
La orquestación de tuberías de formación mecánico es confuso, especialmente cuando el procesamiento de datos, la capacitación y la implementación abarcan múltiples servicios y herramientas. En esta publicación, caminamos a través de un ejemplo práctico y de extremo a extremo de desarrollar, probar y ejecutar una tubería de formación mecánico (ML) utilizando capacidades de flujo de trabajo en Amazon Sagemakeraccedido a través del Estudio unificado de Amazon Sagemaker experiencia. Estos flujos de trabajo están alimentados por Flujos de trabajo administrados por Amazon para Apache Airflow (Amazon MWAA).
Si aceptablemente Sagemaker Unified Studio incluye un constructor visual para la creación de flujo de trabajo de bajo código, esta piloto se centra en la experiencia del primer código: autorización y gobierno de flujos de trabajo como Dags Airflow Airflow basados en Python (gráficos acíclicos dirigidos). Un DAG es un conjunto de tareas con dependencias definidas, donde cada tarea se ejecuta solo luego de que sus dependencias aguas en lo alto se completen, promoviendo el orden de ejecución correcto y haciendo que su tubería ML sea más reproducible y resistente. Caminaremos a través de una cartera de alimentos que ingieren los datos del clima y el taxi, transforman y se unen a los conjuntos de datos, y usa ML a predicción de Predicte, ya que se realizan un experimentación de gastos de sesgo.
Si prefiere una experiencia más simple y de bajo código, ver Orchestre trabajos de procesamiento de datos, libros de consultas y cuadernos utilizando experiencia en flujo de trabajo visual en Amazon Sagemaker.
Descripción militar de la posibilidad
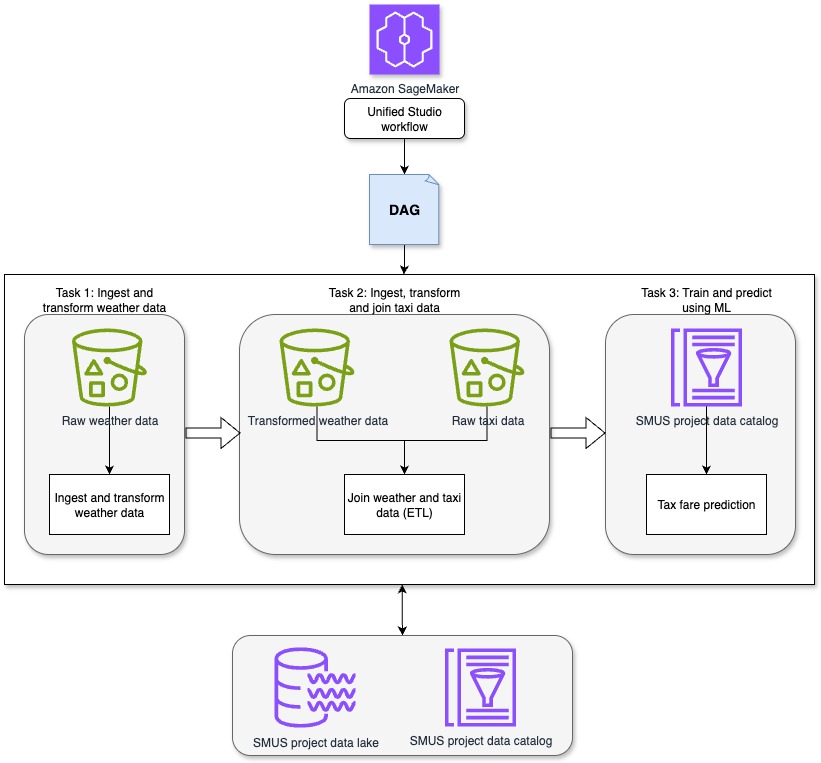
Esta posibilidad demuestra cómo los flujos de trabajo de SageMaker Unified Studio se pueden usar para orquestar una tubería completa de datos a ML en un entorno centralizado. La tubería se ejecuta a través de las siguientes tareas secuenciales, como se muestra en el diagrama precursor.
- Tarea 1: ingerir y metamorfosear datos meteorológicos: Esta tarea utiliza un cuaderno Jupyter en Sagemaker Unified Studio para ingerir y preprocesar datos meteorológicos sintéticos. El conjunto de datos del clima sintético Incluye observaciones por hora con atributos como tiempo, temperatura, precipitación y cobertura de nubes. Para esta tarea, el enfoque está en el tiempo, la temperatura, la profusión, la precipitación y la velocidad del derrota.
- Tarea 2: ingerir, metamorfosear y unir datos de taxi: Un segundo cuaderno de Jupyter en Sagemaker Unified Studio ingiere el Raw Conjunto de datos de viajes en taxi de la ciudad de Nueva York. Este conjunto de datos incluye atributos como el tiempo de recogida, el tiempo de entrega, la distancia de alucinación, el recuento de pasajeros y el monto de la tarifa. Los campos relevantes para esta tarea incluyen el tiempo de recogida y entrega, la distancia de alucinación, el número de pasajeros y el monto total de la tarifa. El cuaderno transforma el conjunto de datos de taxi en preparación para unirlo con los datos meteorológicos. Luego de la transformación, los conjuntos de datos de taxis y clima se unen para crear un conjunto de datos unificado, que luego se escribe en Amazon S3 para uso posterior.
- Tarea 3: Entrena y predice el uso de ML: Un tercer cuaderno de Jupyter en Sagemaker Unified Studio aplica técnicas de regresión al conjunto de datos unido para crear un maniquí para determinar cómo los atributos de los datos del clima y el taxi, como la profusión y la distancia de alucinación, las tarifas de taxi de impacto y crear un maniquí de predicción de tarifas. El maniquí capacitado se utiliza para suscitar predicciones de tarifas para los datos de nuevo alucinación.
Este enfoque unificado permite la orquestación de los pasos de extracto, transformación y carga (ETL) y ML con una visibilidad total en el ciclo de vida de datos y la reproducibilidad a través de flujos de trabajo gobernados en Sagemaker Unified Studio.
Requisitos previos
Antaño de comenzar, complete los siguientes pasos:
- Crear un dominio de estudio unificado de Sagemaker: Sigue las instrucciones en Cree un dominio de estudio unificado de Amazon Sagemaker – Configuración rápida
- Inicie sesión en su dominio de estudio unificado de Sagemaker: Use el dominio que creó en el paso 1 de inicio de sesión. Para obtener más información, consulte Access Amazon Sagemaker Unified Studio.
- Crear un esquema de estudio unificado de Sagemaker: Cree un nuevo esquema en su dominio siguiendo el Consejo de creación de proyectos. Para Perfil de esquemaescoger Todas las capacidades.
Configurar flujos de trabajo
Puede usar flujos de trabajo en Sagemaker Unified Studio para configurar y ejecutar una serie de tareas utilizando Flujo de atmósfera de Apache para diseñar procedimientos de procesamiento de datos y organizar sus libros de consulta, cuadernos y trabajos. Puede crear flujos de trabajo en el código de Python, probarlos y compartirlos con su equipo, y alcanzar a la interfaz de becario de flujo de atmósfera directamente desde Sagemaker Unified Studio. Proporciona características para ver los detalles del flujo de trabajo, incluidos los resultados de ejecución, las completaciones de tareas y los parámetros. Puede ejecutar flujos de trabajo con parámetros predeterminados o personalizados y monitorear su progreso. Ahora que tiene su esquema Sagemaker Unified Studio configurado, puede construir sus flujos de trabajo.
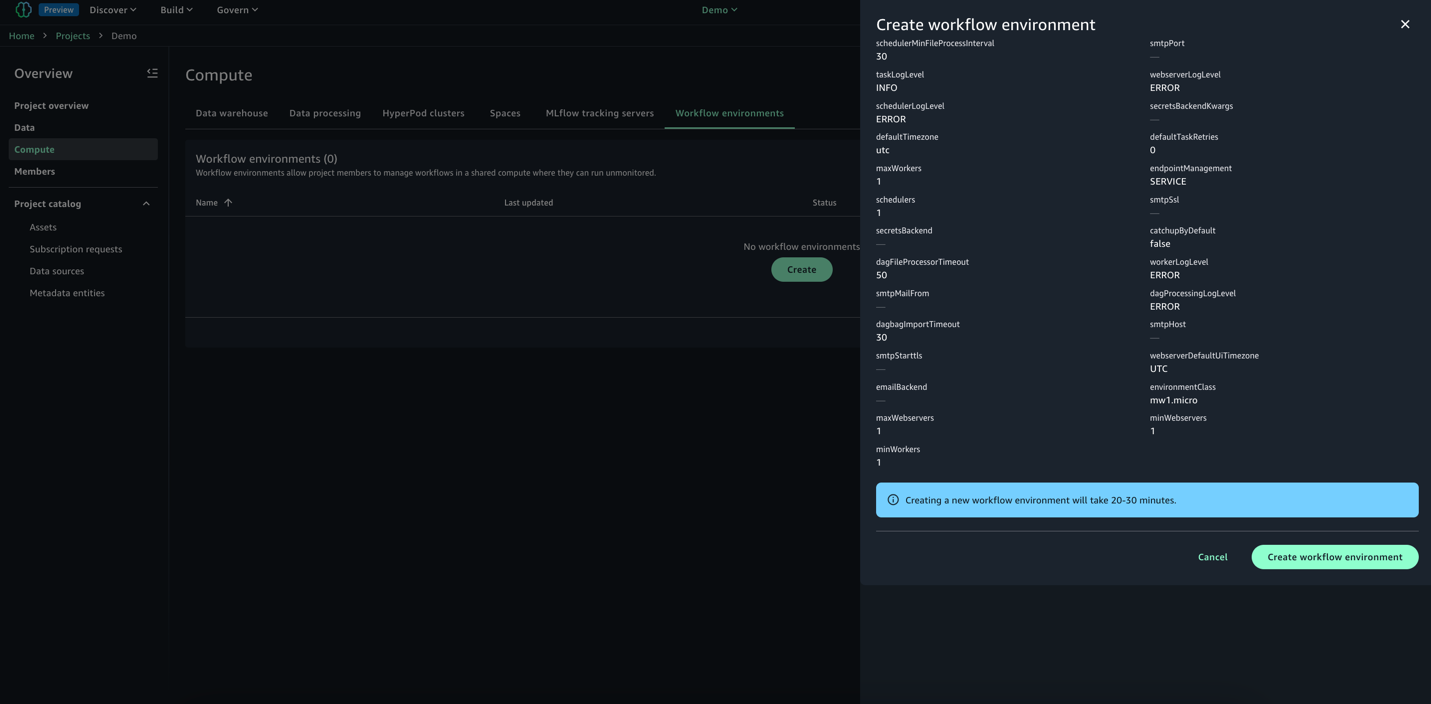
- En su esquema SageMaker Unified Studio, navegue a la sección de cálculo y seleccione Entorno de flujo de trabajo.
- Designar Crear entorno Para configurar un nuevo entorno de flujo de trabajo.
- Revise las opciones y elija Crear entorno. Por defecto, Sagemaker Unified Studio crea un entorno de clase MW1.Micro, que es adecuado para pruebas y flujos de trabajo a pequeña escalera. Para renovar la clase de entorno ayer de la creación del esquema, navegue a Dominio y escoger esquema Perfiles y luego Todas las capacidades y ir a Despliegue de BluePrint de flujos de trabajo de OnDemand ajustes. Al utilizar estas configuraciones, puede anular los parámetros predeterminados y adaptar el entorno a los requisitos específicos del esquema.
Desarrollar flujos de trabajo
Puede usar flujos de trabajo para orquestar cuadernos, libros de consultas y más en los repositorios de su esquema. Con los flujos de trabajo, puede puntualizar una colección de tareas organizadas como un DAG que puede ejecutarse en un horario definido por el becario. Para comenzar:
- Descargar Ingestión de datos meteorológicos, Ingesta de taxi y unirse al climay Predicción cuadernos a su entorno regional.
- Ir a Construir y escoger Jupyterlab; designar Cargar archivos e valía los tres cuadernos que descargó en el paso precursor.
- Configure su Sagemaker Unified Studio Space: Los espacios se utilizan para tener la llave de la despensa las deposición de almacenamiento y capital de la aplicación relevante. Para esta demostración, configure el espacio con una instancia de ML.M5.8xLarge
- Designar Configurar espacio En la cumbre derecha y detén el espacio.
- Modernizar el tipo de instancia a ml.m5.8xLarge Y comienza el espacio. Cualquier proceso activo se detendrá durante el reinicio, y se perderán cualquier cambio no cáscara. La puesta al día del espacio de trabajo puede tardar unos minutos.
- Ir a Construir y escoger Orquestación y luego Flujos de trabajo.
- Seleccione la flecha cerca de debajo (▼) al flanco de Crear un nuevo flujo de trabajo. En el menú desplegable que aparece, seleccione Crear en el editor de códigos.
- En el editor, cree un nuevo archivo de Python llamado
multinotebook_dag.pybajosrc/workflows/dags. Copie el sucesivo código DAG, que implementa una tubería ML secuencial que orquestina múltiples cuadernos en Sagemaker Unified Studio. ReemplazarNOTEBOOK_PATHSpara que coincida con sus ubicaciones reales de cuaderno.
El código utiliza el cámara de cuaderno para ejecutar tres cuadernos en orden: ingestión de datos para datos meteorológicos, ingestión de datos para datos de taxi y el maniquí capacitado creado al combinar los datos del clima y el taxi. Cada cuaderno se ejecuta como una tarea separada, con dependencias para ayudar a asegurar que se ejecuten en secuencia. Puede personalizar con sus propios cuadernos. Puedes modificar el NOTEBOOK_PATHS Repertorio para orquestar cualquier número de cuadernos en su flujo de trabajo mientras mantiene el orden de ejecución secuencial.
El horario de flujo de trabajo se puede personalizar actualizando WORKFLOW_SCHEDULE (Por ejemplo: '@hourly', '@weekly'o expresiones cron como ‘13 2 1 * *’) para que coincida con sus deposición comerciales específicas.
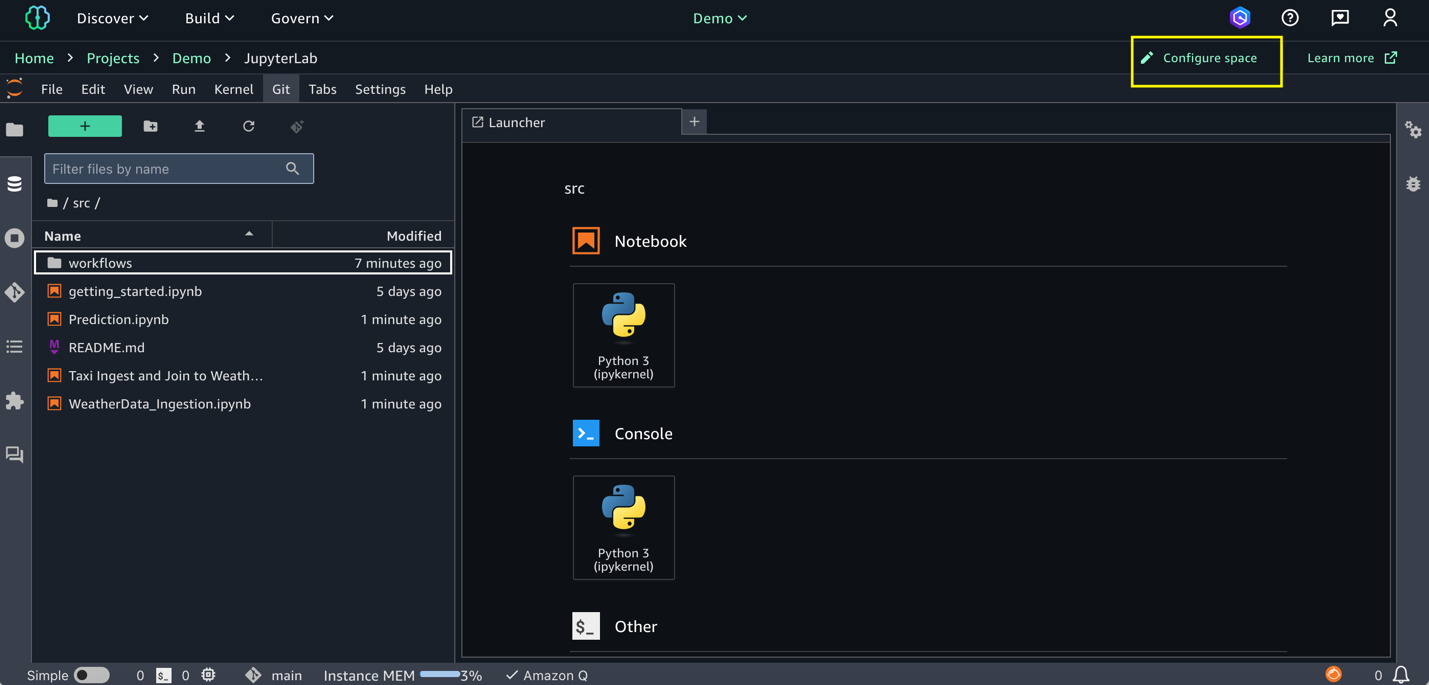
- Luego de que el propietario de un esquema haya creado un entorno de flujo de trabajo, y una vez que haya guardado sus archivos DAG de flujos de trabajo en Jupyterlab, se sincronizan automáticamente al esquema. Luego de sincronizar los archivos, todos los miembros del esquema pueden ver los flujos de trabajo que ha complemento en el entorno de flujo de trabajo. Ver Comparta un flujo de trabajo de código con otros miembros del esquema en un entorno de flujo de trabajo unificado de Amazon Sagemaker Unified.
Pruebe y monitoree la ejecución del flujo de trabajo
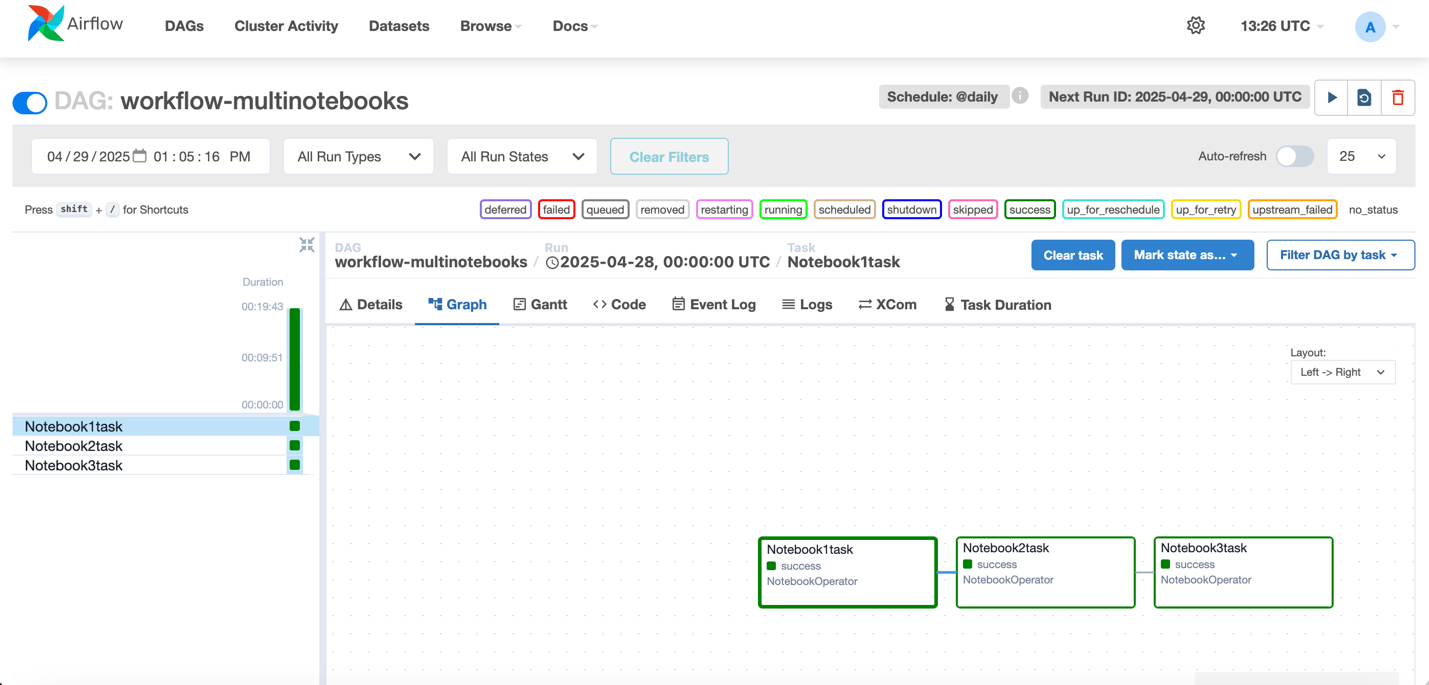
- Para validar su DAG, vaya a Build> Orchestration> Flujos de trabajo. Ahora debería ver el flujo de trabajo que se ejecuta en el espacio regional en función del horario.
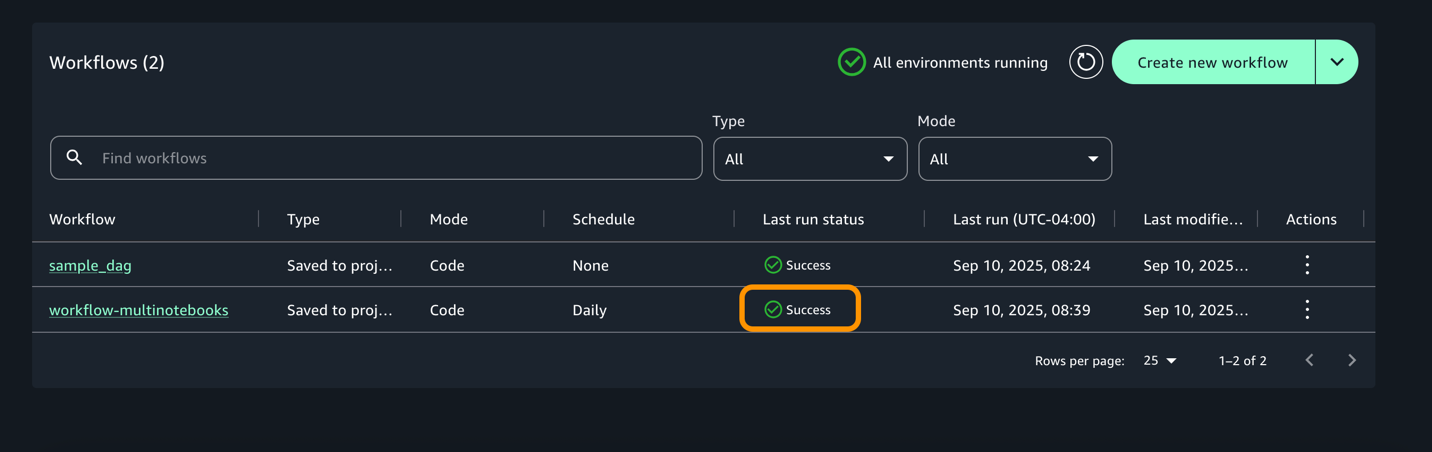
- Una vez que se completa la ejecución, el flujo de trabajo cambiaría al inicio del éxito como se muestra a continuación.
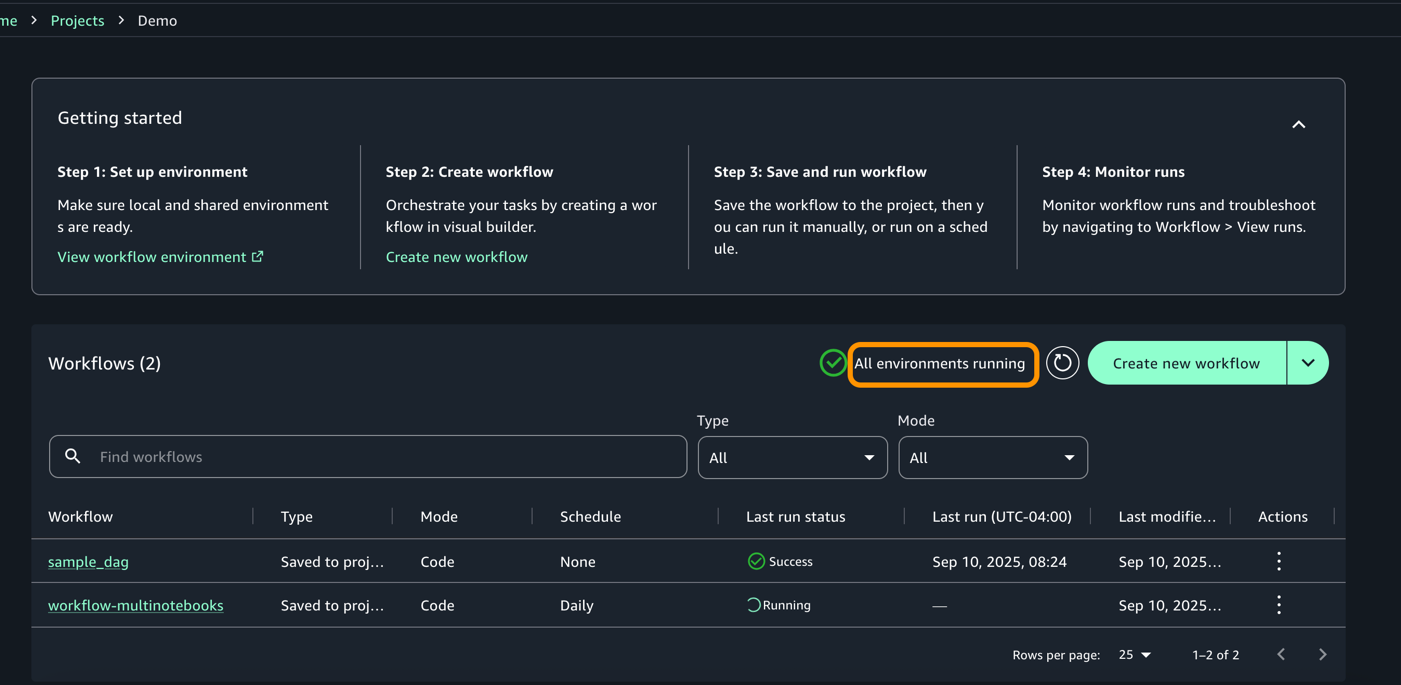
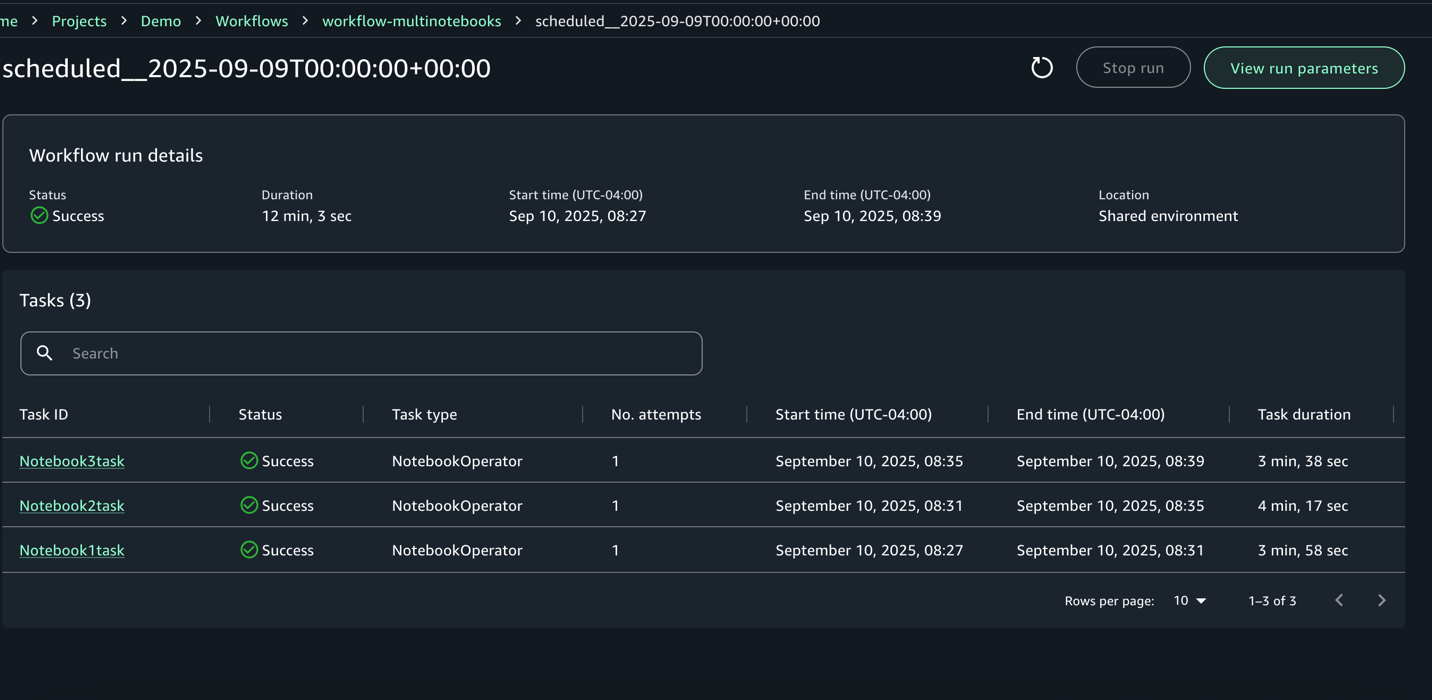
- Para cada ejecución, puede acercarse para obtener un detalle detallado de flujo de trabajo y registros de tareas
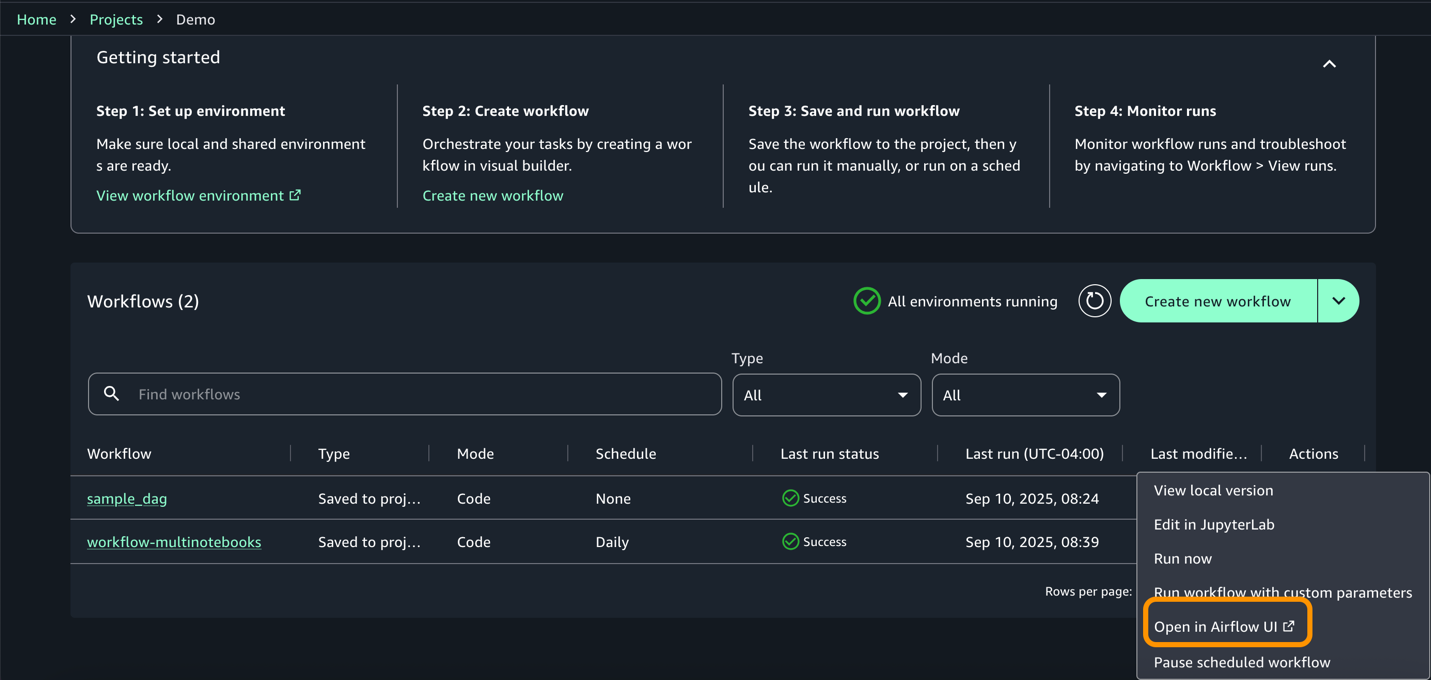
- Acceda a la interfaz de becario de flujo de atmósfera desde acciones para obtener más información sobre el DAG y la ejecución.
Resultados
La salida del maniquí se escribe en el Amazon Simple Storage Service (Amazon S3) Carpeta de salida como se muestra la sucesivo figura. Estos resultados deben evaluarse para determinar la corrección del ajuste, la precisión de la predicción y la consistencia de las relaciones entre las variables. Si algún resultado parece inesperado o poco claro, es importante revisar los datos, los pasos de ingeniería y los supuestos del maniquí para demostrar que se alineen con el caso de uso previsto.
Barrer
Para evitar incurrir en cargos adicionales asociados con los capital creados como parte de esta publicación, asegúrese de eliminar los rudimentos creados en la cuenta de AWS para esta publicación.
- El dominio de Sagemaker
- El cubo S3 asociado con el dominio de Sagemaker
Conclusión
En esta publicación, demostramos cómo puede usar Amazon Sagemaker para construir flujos de trabajo ML potentes e integrados que abarcan los datos completos y el ciclo de vida de AI/ML. Aprendió cómo crear un esquema de estudio unificado de Amazon Sagemaker, usar un cuaderno de múltiples competencias para procesar datos y usar el editor SQL incorporado para explorar y visualizar los resultados. Finalmente, le mostramos cómo orquestar todo el flujo de trabajo en el interior de la interfaz SageMaker Unified Studio.
Sagemaker ofrece un conjunto integral de capacidades para que los profesionales de los datos realicen tareas de extremo a extremo, incluida la preparación de datos, la capacitación de modelos y el expansión generativo de aplicaciones de IA. Cuando se accede a través de Sagemaker Unified Studio, estas capacidades se unen en un solo espacio de trabajo centralizado que ayuda a eliminar la fricción de las herramientas, servicios y artefactos aislados.
A medida que las organizaciones construyen aplicaciones cada vez más complejas basadas en datos, los equipos pueden usar Sagemaker, pegado con Sagemaker Unified Studio, para colaborar de modo más efectiva y operacionalizar sus activos AI/ML con confianza. Puede descubrir sus datos, construir modelos y orquestar flujos de trabajo en un entorno único y gobernado.
Para obtener más información, visite el Estudio unificado de Amazon Sagemaker página.
Sobre los autores