por el café y desplazarse.
Nadia Polanco es arquitecto de soluciones en AWS con sede en Bruselas, Bélgica. En este puesto, apoya a las organizaciones que buscan incorporar IA y educación mecánico en sus cargas de trabajo. En su tiempo desenvuelto, Nadhya disfruta de su pasión por el café y desplazarse.
 Brajendra Singh es arquitecto principal de soluciones en Amazon Web Services, donde se asocia con clientes empresariales para diseñar e implementar soluciones innovadoras. Con una sólida experiencia en progreso de software, aporta una profunda experiencia en disección de datos, educación mecánico e IA generativa.
Brajendra Singh es arquitecto principal de soluciones en Amazon Web Services, donde se asocia con clientes empresariales para diseñar e implementar soluciones innovadoras. Con una sólida experiencia en progreso de software, aporta una profunda experiencia en disección de datos, educación mecánico e IA generativa.
