
Las organizaciones a menudo luchan por igualar sus ecosistemas de datos en múltiples plataformas y servicios. La conectividad entre Amazon Sagemaker y Abundancia de datos de IA de copas de cocaína Ofrece una poderosa alternativa a este desafío, por lo que las empresas pueden usar las fortalezas de uno y otro entornos mientras mantienen una táctica de datos cohesivos.
En esta publicación, demostramos cómo puede desglosar los silos de datos y mejorar sus capacidades analíticas consultando las tablas de iceberg Apache en el Lakehouse Architecture of Sagemaker directamente del copo de cocaína. Con esta capacidad, puede ceder y analizar los datos almacenados en Servicio de almacenamiento simple de Amazon (Amazon S3) a través de Catálogo de datos de pegamento AWS usando un Punto final de alivio de iceberg de pegamento awstodos asegurados por Formación del estanque AWSsin la requisito de procesos complejos de extracto, transformación y carga (ETL) o duplicación de datos. Incluso puede automatizar el descubrimiento de la tabla y refrescar utilizando Bases de datos vinculadas al catálogo de copas de cocaína para iceberg. En las siguientes secciones, mostramos cómo configurar esta integración para que los usuarios de copos de cocaína puedan consultar y analizar sin problemas los datos almacenados en AWS, mejorando así la accesibilidad de los datos, reduciendo la exceso y permitiendo disección más completos en todo su ecosistema de datos.
Casos de uso comercial y beneficios esencia
La capacidad de consultar las mesas de iceberg en Sagemaker de Snowflake ofrece un valencia significativo en múltiples industrias:
- Servicios financieros – Mejorar la detección de fraude a través del disección unificado de datos de transacciones y patrones de comportamiento del cliente
- Cuidado de la vitalidad – Mejorar los resultados de los pacientes a través del ataque integrado a los datos clínicos, de reclamos y de investigación
- Minorista – Aumentar las tasas de retención del cliente conectando datos de ventas, inventario y comportamiento del cliente para experiencias personalizadas
- Fabricación – Impulse la eficiencia de producción a través de un disección unificado y disección de datos operativos
- Telecomunicaciones – Reduzca la rotación de clientes con disección integral del rendimiento de la red y los datos de uso del cliente
Los beneficios esencia de esta capacidad incluyen:
- Toma de decisiones acelerada – Reduzca el tiempo para obtener información a través del ataque a datos integrados en todas las plataformas
- Optimización de costos – Acelere el tiempo de información al consultar los datos directamente en almacenamiento sin la requisito de ingestión
- Fidelidad de datos mejorada – Reduzca las inconsistencias de datos estableciendo una sola fuente de verdad
- Colaboración mejorada -Aumentar la productividad interfuncional a través del intercambio de datos simplificado entre científicos de datos y analistas
Al utilizar la casa Lakehouse de Sagemaker con el poder computacional sin servidor de Snowflake y sintonizando cero, puede desglosar los silos de datos, permitiendo disección integrales y democratizando el ataque a los datos. Esta integración admite una casa de datos moderna que prioriza la flexibilidad, la seguridad y el rendimiento analítico, que en última instancia conduce la toma de decisiones más rápida y más informada en toda la empresa.
Descripción normal de la alternativa
El subsiguiente diagrama muestra la casa para la integración del catálogo entre el copo de cocaína y las mesas de iceberg en Lakehouse.
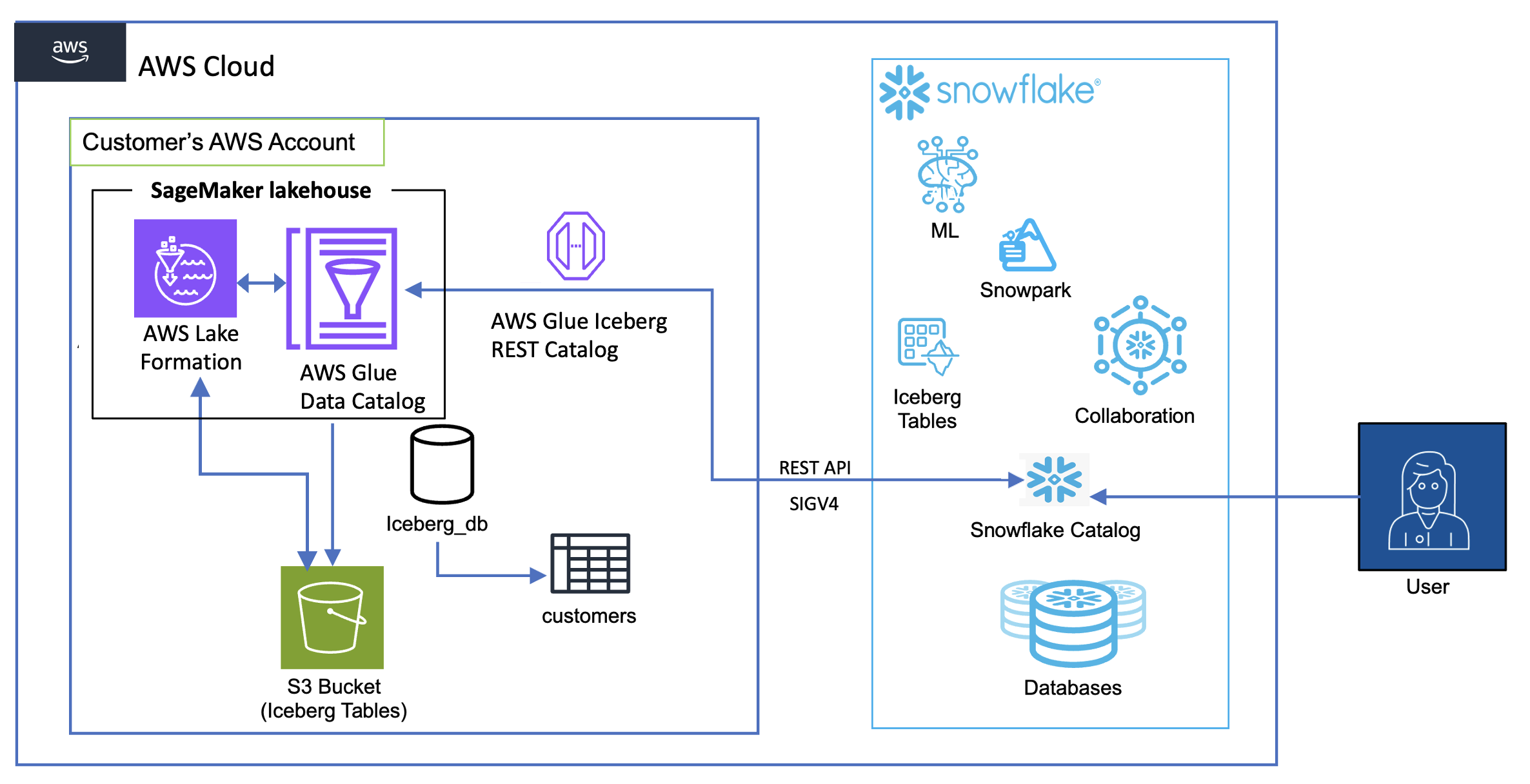
El flujo de trabajo consta de los siguientes componentes:
- Almacenamiento y administración de datos:
- Amazon S3 sirve como la capa de almacenamiento principal, alojando los datos de la tabla de iceberg
- El catálogo de datos mantiene los metadatos para estas tablas
- La formación de estanque proporciona una traspaso de credenciales
- Flujo de autenticación:
- Snowflake inicia consultas utilizando una configuración de integración de catálogo
- La formación del estanque venga credenciales temporales a través de Servicio de token de seguridad de AWS (AWS STS)
- Estas credenciales se actualizan automáticamente en función del intervalo de modernización configurado
- Flujo de consulta:
- Los usuarios de copas de cocaína envían consultas contra las mesas de iceberg montadas
- El punto final de reposo de iceberg de AWS Glue procesa estas solicitudes
- La ejecución de la consulta utiliza los fortuna de cuenta de Snowflake mientras lee directamente de Amazon S3
- Los resultados se devuelven a los usuarios de copos de cocaína mientras mantienen todos los controles de seguridad
Hay cuatro patrones para consultar las mesas de iceberg en Sagemaker de Snowflake:
- Mesas de iceberg en un cubo S3 utilizando un punto final de alivio de iceberg de pegamento AWS Integración de catálogo de REST de iceberg de copas de cocaína, con credenciales para la formación del estanque
- Mesas de iceberg en un cubo S3 utilizando un punto final de alivio de iceberg de pegamento AWS Integración de catálogo de REST de iceberg de copo de cocaína, utilizando volúmenes externos de copo de cocaína para el almacenamiento de datos de Amazon S3
- Tablas de iceberg en un cubo S3 utilizando la integración del catálogo de la AWS Glue API, todavía utilizando volúmenes externos de copo de cocaína para Amazon S3
- Tablas de Amazon S3 utilizando la integración del catálogo de REST de iceberg con la traspaso de credenciales de la formación del estanque
En esta publicación, implementamos el primero de estos cuatro patrones de ataque utilizando integración del catálogo para el punto final de alivio de iceberg de pegamento AWS con Lectura de firma 4 (SIGV4) autenticación en copos de cocaína.
Requisitos previos
Debes tener los siguientes requisitos previos:
La alternativa tarda aproximadamente 30-45 minutos en configurar. El costo varía según el barriguita de datos y la frecuencia de consulta. Usar el Calculadora de precios de AWS para estimaciones específicas.
Crea un papel de IAM para el copero de cocaína
Para crear un papel de IAM para Snowflake, primero crea una política para el papel:
- En la consola IAM, elija Políticas En el panel de navegación.
- Designar Crear política.
- Elija el editor JSON e ingrese la subsiguiente política (proporcione su región de AWS e ID de cuenta), luego elija Próximo.
- Ingresar
iceberg-table-accesscomo el nombre de la política. - Designar Crear política.
Ahora puede crear el rol y adjuntar la política que creó.
- Designar Roles En el panel de navegación.
- Designar Crear rol.
- Designar Cuenta de AWS.
- Bajo Opciónoptar Requerir ID foráneo e ingrese una identificación externa de su votación.
- Designar Próximo.
- Elija la política que creó (
iceberg-table-access policy). - Ingresar
snowflake_access_rolecomo el nombre de rol. - Designar Crear rol.
Configurar controles de ataque de formación de estanque
Para configurar los controles de ataque de la formación de su estanque, primero configure la integración de la aplicación:
- Inicie sesión en la consola de formación del estanque como administrador de Data Lake.
- Designar Distribución En el panel de navegación.
- Inclinarse Configuración de integración de aplicaciones.
- Permitir Permitir que los motores externos accedan a los datos en las ubicaciones de Amazon S3 con ataque completo a la tabla.
- Designar Racionar.
Ahora puede otorgar permisos al papel de IAM.
- Designar Permisos de datos En el panel de navegación.
- Designar Conceder.
- Configurar la subsiguiente configuración:
- Para Directoresoptar Usuarios y roles de IAM y designar
snowflake_access_role. - Para Capitaloptar Capital de catálogo de datos con nombre.
- Para Catalogarelija su ID de cuenta de AWS.
- Para Cojín de datosdesignar
iceberg_db. - Para Mesadesignar
customer. - Para Permisosoptar SÚPER.
- Para Directoresoptar Usuarios y roles de IAM y designar
- Designar Conceder.
Se requiere un súper ataque para aparearse la mesa iceberg en Amazon S3 como una mesa de copos de cocaína.
Registre la ubicación de S3 Data Lake
Complete los siguientes pasos para registrar la ubicación de S3 Data Lake:
- Como administrador del estanque de datos en la consola de formación del estanque, elija Ubicaciones del estanque de datos En el panel de navegación.
- Designar Ubicación de registro.
- Configurar lo subsiguiente:
- Para S3 Caminoingrese la ruta S3 al cubo donde almacenará sus datos.
- Para Papel de iamdesignar
LakeFormationLocationRegistrationRole. - Para Modo de permisodesignar Formación del estanque.
- Designar Ubicación de registro.
Establezca la integración de alivio iceberg en copos de cocaína
Complete los siguientes pasos para configurar la integración de alivio iceberg en copos de cocaína:
- Inicie sesión en Snowflake como usufructuario administrador.
- Ejecute el subsiguiente comando SQL (proporcione su región, ID de cuenta e ID externa que proporcionó durante la creación de roles de IAM):
- Ejecutar el subsiguiente comando sql y recuperar el valencia para
API_AWS_IAM_USER_ARN:
DESCRIBE CATALOG INTEGRATION glue_irc_catalog_int;
- En la consola IAM, actualice la relación de confianza para
snowflake_access_rolecon el valencia paraAPI_AWS_IAM_USER_ARN:
- Verifique la integración del catálogo:
SELECT SYSTEM$VERIFY_CATALOG_INTEGRATION('glue_irc_catalog_int');
- Monte la mesa S3 como una mesa de copos de cocaína:
Consulta la mesa del iceberg desde el copero de cocaína
Para probar la configuración, inicie sesión en Snowflake como usufructuario oficinista y ejecute la subsiguiente consulta de muestra:SELECT * FROM s3iceberg_customer LIMIT 10;
Estafar
Para estafar sus fortuna, complete los siguientes pasos:
- Elimine la colchoneta de datos y la tabla en AWS Glue.
- Deje caer la mesa iceberg, la integración del catálogo y la colchoneta de datos en copos de cocaína:
Asegúrese de que todos los fortuna se limpien adecuadamente para evitar cargos inesperados.
Conclusión
En esta publicación, demostramos cómo establecer una conexión segura y valioso entre su entorno de copo de cocaína y Sagemaker para consultar las mesas de iceberg en Amazon S3. Esta capacidad puede ayudar a su estructura a apoyar una sola fuente de verdad al tiempo que permite a los equipos usar sus herramientas de disección preferidas, en última instancia, desglosando los silos de datos y mejorando las capacidades de disección colaborativo.
Para explorar e implementar más a fondo esta alternativa en su entorno, considere los siguientes fortuna:
- Documentación técnica:
- Publicaciones de blog relacionadas:
Estos fortuna pueden ayudarlo a implementar y optimizar este patrón de integración para su caso de uso específico. Al comenzar este delirio, recuerde comenzar a poco, validar su casa con datos de prueba y medrar gradualmente su implementación en función de las micción de su estructura.
Sobre los autores