
Mayoría Proyectos de IA Comience con una tarea molesta: lustrar archivos desordenados. Los archivos PDF, documentos de Word, PPT, imágenes, audio y hojas de cálculo deben convertirse en texto honrado ayer de que sean bártulos. MarkItDown de Microsoft finalmente soluciona este problema. En esta conductor, le mostraré cómo instalarlo, convertir todos los tipos de archivos principales a Markdown, ejecutar OCR en imágenes, transcribir audio, extraer contenido de archivos ZIP y crear canales más limpios para sus flujos de trabajo LLM con solo unas pocas líneas de código.
¿Por qué es importante MarkItDown?
Antiguamente de tener lugar a los ejemplos prácticos, es útil comprender cómo MarkItDown efectivamente convierte diferentes archivos en Markdown honrado. La biblioteca no comercio todos los formatos por igual. En cambio, utiliza un proceso inteligente de dos pasos.
Primero, cada tipo de archivo se analiza con la aparejo más adecuada para él. Los documentos de Word pasan por mamut, las hojas de Excel por pandas y las diapositivas de PowerPoint por python-pptx. Todos ellos se convierten en HTML estructurado.
En segundo oportunidad, ese HTML se limpia y se transforma en Markdown utilizando BeautifulSoup. Esto garantiza que el resultado final mantenga intactos los títulos, listas, tablas y estructura dialéctica.
Puede pegar la imagen aquí para aclarar el flujo:
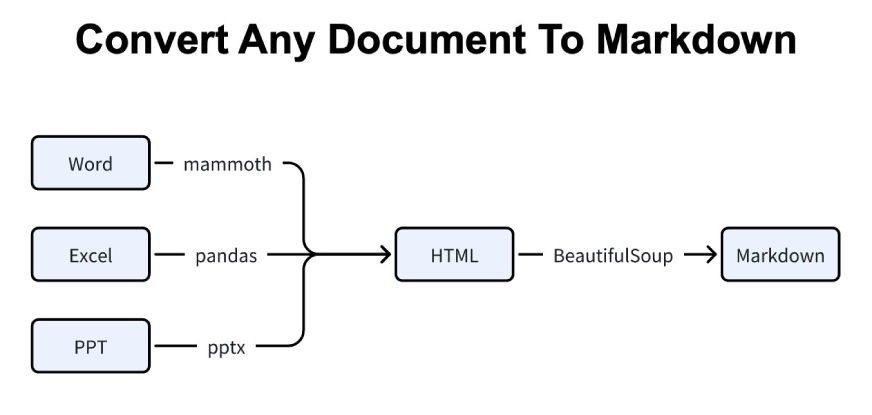
MarkItDown sigue este proceso cada vez que ejecuta una conversión, independientemente de cuán difícil esté el documento innovador.
Lea más sobre esto en nuestro artículo antecedente sobre ¿Cómo utilizar MarkItDown MCP para convertir los documentos en Markdowns?
Instalación y configuración de MarkItDown de Microsoft
Para comenzar, se requiere un entorno Python y pip. Incluso necesitará una secreto API AI abierta en caso de que desee procesar imágenes o audio.
En cualquier terminal, el subsiguiente comando instalará la biblioteca MarkItDown Python:
!pip install markitdown(all) Es mejor establecer un entorno potencial para evitar conflictos con otros proyectos.
# Create a potencial environment
python -m venv venv
# Activate it (Windows)
venvScriptsactivate
# Activate it (Mac/Linux)
source venv/bin/activate Luego de la instalación, valor la biblioteca en Python para probarla. Ahora estás perspicaz para convertir archivos a Markdown
8 cosas que hacer con la biblioteca MarkItDown de Microsoft
MarkItDown admite la mayoría de los formatos. Estos son los ejemplos de su uso en archivos comunes.
Tarea 1: convertir documentos de MS Word
Los documentos de Word suelen incluir encabezados, texto en negrita y listas. MarkItDown conserva este formato durante la conversión.
from markitdown import MarkItDown
md = MarkItDown()
res = md.convert("/content/test-sample.docx")
print(res.text_content) Producción:
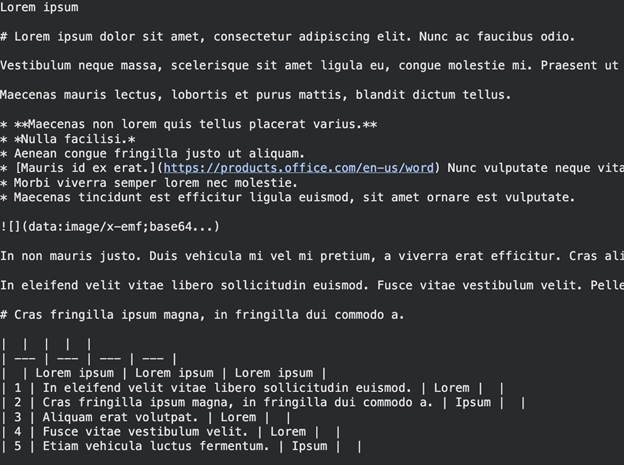
Encontrará el texto Markdown. Los encabezados están delimitados por las trivio # y las listas por *. Esta forma de estructura ayuda a los LLM a comprender la estructura de su artículo.
Los analistas de datos requieren periódicamente datos de Excel. Es una aparejo de conversión de documentos que puede convertir hojas de cálculo en tablas Markdown limpias.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/file_example_XLS_10.xls")
print(result.text_content) Producción:
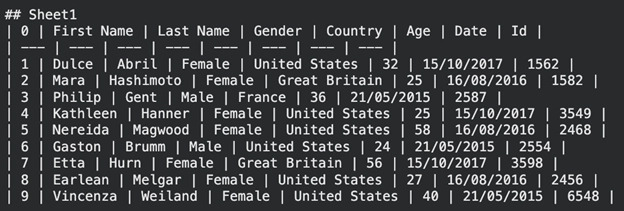
La información se presenta en forma de tabla Markdown. Este formato no es difícil de interpretar tanto para los humanos como para los modelos de IA.
Tarea 3: convertir diapositivas de PowerPoint en Markdown honrado
Las cubiertas de diapositivas contienen resúmenes bártulos. Este texto se puede extraer para crear datos que se utilizarán en tareas de epítome de LLM.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/file-sample.pptx")
print(result.text_content) Producción:
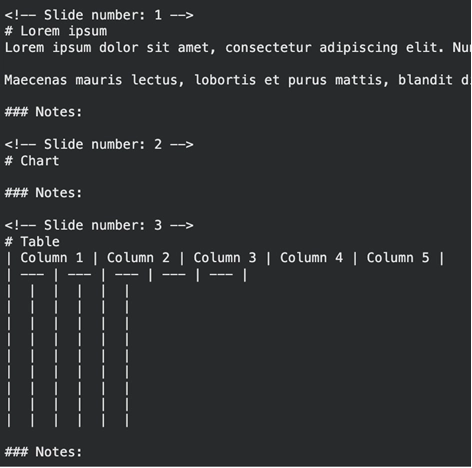
La aparejo captura viñetas y títulos de diapositivas, separados por número de diapositiva. Ignora las complicadas funciones de diseño que hacen que los analizadores de texto se pierdan.
Tarea 4: analizar archivos PDF en Markdown estructurado
El PDF es increíblemente difícil de decodificar. MarkItDown facilita este proceso.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/1706.03762.pdf")
print(result.text_content) Producción:
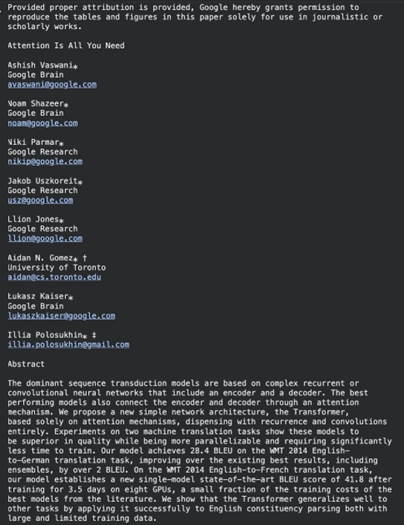
Extrae el texto con el formato, por secciones. La biblioteca incluso se puede combinar con herramientas de OCR cuando se utilizan archivos PDF complejos de documentos escaneados.
Tarea 5: ocasionar texto a partir de imágenes mediante OCR
La biblioteca MarkItDown Python puede describir imágenes en caso de que las relacione con un LLM multimodal. Esto implica un acuerdo con un cliente LLC.
from markitdown import MarkItDown
from openai import OpenAI
from google.colab import userdata
client = OpenAI(api_key=userdata.get('OPENAI_KEY'))
md = MarkItDown(llm_client=client, llm_model="gpt-4o-mini")
result = md.convert("/content/Screenshot 2025-12-03 at 5.46.29 PM.png")
print(result.text_content) Producción:

El maniquí producirá un título o texto descriptivo que sea visible en la imagen.
Tarea 6: transcribir archivos de audio a Markdown
Incluso puedes convertir archivos de audio en texto. Tiene esta característica mediante transcripción de voz.
from markitdown import MarkItDown
from openai import OpenAI
md = MarkItDown(llm_client=client, llm_model="gpt-4o-mini")
result = md.convert("/content/speech.mp3")
print(result.text_content) Producción:

Una transcripción de texto del archivo de audio en formato Markdown.
Tarea 7: Procesar varios archivos interiormente de archivos ZIP
MarkItDown puede manejar archivos completos simultáneamente, en caso de que tenga un archivo ZIP de documentos.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/test-sample.zip")
print(result.text_content) Producción:
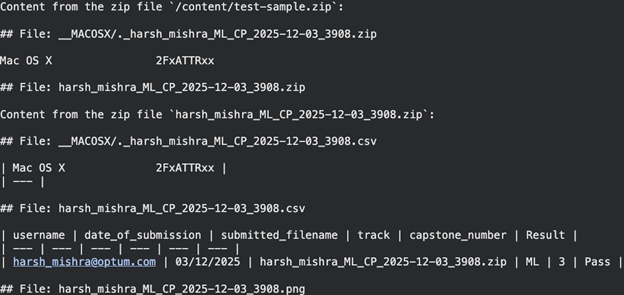
La aplicación unifica el contenido de todos los archivos compatibles interiormente de un ZIP en una única salida Markdown. Incluso extrae el contenido del archivo CSV y lo convierte en Markdown.
Tarea 8: Manejo de HTML y formatos basados en texto
Las páginas web y los archivos de datos como CSV son fáciles de convertir a Markdown.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/sample1.html")
print(result.text_content) Producción:
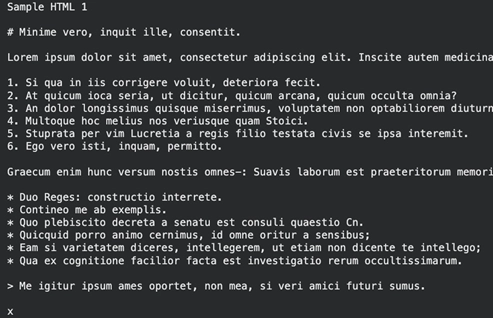
Procese varios archivos interiormente de archivos ZIP
Markdown honrado que conserva enlaces y encabezados del HTML.
Consejos avanzados y opción de problemas
Tenga en cuenta los siguientes consejos para obtener los mejores resultados de esta aparejo de conversión de documentos:
Seleccione 77 palabras más para ejecutar Humanizer.
- Optimización de la salida: El indicador -o se puede utilizar en la camino de comando para asegurar en un archivo.
- Archivos grandes: El procesamiento de archivos grandes puede sobrellevar mucho tiempo. Asegúrese de que su máquina tenga suficiente capacidad de memoria.
- Errores de API: Esencia API y problema de Internet: en caso de problemas con la conversión de imagen/audio, verifique la secreto API y la conexión a Internet.
- Formatos admitidos: Capture una descompostura: revise la página de problemas de GitHub. La sociedad está comprometida y solidaria.
Yendo más allá: construyendo un canal de IA
MarkItDown actúa como una colchoneta sólida para los flujos de trabajo de IA. Puede integrarlo con herramientas como LangChain para crear potentes aplicaciones de inteligencia sintético. Los datos de incorporación calidad son importantes en la formación de LLM. Las herramientas de código amplio de Microsoft le ayudan a sustentar datos de entrada limpios, lo que genera respuestas de IA más precisas y confiables.
Conclusión
La biblioteca MarkItDown Python es un gran avance en la preparación de datos. Le permite convertir archivos a Markdown con el pequeño esfuerzo. Procesa textos simples a multimedia. Las herramientas de código amplio de Microsoft incluso mejoran la experiencia de los desarrolladores. Esta es una aparejo de conversión de documentos que debe estar en su kit de herramientas en caso de que trabaje con LLM. Pruebe los ejemplos anteriores. Únase a la comunidad en GitHub. Datos lógicamente listos para los flujos de trabajo de LLM en el pequeño tiempo posible.
Preguntas frecuentes
R. Sí. Microsoft la mantiene como una biblioteca de código amplio y puedes instalarla graciosamente con pip.
R. Admite mejor archivos PDF textuales, pero es capaz de trabajar con imágenes escaneadas siempre que lo configure con un cliente LLM para realizar OCR.
R. No. MarkItDown requiere una secreto API solo para conversiones de imágenes y audio. Convierte archivos basados en texto localmente sin ninguna secreto API.
R. Instalar la biblioteca incluso significa una aparejo de camino de comandos habitable para insertar conversiones rápidas de archivos.
R. Puede asilar PDF, Docx, PPTX, XLSX, imágenes, audio, HTML, CSV, JSON, ZIP y URL de YouTube.
Harsh Mishra es un ingeniero de IA/ML que pasa más tiempo hablando con modelos de idioma grandes que con humanos reales. Apasionado por GenAI, PNL y hacer que las máquinas sean más inteligentes (para que no lo reemplacen todavía). Cuando no optimiza modelos, probablemente esté optimizando su consumo de café. 🚀☕
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.